Spring Data JPA + QueryDSL: Taking the Best From Both Worlds

You can find the full project on GitHub using this link. There is a simple SpringBoot application with configured MySQL data source and initial database structure described as a Flyway migration.
Here we will concentrate only on the building persistence layer. As we deal with the relational database we will rely on the JPA specification. Let’s take a simple entity model like Author/Book as an example:
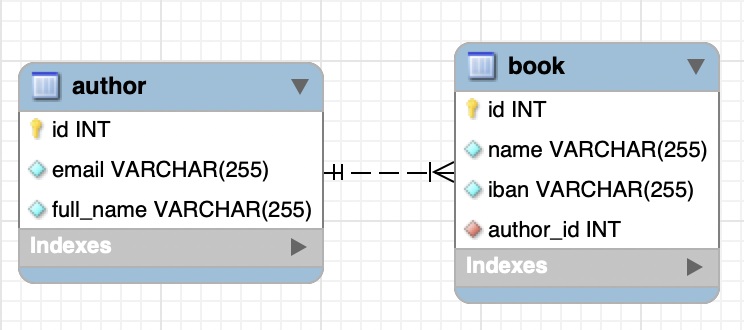
package com.example.entity;
import lombok.Getter;
import lombok.Setter;
import lombok.ToString;
import lombok.experimental.Accessors;
import javax.persistence.*;
import java.util.HashSet;
import java.util.Objects;
import java.util.Set;
(chain = true)
(onlyExplicitlyIncluded = true)
public class Author {
.Include
(strategy = GenerationType.IDENTITY)
private Long id;
.Include
private String email;
.Include
private String fullName;
(mappedBy = "author")
private Set<Book> books = new HashSet<>();
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Author author = (Author) o;
return Objects.equals(email, author.email);
}
public int hashCode() {
return Objects.hash(email);
}
}
xxxxxxxxxx
package com.example.entity;
import lombok.Getter;
import lombok.Setter;
import lombok.ToString;
import lombok.experimental.Accessors;
import javax.persistence.*;
import java.util.Objects;
(chain = true)
(onlyExplicitlyIncluded = true)
public class Book {
.Include
(strategy = GenerationType.IDENTITY)
private Long id;
.Include
private String name;
.Include
private String iban;
(fetch = FetchType.LAZY)
(name = "author_id")
private Author author;
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Book book = (Book) o;
return Objects.equals(iban, book.iban);
}
public int hashCode() {
return iban != null ? iban.hashCode() : 0;
}
}
Here we are using Lombok to reduce boilerplate code in the mapping.
Starting Repositories
Now let's create our repositories for the entities:
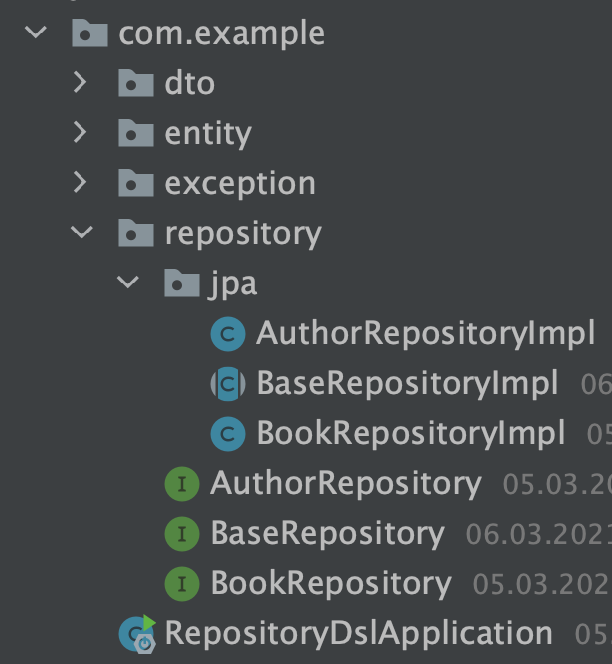
First of all, we will introduce the BaseRepository interface and extend the Spring Data JPA interface JpaRepository:
xxxxxxxxxx
package com.example.repository;
import com.example.exception.DbResultNotFoundException;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.repository.NoRepositoryBean;
public interface BaseRepository<T, ID> extends JpaRepository<T, ID> {
T findByIdMandatory(ID id) throws DbResultNotFoundException;
void clear();
void detach(T entity);
}
Here we can add any methods from the JPA specification that are absent in the Spring Data JpaRepository class. Also, I find method findByIdMandatory super-useful as I expect (in most cases) the entity to be present in the DB in case of searching by ID.
Take a note that we marked the interface as @NoRepositoryBean for disabling the automatic method implementation feature of the Spring Data (this will also work for all child interfaces as we did not enable @EnableJpaRepositories annotation explicitly in the application).
Then the entity repository interfaces look as follows:
xxxxxxxxxx
package com.example.repository;
import com.example.entity.Book;
public interface BookRepository extends BaseRepository<Book, Long> {
}
Implementation
Now it is time to look at the implementation.
Let's start with the BaseRepositoryImpl class:
xxxxxxxxxx
package com.example.repository.jpa;
import com.example.entity.QAuthor;
import com.example.entity.QBook;
import com.example.exception.DbResultNotFoundException;
import com.example.repository.BaseRepository;
import com.querydsl.jpa.impl.JPAQueryFactory;
import org.springframework.data.jpa.repository.support.SimpleJpaRepository;
import javax.persistence.EntityManager;
public abstract class BaseRepositoryImpl<T, ID> extends SimpleJpaRepository<T, ID> implements BaseRepository<T, ID> {
protected final QAuthor author = QAuthor.author;
protected final QBook book = QBook.book;
private final EntityManager em;
protected final JPAQueryFactory queryFactory;
public BaseRepositoryImpl(Class<T> domainClass, EntityManager em) {
super(domainClass, em);
this.em = em;
this.queryFactory = new JPAQueryFactory(em);
}
public T findByIdMandatory(ID id) throws DbResultNotFoundException {
return findById(id)
.orElseThrow(() -> {
String errorMessage = String.format("Entity [%s] with id [%s] was not found in DB", getDomainClass().getSimpleName(), id);
return new DbResultNotFoundException(errorMessage);
});
}
public void clear() {
em.clear();
}
public void detach(T entity) {
em.detach(entity);
}
}
Here is an extension of the Spring Data JPA implementation SimpleJpaRepository that gives us all CRUD operations + our own custom operations (like findByIdMandatory).
You can notice a few lines of code that do not belong to the Spring Data packages:
x
------------------------------------------------
protected final QAuthor author = QAuthor.author;
protected final QBook book = QBook.book;
------------------------------------------------
this.queryFactory = new JPAQueryFactory(em);
------------------------------------------------
The above lines are part of the QueryDSL library.
We will talk about the generated class first, but before that let's see BookRepositoryImpl that does not have any additional methods.
xxxxxxxxxx
package com.example.repository.jpa;
import com.example.entity.Book;
import com.example.repository.BookRepository;
import org.springframework.stereotype.Repository;
import javax.persistence.EntityManager;
public class BookRepositoryImpl extends BaseRepositoryImpl<Book, Long> implements BookRepository {
public BookRepositoryImpl(EntityManager em) {
super(Book.class, em);
}
}
That’s it. Simple as that. Just provide the entity type + id type to the base class. (Spring framework will inject Entity Manager automatically so no need to specify @Autowired annotation — starting from Spring 4.3).
QueryDSL Generated Classes
Now let's come back to the QueryDSL generated classes. It is a part of the framework that allows you to write type-safe queries in a SQL-similar way.
First, we need to bring the necessary dependencies and enable the plugin for a class generation. There is an example based on the Maven build tool:
xxxxxxxxxx
<dependency>
<groupId>com.querydsl</groupId>
<artifactId>querydsl-jpa</artifactId>
</dependency>
<dependency>
<groupId>com.querydsl</groupId>
<artifactId>querydsl-apt</artifactId>
</dependency>
xxxxxxxxxx
<plugin>
<groupId>com.mysema.maven</groupId>
<artifactId>apt-maven-plugin</artifactId>
<version>1.1.3</version>
<executions>
<execution>
<goals>
<goal>process</goal>
</goals>
<configuration>
<outputDirectory>target/generated-sources/java</outputDirectory>
<processor>com.querydsl.apt.jpa.JPAAnnotationProcessor</processor>
</configuration>
</execution>
</executions>
</plugin>
The apt-maven-plugin is responsible for finding all JPA Entity classes and generating appropriate Qclasses in the generated-source folder:

Now let's see what we can do with QueryDSL.
Let's assume we need to find the author by email ignoring the case sensitivity:
xxxxxxxxxx
public class AuthorRepositoryImpl extends BaseRepositoryImpl<Author, Long> implements AuthorRepository {
public AuthorRepositoryImpl(EntityManager em) {
super(Author.class, em);
}
public Optional<Author> findByEmailIgnoreCase(String email) {
return Optional.ofNullable(
queryFactory
.select(author)
.from(author)
.where(author.email.equalsIgnoreCase(email))
.fetchFirst()
);
}
}
And there is the executed SQL query:
xxxxxxxxxx
select author0_.id as id1_0_, author0_.email as email2_0_, author0_.full_name as full_nam3_0_ from author author0_ where lower(author0_.email)='stephen.king@email.com' limit 1
QueryDSL will automatically convert the input parameter of the method to the lower case and use the lower() SQL function on the query.
If we need to execute a more complex query and count books size by each author we can do it like this:
xxxxxxxxxx
public class AuthorRepositoryImpl extends BaseRepositoryImpl<Author, Long> implements AuthorRepository {
public AuthorRepositoryImpl(EntityManager em) {
super(Author.class, em);
}
public List<AuthorStatistic> findAuthorStatistic() {
return queryFactory
.from(author)
.innerJoin(author.books, book)
.groupBy(author.fullName)
.select(Projections.constructor(AuthorStatistic.class,
author.fullName,
book.count())
)
.fetch();
}
}
And there is the built SQL query:
xxxxxxxxxx
select author0_.full_name as col_0_0_, count(books1_.id) as col_1_0_ from author author0_ inner join book books1_ on author0_.id=books1_.author_id group by author0_.full_name
As you can see, we retrieve only the information which is needed: author name and book count.
It is done by one of the best features of QueryDSL — Projection.
We can map the query result to the custom DTO class directly:
xxxxxxxxxx
package com.example.dto;
import lombok.AllArgsConstructor;
import lombok.Data;
public class AuthorStatistic {
private String authorName;
private Long bookSize;
}
The last example will be dealing with ‘N+1 problem’. Let's assume that we need to retrieve all authors with their books. Using QueryDSL we can specify fetchJoin():
xxxxxxxxxx
public class AuthorRepositoryImpl extends BaseRepositoryImpl<Author, Long> implements AuthorRepository {
public AuthorRepositoryImpl(EntityManager em) {
super(Author.class, em);
}
public List<Author> findAllWithBooks() {
return queryFactory
.select(author).distinct()
.from(author)
.innerJoin(author.books, book).fetchJoin()
.fetch();
}
}
And here is the SQL result:
xxxxxxxxxx
select distinct author0_.id as id1_0_0_, books1_.id as id1_1_1_, author0_.email as email2_0_0_, author0_.full_name as full_nam3_0_0_, books1_.author_id as author_i4_1_1_, books1_.iban as iban2_1_1_, books1_.name as name3_1_1_, books1_.author_id as author_i4_1_0__, books1_.id as id1_1_0__ from author author0_ inner join book books1_ on author0_.id=books1_.author_id
As you can see only one query executed. All books for the authors will be loaded and there will be no additional subselects or LazyLoadingExceptions.
distinct() operator was used in the original query for removing author duplicates from the result.
Conclusion
If you enjoy the article and would like to see the practices and frameworks for testing the persistence layer you can check my next article.
