The Evolution of Database Architectures: Navigating Big Data, Cloud, and AI Integration

In the ever-expanding digital landscape, where data is generated at an unprecedented rate, the architecture of databases stands as the bedrock of efficient data management. With the rise of Big Data and Cloud technologies, alongside the integration of Artificial Intelligence (AI), the realm of database architectures has undergone a profound transformation.
This article delves into the intricate world of database architectures, exploring their adaptation to Big Data and Cloud environments while also dissecting the evolving impact of AI on their structure and functionality. As organizations grapple with the challenges of handling vast amounts of data in real time, the significance of robust database architectures becomes increasingly apparent. From the traditional foundations of Relational Database Management Systems (RDBMS) to the flexible solutions offered by NoSQL databases and the scalability of cloud-based architectures, the evolution continues to meet the demands of today's data-driven landscape.
Furthermore, the convergence of AI technologies introduces new dimensions to database management, enabling intelligent query optimization, predictive maintenance, and the emergence of autonomous databases. Understanding these dynamics is crucial for navigating the complexities of modern data ecosystems and leveraging the full potential of data-driven insights.
The Traditional Foundation: Relational Database Management Systems (RDBMS)
Traditionally, Relational Database Management Systems (RDBMS) have been the stalwarts of data management. Characterized by structured data organized into tables with predefined schemas, RDBMS ensures data integrity and transactional reliability through ACID (Atomicity, Consistency, Isolation, Durability) properties. Examples of RDBMS include MySQL, Oracle, and PostgreSQL.
Embracing the Complexity of Big Data: NoSQL Databases
The advent of Big Data necessitated a shift from the rigid structures of RDBMS to more flexible solutions capable of handling massive volumes of unstructured or semi-structured data. Enter NoSQL databases, a family of database systems designed to cater to the velocity, volume, and variety of Big Data (Kaushik Kumar Patel (2024)). NoSQL databases come in various forms, including document-oriented, key-value stores, column-family stores, and graph databases, each optimized for specific data models and use cases. Examples include MongoDB, Cassandra, and Apache HBase.
Harnessing the Power of the Cloud: Cloud-Based Database Architectures
Cloud-based database architectures leverage the scalability, flexibility, and cost-efficiency of cloud infrastructure to provide on-demand access to data storage and processing resources. Through models such as Infrastructure as a Service (IaaS), Platform as a Service (PaaS), and Database as a Service (DBaaS), organizations can choose the level of abstraction and management that suits their needs. Multi-cloud and hybrid cloud architectures further enhance flexibility by enabling workload distribution across multiple cloud providers or integration with on-premises infrastructure (Hichem Moulahoum, Faezeh Ghorbanizamani (2024)). Notable examples include Amazon Aurora, Google Cloud Spanner, and Microsoft Azure Cosmos DB.
Data Flow and Storage: On-Premises vs. Cloud Databases
Understanding data flow and storage is crucial for managing both on-premises and cloud databases effectively. Here's a breakdown with a Data Base Architect (DBA) diagram for each scenario:
On-Premises Database
Explanation
- Application server: This interacts with the database, initiating data creation, retrieval, and updates.
- Data extraction: This process, often utilizing Extract, Transform, Load (ETL) or Extract, Load, transform (ELT) methodologies, extracts data from various sources, transforms it into a format compatible with the database, and loads it.
- Database: This is the core storage location, managing and organizing data using specific structures like relational tables or NoSQL document stores.
- Storage: This represents physical storage devices like hard disk drives (HDDs) or solid-state drives (SSDs) holding the database files.
- Backup system: Regular backups are crucial for disaster recovery and ensuring data availability.
Data Flow
- Applications interact with the database server, sending data creation, retrieval, and update requests.
- The ETL/ELT process extracts data from various sources, transforms it, and loads it into the database.
- Data is persisted within the database engine, organized by its specific structure.
- Storage devices physically hold the database files.
- Backups are periodically created and stored separately for data recovery purposes
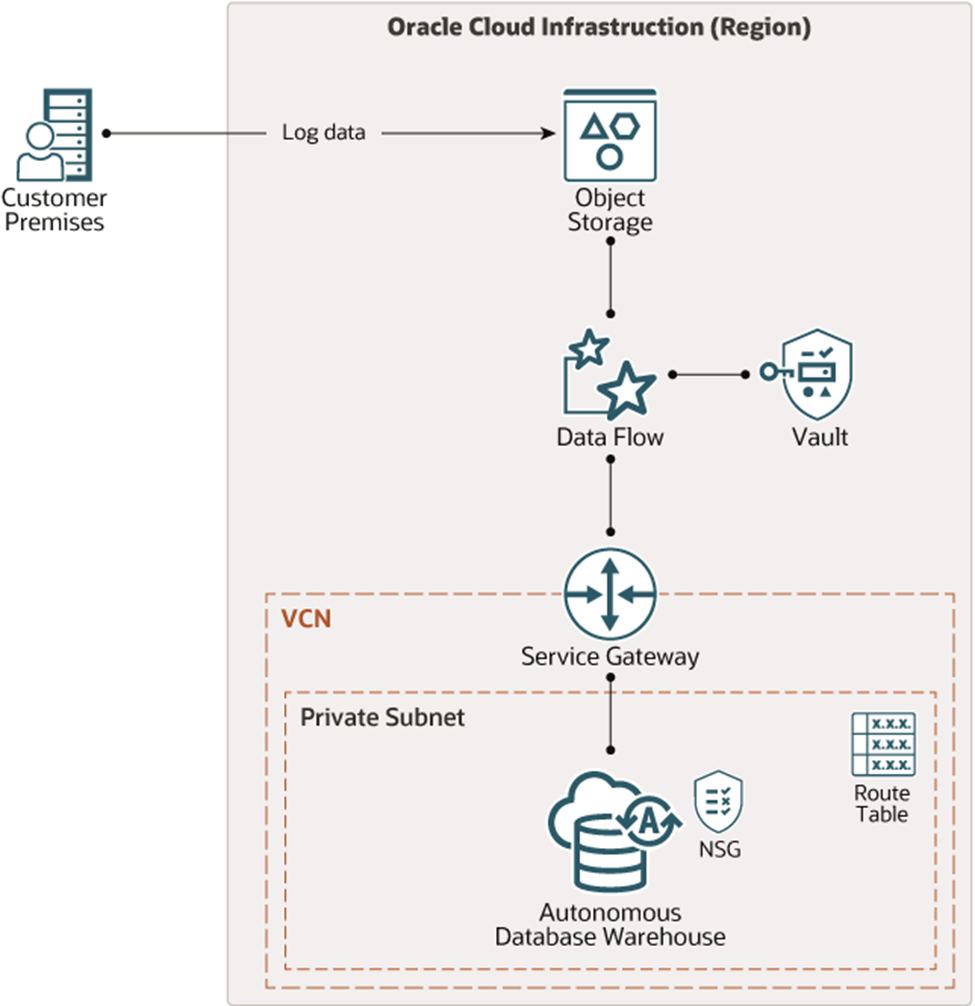
Cloud Database
Explanation
- Application server: Like the on-premises scenario, this interacts with the database but through an API gateway or SDK provided by the cloud service provider.
- API Gateway/SDK: This layer acts as an abstraction, hiding the underlying infrastructure complexity and providing a standardized way for applications to interact with the cloud database.
- Cloud database: This is a managed service offered by cloud providers that handles database creation, maintenance, and scaling automatically.
- Cloud storage: This represents the cloud provider's storage infrastructure, where database files and backups are stored.
Data Flow
- Applications interact with the cloud database through the API gateway or SDK, sending data requests.
- The API gateway/SDK translates the requests and interacts with the cloud database service.
- The cloud database service manages data persistence, organization, and retrieval.
- Data is stored within the cloud provider's storage infrastructure.
Key Differences
- Management: On-premises databases require in-house expertise for setup, configuration, maintenance, and backups. Cloud databases are managed services, with the provider handling these aspects, freeing up IT resources.
- Scalability: On-premises databases require manual scaling of hardware resources, while cloud databases offer elastic scaling, automatically adjusting to meet changing needs.
- Security: Both options require security measures like access control and encryption. However, cloud providers often have robust security infrastructure and compliance certifications.
The Convergence of AI and Database Architectures
The integration of Artificial Intelligence (AI) into database architectures heralds a new era of intelligent data management solutions. AI technologies such as machine learning and natural language processing augment database functionality by enabling automated data analysis, prediction, and decision-making. These advancements not only streamline operations but also unlock new avenues for optimizing database performance and reliability.
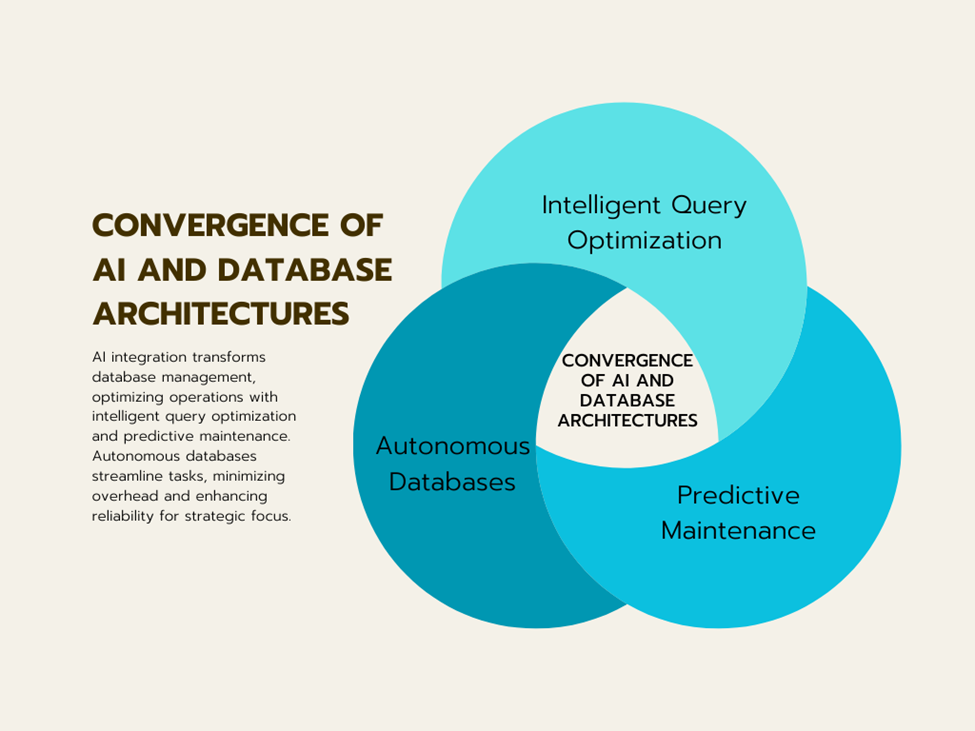
Intelligent Query Optimization
In the realm of intelligent query optimization, AI-powered techniques revolutionize how databases handle complex queries. By analyzing workload patterns and system resources in real time, AI algorithms dynamically adjust query execution plans to enhance efficiency and minimize latency. This proactive approach ensures optimal performance, even in the face of fluctuating workloads and evolving data structures.
Predictive Maintenance
Predictive maintenance, empowered by AI, transforms how organizations manage database health and stability. By leveraging historical data and predictive analytics, AI algorithms forecast potential system failures or performance bottlenecks before they occur. This foresight enables proactive maintenance strategies, such as resource allocation and system upgrades, mitigating downtime, and optimizing database reliability.
Autonomous Databases
Autonomous databases represent the pinnacle of AI-driven innovation in database architectures. These systems leverage AI algorithms to automate routine tasks, including performance tuning, security management, and data backups. By autonomously optimizing database configurations and addressing security vulnerabilities in real time, autonomous databases minimize operational overhead and enhance system reliability. This newfound autonomy allows organizations to focus on strategic initiatives rather than routine maintenance tasks, driving innovation and efficiency across the enterprise.
Looking Towards the Future: Trends and Challenges
As the trajectory of database architectures unfolds, a spectrum of trends and challenges beckons our attention:
Edge Computing
The proliferation of Internet of Things (IoT) devices and the rise of edge computing architectures herald a shift towards decentralized data processing. This necessitates the development of distributed database solutions capable of efficiently managing and analyzing data at the network edge, optimizing latency and bandwidth usage while ensuring real-time insights and responsiveness.
Data Privacy and Security
In an era of burgeoning data volumes, the preservation of data privacy and security assumes paramount importance (Jonny Bairstow, (2024)). As regulatory frameworks tighten and cyber threats escalate, organizations must navigate the intricate landscape of data governance to ensure compliance with stringent regulations and fortify defenses against evolving security vulnerabilities, safeguarding sensitive information from breaches and unauthorized access.
Federated Data Management
The proliferation of disparate data sources across diverse systems and platforms underscores the need for federated data management solutions. Federated database architectures offer a cohesive framework for seamless integration and access to distributed data sources, facilitating interoperability and enabling organizations to harness the full spectrum of their data assets for informed decision-making and actionable insights.
Quantum Databases
The advent of quantum computing heralds paradigm shifts in database architectures, promising exponential leaps in computational power and algorithmic efficiency. Quantum databases, leveraging the principles of quantum mechanics, hold the potential to revolutionize data processing by enabling faster computations and more sophisticated analytics for complex data sets. As quantum computing matures, organizations must prepare to embrace these transformative capabilities, harnessing quantum databases to unlock new frontiers in data-driven innovation and discovery.
Conclusion
The evolution of database architectures mirrors the relentless march of technological progress. From the rigid structures of traditional RDBMS to the flexibility of NoSQL databases and the scalability of cloud-based solutions, databases have adapted to meet the evolving needs of data-intensive applications. Moreover, the integration of AI augments database functionality, paving the way for more intelligent and automated data management solutions. As we navigate the future, addressing emerging challenges and embracing innovative technologies will be essential in shaping the next generation of database architectures.
References
- Kaushikkumar Patel (2024), Mastering Cloud Scalability: Strategies, Challenges, and Future Directions: Navigating Complexities of Scaling in Digital Era
- Hichem Moulahoum, Faezeh Ghorbanizamani (2024), Navigating the development of silver nanoparticles based food analysis through the power of artificial intelligence
- D. Dhinakaran, S.M. Udhaya Sankar, D. Selvaraj, S. Edwin Raja (2024), Privacy-Preserving Data in IoT-based Cloud Systems: A Comprehensive Survey with AI Integration
- Mihaly Varadi, Damian Bertoni, Paulyna Magana, Urmila Paramval, Ivanna Pidruchna, (2024), AlphaFold Protein Structure Database in 2024: providing structure coverage for over 214 million protein sequences
- Jonny Bairstow, (2024), “Navigating the Confluence: Big Data Analytics and Artificial Intelligence - Innovations, Challenges, and Future Directions”
