Microservices on Top of an In-Memory Data Grid: Part III

This is the last blog post in a series recommending how to design and implement microservices-based architecture on top of Apache Ignite In-Memory Data Fabric. The first two posts in the series can be found here:
- Part I - Overview of the proposed solution.
- Part II - Various coding templates needed to implement the solution in a live environment.
This final post describes how to integrate the cluster with a persistent store and send requests to the microservices from external applications -- apps that know nothing about the cluster and don't rely on its APIs.
We will continue to refer to the same GitHub project introduced in Part II. So, make sure to check it out on a local machine or update to the latest modifications.
Persistent Store for Data Nodes
Apache Ignite is an in-memory data platform that keeps the data in RAM by default. However, there is a way to persist it on disk if, for instance, you want to be sure that the data doesn't get lost even after the whole cluster restarts.
To enable the persistence, we just need to resolve three quick things:
- Decide what we want to use as a persistent store (a relational database, MongoDB, Cassandra, Hadoop, etc.).
- Pick up one of the existing implementations of Cache Store interface or develop a new one if needed.
- Add an implementation to a cache configuration.
That's it! After having this done the data nodes, explained in Part I, will interact with the persistent storage like it's shown on a picture below:
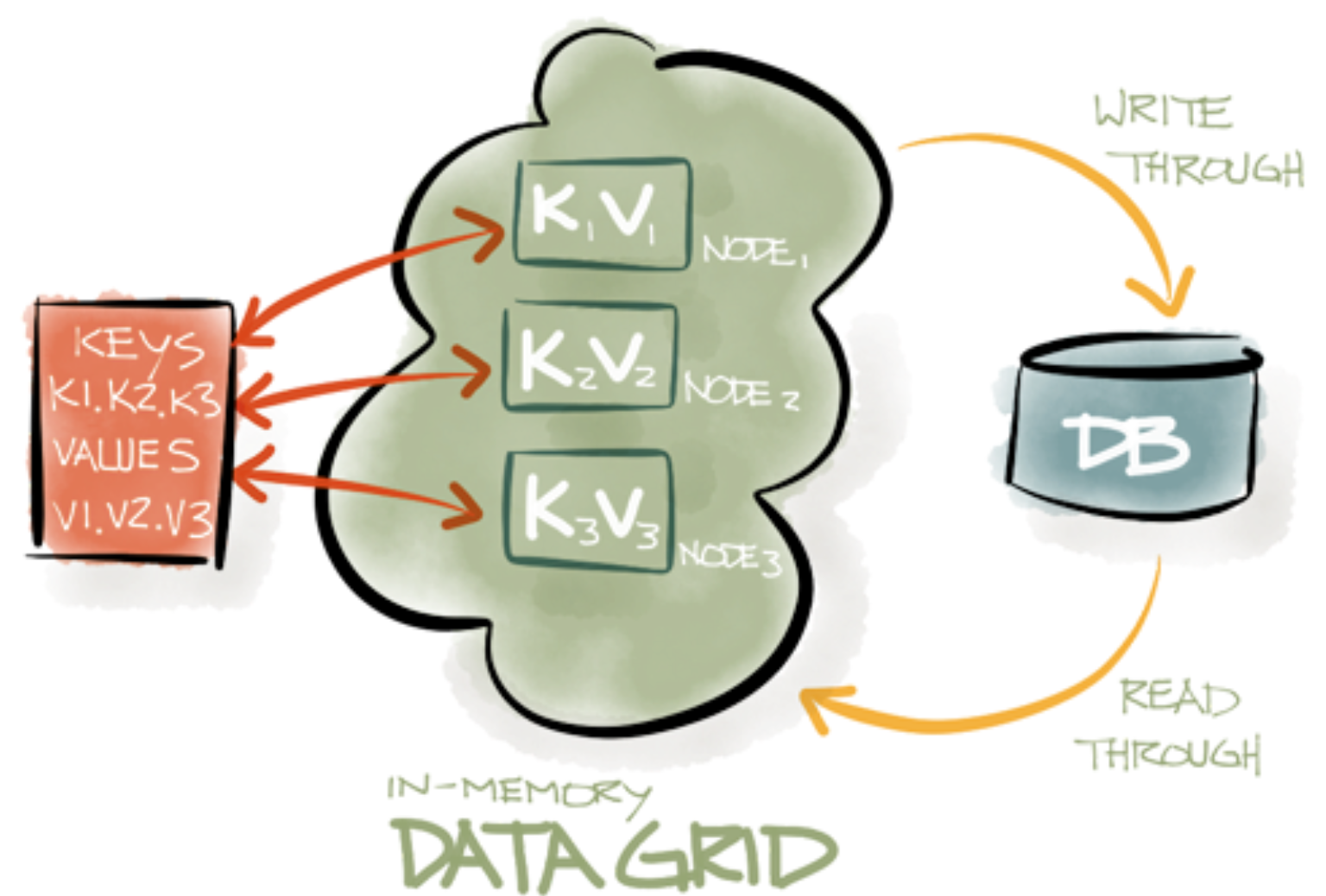
In particular, every update that will happen in RAM will be automatically propagated to disk or if there is no value for key1 in RAM. Then it will be preloaded from the persistent storage on-the-fly.
Now let's see how we can implement and plug in a custom store for our microservices-based architecture referring to specially created GitHub project.
For the sake of the demo, we created a dummy persistent store implementation that actually stores data in a concurrent hash map. However, the point here is to demonstrate that, basically, Apache Ignite requires you to implement three methods only if there is a need to create a custom persistent store implementation:
/** {@inheritDoc} */
public BinaryObject load(Long key) throws CacheLoaderException {
System.out.println(" >>> Getting Value From Cache Store: " + key);
return storeImpl.get(key);
}
/** {@inheritDoc} */
public void write(Cache.Entry entry) throws CacheWriterException {
System.out.println(" >>> Writing Value To Cache Store: " + entry);
storeImpl.put(entry.getKey(), entry.getValue());
}
/** {@inheritDoc} */
public void delete(Object key) throws CacheWriterException {
System.out.println(" >>> Removing Key From Cache Store: " + key);
storeImpl.remove(key);
}After that, let's enable our sample store in the configuration of data nodes by adding the line below to the 'maintenance' cache configuration:
<property name="cacheStoreFactory">
<bean class="javax.cache.configuration.FactoryBuilder" factory-method="factoryOf">
<constructor-arg value="common.cachestore.SimpleCacheStore"/>
</bean>
</property>Finally, let's check that the Apache Ignite cluster communicates to the store. To do that, open up GitHub project in your development environment and start an instance of a data node (DataNodeStartup file), maintenance service node (MaintenanceServiceNodeStartup file) and vehicle service node (VehicleServiceNodeStartup file). Once all the nodes connect to each other, start TestAppStartup that connects to the clusters, puts some data there and calls the services. After TestAppStartup completes its execution go to DataNodeStartup logging window and locate a string like the one below:
>>> Writing Value To Cache Store: Entry [key=1, val=services.maintenance.common.Maintenance [idHash=88832938, hash=1791054845, date=Tue Apr 18 14:55:52 PDT 2017, vehicleId=6]] The string appeared because TestAppStartup triggered an update of 'maintenance' cache that automatically sent the update to our dummy persistent store.
Connecting From an External Application
TestAppStartup is one of the examples of an application that works with our microservices deployed in the Apache Ignite cluster. It's an internal application in a sense that it connects to the cluster directly and talks to the services by means of Service Grid API.
But what about external applications that might not or should not be aware of your cluster and the overall deployment. How can they interact with the microservices? A solution is simple. An Apache Ignite service should listen to incoming requests from the external application in some different way and respond to them.
For instance, when an instance of MaintenanceService is deployed in the cluster, it starts a server socket that accepts remote connections on a predefined port (see MaintenanceServiceImpl for more details). Now, start an external application using ExternalTestApp that connects to the service over that server socket and retrieves a maintenance schedule for every vehicle. An output of ExternalTestApp should be similar the one below:
>>> Getting maintenance schedule for vehicle:0
>>> Getting maintenance schedule for vehicle:1
>>> Getting maintenance schedule for vehicle:2
>>> Getting maintenance schedule for vehicle:3
>>> Getting maintenance schedule for vehicle:4
>>> Getting maintenance schedule for vehicle:5
>>> Getting maintenance schedule for vehicle:6
>>> Maintenance{vehicleId=6, date=Tue Apr 18 14:55:52 PDT 2017}
>>> Getting maintenance schedule for vehicle:7
>>> Getting maintenance schedule for vehicle:8
>>> Getting maintenance schedule for vehicle:9
>>> Shutting down the application.
In this series, we've seen how a microservices-based solution can be deployed and maintained in an Apache Ignite cluster. Such a solution allows us offloading of microservices lifecycle and high-availability tasks to Apache Ignite thinking of an actual implementation. Plus, having all the data and microservices distributed across the cluster means that you no longer need to worry about performance and fault-tolerance - this will be handled for you by Apache Ignite.
