Disruptor With Parallel Consumers vs. Multiple Worker Threads With Queues

We live in a millennium where data is available in abundance. Every day, we deal with large volumes of data that require complex processing in a short amount of time. Fetching data from similar or interrelated events that occur simultaneously is a process that we regularly go through. This is where we require parallel processing that divides a complex task and process it in multiple threads to produce the output in small time. Processing in parallel may introduce an overhead when it is necessary to ensure the order of the events after they are processed by each thread.
In this article, we focus on two models of parallel programming where the order of the events should be ensured and review the performance of each. The performance numbers are obtained for processing a data set that includes sensor readings from molding machines. The attributes in the data set include the machine number, a timestamp for the reading, a dimension for which the reading was obtained, and the value of the reading. The data is read from a file and each thread is assigned with the task of constructing a customized “event” object. After the object is constructed, the output from each thread should be obtained in the ascending order of timestamp of the object.
Executor Pool With Multiple Queues
In the first architecture, we make use of a thread pool to distribute the workload among threads that will process the tasks in parallel. When using a thread pool, we can not guarantee the order in which the tasks will finish execution. Since the events are processed in parallel, the execution of the events will not take place in the order they were allocated to each thread to be processed. To ensure the order, the results returned must be sorted according to a predefined criterion depending on the use case. Each result obtained after being processed by a thread is published to a queue.
These queues are individually sorted, but when considering all the queues, they are not. In order to ensure the final ordering of results, a separate thread is used. This thread will take the head of each queue, store them temporarily, and sort and release a data item according to the predefined criteria for further processing.
Although the parallel processing is executed to increase the speed of processing, the sorting might introduce a bottleneck where the fast execution expected through parallel processing will not be experienced in the application. This architecture is illustrated below.

The image below depicts three queues that store data from a thread pool and the data released are expected in timestamp order. As you can see, all data items in each queue are individually sorted, but not all of them as a whole. In order to ensure the final ordering of events, an additional thread is required. This thread takes the head of each queue, holds them to ensure order, and releases the data item with the lowest timestamp.
.png")
Parallel Processing Using the Disruptor
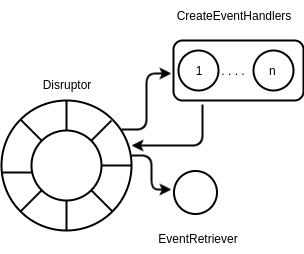
The second architecture is using a concurrent Java API, the Disruptor. This uses a ring buffer as the main data structure, which holds the events to be processed in parallel. As soon as an event is published to the ring buffer, the consumers (or, as they are called in the API, the event handlers) operate on the events, processing them in parallel. Each event in the disruptor is picked up by all the event handlers that are initiated. In other words, they are multicasted. If the event is to be processed by only one event handler, a filtering criterion has to be specified in the handler implementation. Different types of event handlers can be defined which perform different operations on the events.
The order in which the event handlers can operate on the events can be specified using methods in the event handlers. This ordering is automatically handled by the disruptor API such that one handler operates on the event only after the previous handler has completed its processing of a particular event stored in the ring buffer.
In order to eliminate the bottleneck of sorting experienced in the previous architecture, the order of the events is ensured by the event handlers by writing the event back into the same location in the ring buffer after the required processing is performed.
Another handler can be assigned to read all the events after the previous handler writes them back to the ring buffer.
Executor executor = Executors.newCachedThreadPool();
Disruptor < EventWrapper > disruptor = new Disruptor < > (EventWrapper::new, 128, executor);
RingBuffer < EventWrapper > buffer = disruptor.getRingBuffer();
CreateEventHandler[] create = new CreateEventHandler[3];
for (int i = 0; i < 3; i++) {
create[i] = new CreateEventHandler(i, 3, buffer);
}
EventRetriever eventRetriever = new EventRetriever();
disruptor.handleEventsWith(create);
disruptor.after(create).handleEventsWith(eventRetriever);
disruptor.start();The disruptor is initialized with a ring buffer size of 128. EventWrapper is the custom object to be stored in the ring buffer. Two types of event handlers are used, namely CreateEventHandler and EventRetriever. The handleEventsWith method specifies the number of event handlers that should process the objects stored in the ring buffer. In order to specify the order in which the event handlers should operate on the events, the after method is used. This ensures that the EventRetriever processes the events only after the CreateEventHandler processes them.
Publishing to the Ring Buffer
long sequence = buffer.next();
EventWrapper wrap = buffer.get(sequence);
wrap.setData(data);
wrap.setTime(System.currentTimeMillis());
buffer.publish(sequence);Before publishing to the ring buffer, the next location in the ring buffer to which an event can be published has to be acquired by calling the next method of the buffer. An EventWrapper object is created and published to the location retrieved from the ring buffer.
Implementing an Event Handler
An event handler can be implemented as shown below.
public class CreateEventHandler implements EventHandler < EventWrapper > {
private final long ID;
private final long NUM;
private RingBuffer < EventWrapper > buffer;
public CreateEventHandler(int ID, int num, RingBuffer < EventWrapper > buffer) {
this.ID = ID;
this.NUM = num;
this.buffer = buffer;
}
@Override
public void onEvent(EventWrapper eventWrapper, long sequence, boolean b) throws Exception {
if (!eventWrapper.isLast()) {
String[] data = eventWrapper.getData();
int partition = Integer.parseInt(data[2].split("_")[1]);
if (partition % NUM == ID) {
// implement logic to be carried out by the handler
buffer.publish(sequence);
}
}
}
}The onEvent method in the EventHandler interface is overridden to specify the logic to be carried out by the handler on an event retrieved from the ring buffer. In order to filter the events such that not all events are processed by all threads, a partition number is used to filter the events based on the ID assigned to each handler. The sequence is the position in the ring buffer where the processed event is stored. After carrying out the processing, the event is published back to the same location by invoking the publish method of the ring buffer.
The following table summarizes the throughput and latency for the two architectures when the number of threads/event handlers are varied.
|
|
Executor with multiple queues |
Disruptor with event handlers |
||
| No. of threads/ No. of event handlers |
Throughput (events/ms) |
Latency (ms) |
Throughput (events/ms) |
Latency (ms) |
| 2 |
152 |
6.445 |
119 |
0.73 |
| 3 |
166 |
12.05 |
81.5 |
0.835 |
| 4 |
136.8 |
7.46 |
83.2 |
0.87 |
| 5 |
163 |
9.28 |
75.5 |
1.08 |
| 6 |
166 |
6.16 |
71 |
1.115 |


We note that the disruptor-based architecture has much better latency compared to that of executor pool-based architecture. The throughput, however, is higher in executor-based architecture.
Conclusion
In this article, we looked at the performance of two concurrent architectures, one by using an executor thread pool and the other by using the disruptor. The first architecture showed higher throughput when compared to the disruptor architecture but the difference was not highly significant. On the other hand, the disruptor-based architecture showed a significantly lower latency than the executor-thread-pool-based implementation. One reason for the low latency of the disruptor-based model is the extensive use of lock-free algorithms in the disruptor.
