Building an Amazon-Like Recommendation Engine Using Slash GraphQL

Back in the early 2000s, I was working on a project implementing an eCommerce solution by Art Technology Group (ATG), now owned by Oracle. The ATG Dynamo product was an impressive solution as it included a persistence layer and a scenarios module. At the time, companies like Target and Best Buy used the Dynamo solution, leveraging the scenario module to provide recommendations to the customer.
As an example, the Dynamo eCommerce solution was smart enough to remember when a customer added a product to their cart and later removed it. As an incentive, the scenario server could be designed to offer the same customer a modest discount on a future visit if they re-added the product into their cart and purchased it within the next 24 hours.
Since those days, I have always wanted to create a simple recommendations engine, which is my goal for this publication.
About the Recommendations Example
I wanted to keep things simple and create some basic domain objects for the recommendations engine. In this example, the solution will make recommendations for musical artists and the underlying Artist object is quite simple:
@AllArgsConstructor
@NoArgsConstructor
@Data
public class Artist {
private String name;
}
In a real system, there would be so many more attributes to track. However, in this example, the name of the artist will suffice.
As one might expect, customers will rate artists on a scale of 1 to 5, where a value of five represents the best score possible. Of course, it is possible (and expected) that customers will not rate every artist. The customer will be represented (again) by a very simple Customer object:
xxxxxxxxxx
public class Customer {
private String username;
}
The concept of a customer rating an artist will be captured in the following Rating object:
xxxxxxxxxx
public class Rating {
private String id;
private double score;
private Customer by;
private Artist about;
}
In my normal Java programming efforts I would likely use private Customer customer and private Artist artist for my objects, but I wanted to follow the pattern employed by graph databases, where I employ variables like by and about instead. This should become more clear as the article continues.
Dgraph Slash GraphQL
With the popularity of graph databases, I felt like my exploration of creating a recommendations engine should employ a graph database. After all, GraphQL has become a popular language for talking to services about graphs. While I only have some knowledge around graph databases, my analysis seemed to conclude that a graph database is the right choice for this project and is often the source for real-world services making recommendations. Graph databases are a great solution when the relationships (edges) between your data (nodes) are just as important as the data itself — and a recommendation engine is the perfect example.
However, since I'm just starting out with graph databases, I certainly didn't want to worry about starting up a container or running a GraphQL database locally. Instead I wanted to locate a SaaS provider. I decided to go with Dgraph's fully-managed backend service, called Slash GraphQL. It's a hosted, native GraphQL solution. The Slash GraphQL service was just released on September 10th, 2020, and includes a free 10,000 credits service, which can be enabled by using the following link:
https://slash.dgraph.io/
After launching this URL, a new account can be created using the normal authorization services:
In my example, I created a backend called "spring-boot-demo" which ultimately resulted in the following dashboard:
The process to get started was quick and free, making it effortless to configure the Slash GraphQL service.
Configuring Slash GraphQL
As with any database solution, we must write a schema and deploy it to the database. With Slash GraphQL, this was quick and easy:
xxxxxxxxxx
type Artist {
name: String! @id @search(by: [hash, regexp])
ratings: [Rating] @hasInverse(field: about)
}
type Customer {
username: String! @id @search(by: [hash, regexp])
ratings: [Rating] @hasInverse(field: by)
}
type Rating {
id: ID!
about: Artist!
by: Customer!
score: Int @search
}
In fact, my original design was far more complex than it needed to be, and the level of effort behind making revisions was far easier than I expected. I quickly began to see the value as a developer to be able to alter the schema without much effort.
With the schema in place, I was able to quickly populate some basic Artist information:
xxxxxxxxxx
mutation {
addArtist(input: [
{name: "Eric Johnson"},
{name: "Genesis"},
{name: "Led Zeppelin"},
{name: "Rush"},
{name: "Triumph"},
{name: "Van Halen"},
{name: "Yes"}]) {
artist {
name
}
}
}
At the same time, I added a few fictional Customer records:
xxxxxxxxxx
mutation {
addCustomer(input: [
{username: "Doug"},
{username: "Jeff"},
{username: "John"},
{username: "Russell"},
{username: "Stacy"}]) {
customer {
username
}
}
}
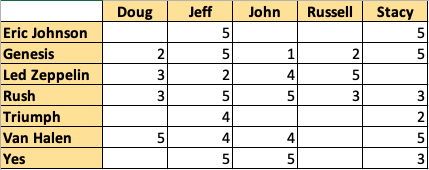
As a result, the five customers will provide ratings for the seven artists, using the following table:
An example of the rating process is shown below:
xxxxxxxxxx
mutation {
addRating(input: [{
by: {username: "Jeff"},
about: { name: "Triumph"},
score: 4}])
{
rating {
score
by { username }
about { name }
}
}
}
With the Slash GraphQL data configured and running, I can now switch gears and work on the Spring Boot service.
The Slope One Ratings Algorithm
In 2005, a research paper by Daniel Lemire and Anna Maclachian introduced the Slope One family of collaborative filtering algorithms. This simple form of item-based collaborative filtering looked to be a perfect fit for a recommendations service, because it takes into account ratings by other customers in order to score items not rated for a given customer.
In pseudo-code, the Recommendations Service would achieve the following objectives:
Retrieve the ratings available for all artists (by all customers).
Create a
Map<Customer, Map<Artist, Double>>from the data, which is a customer map, containing all the artists and their ratings.The rating score of 1 to 5 will be converted to a simple range between 0.2 (worst rating of 1) and 1.0 (best rating of 5).
With the customer map created, the core of the Slope One ratings processing will execute by calling the SlopeOne class:
Populate a
Map<Artist, Map<Artist, Double>>used to track differences in ratings from one customer to another.Populate a
Map<Artist, Map<Artist, Integer>>used to track the frequency of similar ratings.Use the existing maps to create a
Map<Customer, HashMap<Artist, Double>>which contain projected ratings for items not rated for a given customer.
For this example, a random Customer is selected and the corresponding object from the Map<Customer, HashMap<Artist, Double>> projectedData map is analyzed to return the following results:
xxxxxxxxxx
{
"matchedCustomer": {
"username": "Russell"
},
"recommendationsMap": {
"Artist(name=Eric Johnson)": 0.7765842245950264,
"Artist(name=Yes)": 0.7661904474477843,
"Artist(name=Triumph)": 0.7518039724158979,
"Artist(name=Van Halen)": 0.7635436007978691
},
"ratingsMap": {
"Artist(name=Genesis)": 0.4,
"Artist(name=Led Zeppelin)": 1.0,
"Artist(name=Rush)": 0.6
},
"resultsMap": {
"Artist(name=Eric Johnson)": 0.7765842245950264,
"Artist(name=Genesis)": 0.4,
"Artist(name=Yes)": 0.7661904474477843,
"Artist(name=Led Zeppelin)": 1.0,
"Artist(name=Rush)": 0.6,
"Artist(name=Triumph)": 0.7518039724158979,
"Artist(name=Van Halen)": 0.7635436007978691
}
}
In the example above, the "Russell" user was randomly selected. When looking at the original table (above), Russell only provided ratings for Genesis, Led Zeppelin, and Rush. The only artist that he truly admired was Led Zeppelin. This information is included in the ratingsMap object and also in the resultsMap object.
The resultsMap object includes projected ratings for the other four artists: Eric Johnson, Yes, Triumph, and Van Halen. To make things easier, there is a recommendationsMap included in the payload, which includes only the artists that were not rated by Russell.
Based upon the other reviews, the Recommendations Service would slightly favor Eric Johnson over the other four items—with a score of 0.78, which is nearly a value of four in the five-point rating system.
The Recommendations Service
In order to use the Recommendations Service, the Spring Boot server simply needs to be running and configured to connect to the Slash GraphQL cloud-based instance. The GraphQL Endpoint on the Slash GraphQL Dashboard can be specified in the application.yml as slash-graph-ql.hostname or via passing in the value via the ${SLASH_GRAPH_QL_HOSTNAME} environment variable.
The basic recommendations engine can be called using the following RESTful URI:
GET - {spring-boot-service-host-name}/recommend
This action is configured by the RecommendationsController, as shown below:
xxxxxxxxxx
(value = "/recommend")
public ResponseEntity<Recommendation> recommend() {
try {
return new ResponseEntity<>(recommendationService.recommend(), HttpStatus.OK);
} catch (Exception e) {
return new ResponseEntity<>(HttpStatus.BAD_REQUEST);
}
}
Which calls the RecommendationService:
xxxxxxxxxx
public class RecommendationService {
private final ArtistService artistService;
private final CustomerService customerService;
private final SlashGraphQlProperties slashGraphQlProperties;
private static final String RATING_QUERY = "query RatingQuery {"
+ "queryRating { "
+ "id, "
+ "score, "
+ "by { username }, "
+ "about { name } "
+ "}}";
public Recommendation recommend() throws Exception {
ResponseEntity<String> responseEntity = RestTemplateUtils.query(slashGraphQlProperties.getHostname(), RATING_QUERY);
try {
ObjectMapper objectMapper = new ObjectMapper();
SlashGraphQlResultRating slashGraphQlResult = objectMapper.readValue(responseEntity.getBody(), SlashGraphQlResultRating.class);
log.debug("slashGraphQlResult={}", slashGraphQlResult);
return makeRecommendation(slashGraphQlResult.getData());
} catch (JsonProcessingException e) {
throw new Exception("An error was encountered processing responseEntity=" + responseEntity.getBody(), e);
}
}
...
}
Please note — something that might be missed at a quick glance of this code, is the power and ease in being able to pull out a subgraph to perform the recommendation. In the example above, the slashGraphQlResult.getData() line is providing a subgraph to the makeRecommendation() method.
The RATING_QUERY is the expected Slash GraphQL format to retrieve Rating objects. The RestTemplateUtils.query() method is part of a static utility class, to keep things DRY (don't repeat yourself):
xxxxxxxxxx
public final class RestTemplateUtils {
private RestTemplateUtils() { }
private static final String MEDIA_TYPE_GRAPH_QL = "application/graphql";
private static final String GRAPH_QL_URI = "/graphql";
public static ResponseEntity<String> query(String hostname, String query) {
RestTemplate restTemplate = new RestTemplate();
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.valueOf(MEDIA_TYPE_GRAPH_QL));
HttpEntity<String> httpEntity = new HttpEntity<>(query, headers);
return restTemplate.exchange(hostname + GRAPH_QL_URI, HttpMethod.POST, httpEntity, String.class);
}
}
Once the slashGraphQlResult object is retrieved, the makeRecommendation() private method is called, which returns the following Recommendation object. (This was shown above in JSON format):
xxxxxxxxxx
public class Recommendation {
private Customer matchedCustomer;
private HashMap<Artist, Double> recommendationsMap;
private HashMap<Artist, Double> ratingsMap;
private HashMap<Artist, Double> resultsMap;
}
Conclusion
In this article, an instance of Dgraph Slash GraphQL was created with a new schema and sample data was loaded. That data was then utilized by a Spring boot service which served as a basic recommendations engine. For those interested in the full source code, please review the GitLab repository.
From a cost perspective, I am quite impressed with the structure that Slash GraphQL provides. The new account screen indicated that I have 10,000 credits to use, per month, for no charge. In the entire time I used Slash GraphQL to prototype and create everything for this article, I only utilized 292 credits. Current pricing for Slash GraphQL makes use of the service very attractive, at $9.99/month for 5GB of data transfer. No hidden costs. No costs for data storage. No cost per query.
Using a graph database for the first time did present a small learning curve and I am certain there is far more than I can learn by continuing this exercise. I felt that Slash GraphQL exceeded my expectations with the ability to change the schema as I learned more about my needs. As a feature developer, this is a very important aspect that should be recognized, especially compared to the same scenario with a traditional database.
In my next article, I'll introduce an Angular (or React) client into this process, which will interface directly with GraphQL and the Recommendation Service running in Spring Boot.
Have a really great day!
