Utilizing Apache Spark for Azure Network Security Group Management

As the IT landscape continues to evolve rapidly, network security becomes increasingly crucial for safeguarding sensitive data and maintaining network integrity. Implementing robust access control measures, such as network security groups (NSGs), is essential to ensure network security. NSGs function as virtual firewalls, permitting or denying inbound and outbound traffic to and from Azure resources based on predefined rules. However, managing and monitoring NSGs can become complex, particularly when dealing with numerous rules and resources. It is imperative to maintain a balance between allowing legitimate traffic and maintaining a high level of security by ensuring defined rules are neither overly permissive nor overly restrictive. This article presents an approach that utilizes Apache Spark and Python code to identify the optimal set of user rules by analyzing Network Watcher Flow Events Logs. The proposed method aims to enhance the efficiency and effectiveness of managing NSGs while ensuring robust network security in Azure environments.
Introduction
Azure network security groups (NSG) allow or deny network traffic to virtual machine instances within a virtual network by activating rules or access control lists (ACLs). An NSG can be associated with a subnet or with an individual virtual machine instance within that subnet. All Virtual Machine instances connected to a subnet by an NSG are subject to its ACL rules. You can also restrict traffic to an individual virtual machine by associating an NSG directly with it. Each network security group contains a set of Default Rules. The default rules in each NSG include three inbound rules and three outbound rules. The default rules cannot be deleted, but since they are assigned the lowest priority, you can replace them with your own.
Inbound vs. Outbound
There are two types of NSGs: inbound and outbound.
From a VM perspective, NSG ruleset direction is evaluated. Inbound rules, for instance, affect traffic initiated from external sources, such as the Internet or another virtual machine, to a virtual machine. Traffic sent from a VM is affected by outbound security rules. A session's return traffic is automatically allowed and is not validated against rules in the reverse direction. Our focus should be on allowing (or denying) the client-to-server direction of the session.
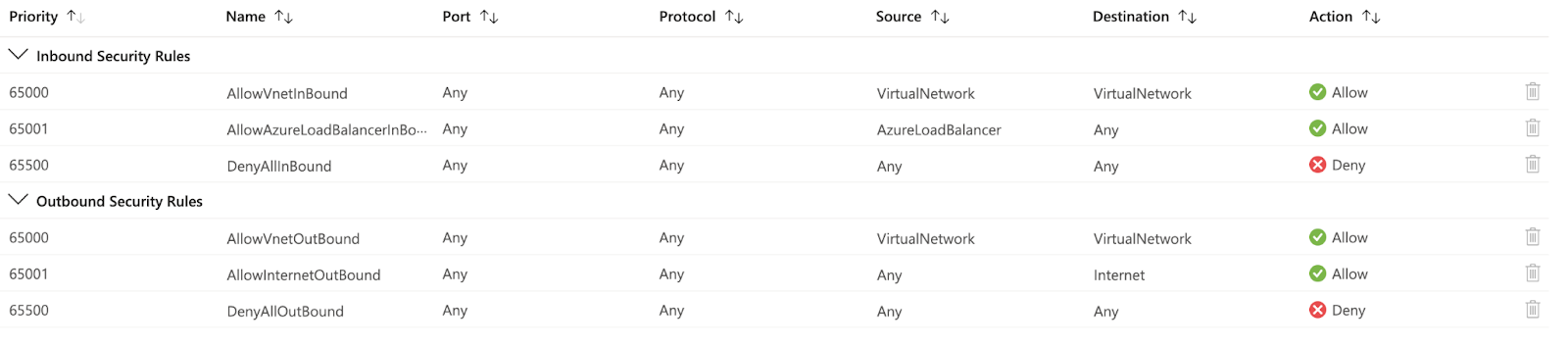 Figure 1- Default Network Security Rule
Figure 1- Default Network Security Rule
User Security Rules
In the Network Security Group (NSG), we can apply the right rules with a high priority number to a network interface or a subnet to protect Azure resources. The following fields are included in each security rule:
- Rule name and description
- Priority number, which defines the position of the rule in the ruleset. Rules on the top are processed first; therefore, the smaller number has a higher preference
- Source and destination with port numbers (for TCP and UDP)
- IP protocol types, such as TCP, UDP, and ICMP. These 3 protocols cover almost all application requirements. “Any” keyword permits all IP protocols
The user rules are applied on top of the default rules and restrict access based on IP address, port number, and protocol in the Network Security Group. NSG's inbound security rules are shown in Figure 2. We can also define outbound security rules on top of default rules.
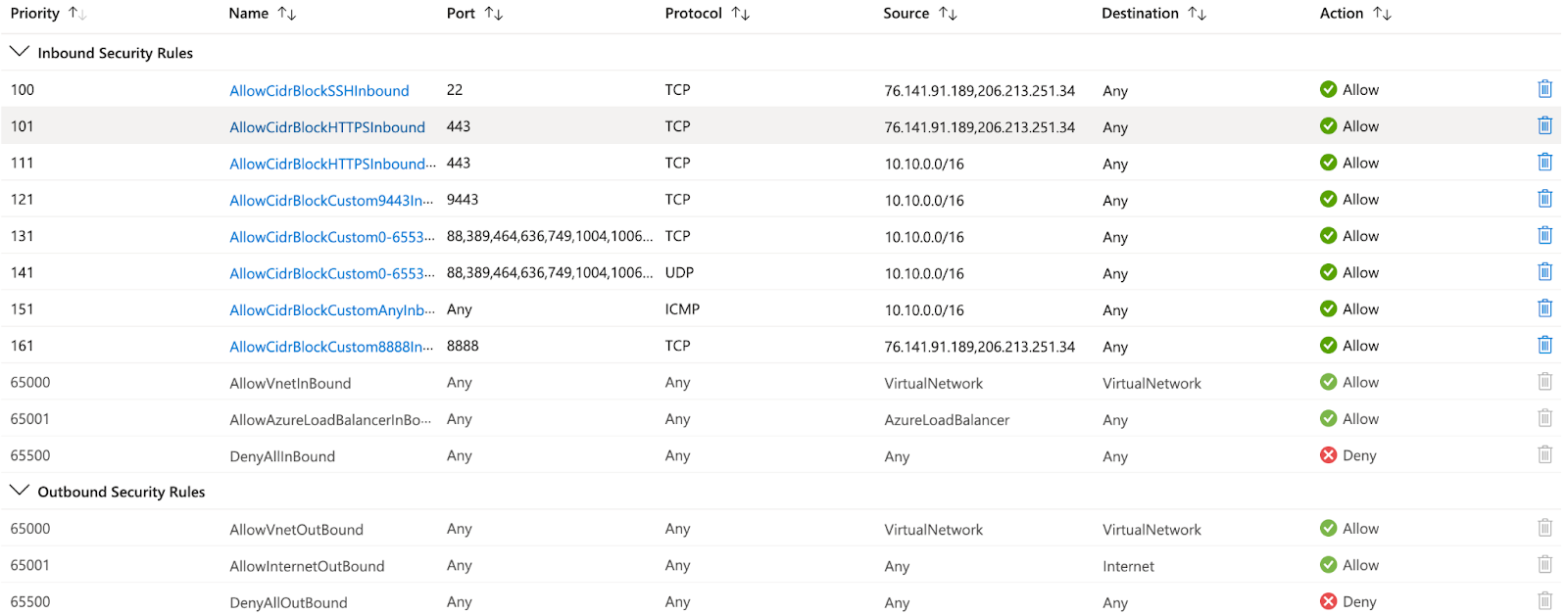
Figure 2 - Inbound User Security Rules
There are times when User Rules can be overly permissive, even if Source/Destination is restricted by IP Address or IP Network Range. Figure 2 shows that 151 priority has an "Any" port, while all other rules have "Any" as the Destination, which is open to all network ranges. If the network team is uncertain about which ports/protocols/destinations/sources and destinations can be used between virtual machine networks, then micro-segmentation and permissive rules must be implemented.
Micro-Segmentation
Segmentation in the public cloud refers to the practice of dividing and isolating different components of a network or infrastructure to enhance security and control. It involves implementing various measures to prevent unauthorized access and restrict communication between different resources within the cloud environment. Network Security Groups (NSGs) are a fundamental tool for achieving segmentation in Azure virtual networks.
Here's how NSGs work in the context of segmentation in the public cloud:
Filtering inbound traffic: NSGs allow you to define inbound security rules that specify the allowed sources, protocols, ports, and destinations for incoming network traffic. By configuring these rules, you can restrict access to specific resources within your virtual network, such as virtual machines or applications. This helps protect sensitive data and prevents unauthorized access.
Filtering outbound traffic: Similarly, NSGs enable you to define outbound security rules that control the flow of traffic leaving your virtual network. This allows you to restrict outgoing connections from specific resources or limit them to specific destinations, ports, or protocols. By implementing outbound rules, you can prevent data exfiltration and control the communication channels utilized by your resources.
Traffic isolation: NSGs can be applied at the subnet level, allowing you to segment different parts of your virtual network. By associating NSGs with subnets, you can enforce specific security policies for each subnet, controlling the traffic between them. This enables you to create secure zones within your network, isolating different applications or tiers of your infrastructure.
Network-level monitoring and logging: NSGs provide the ability to monitor and log network traffic. Azure provides diagnostic logging capabilities for NSGs, allowing you to capture and analyze network flow logs. By examining these logs, you can gain insights into network activity, identify potential security threats, and troubleshoot connectivity issues.
By leveraging NSGs for network traffic filtering, Azure users can establish a strong foundation for segmentation in their public cloud environments. NSGs provide a flexible and scalable solution for enforcing security policies, controlling network traffic, and achieving granular isolation between resources. However, it's important to note that NSGs are just one component of a comprehensive security strategy, and additional security measures, such as network virtual appliances, intrusion detection systems, or secure gateways, may be necessary depending on specific requirements and compliance standards.
Benefits of Micro-Segmentation and Permissive Rule Checks
Micro-segmentation, achieved through proper configuration of NSG rules, provides several benefits in terms of network security:
- Enhanced Security: Micro-segmentation allows fine-grained control over network traffic, enabling organizations to restrict communication between resources based on specific rules. This helps prevent lateral movement within a network and limits the potential impact of a security breach.
- Improved Compliance: By implementing permissive rule checks, organizations can ensure that their NSGs comply with security best practices and regulatory requirements. This helps maintain a secure and compliant network infrastructure.
- Minimized Attack Surface: Micro-segmentation reduces the attack surface by limiting communication pathways between resources. It prevents unauthorized access and restricts the movement of malicious actors within the network.
- Simplified Network Management: Using Apache Spark for permission checks enables organizations to automate the analysis and monitoring of NSG rules, reducing the manual effort required for security audits. The distributed computing capabilities of Apache Spark enable efficient processing of large datasets, making it suitable for organizations with complex network infrastructures.
- Rapid Detection and Response: Micro-segmentation, coupled with permissive rule checks, enables organizations to quickly identify and respond to any unauthorized or suspicious network traffic. By analyzing the NSG logs and validating the rules, potential security incidents can be detected promptly.
Network Security Flow Events and Logging
Network security groups flow logging is a feature of Azure Network Watcher that allows you to log information about IP traffic flowing through a network security group. Flow data is sent to Azure Storage, from where you can access it and export it to any visualization tool, security information and event management (SIEM) solution, or intrusion detection system (IDS) of your choice.
It's vital to monitor, manage, and know your network so that you can protect and optimize it. You need to know the current state of the network, who's connecting, and where users are connecting from. You also need to know which ports are open to the internet, what network behavior is expected, what network behavior is irregular, and when sudden rises in traffic happen. Flow logs are the source of truth for all network activity in your cloud environment. Whether you're in a startup that's trying to optimize resources or a large enterprise that's trying to detect intrusion, flow logs can help. You can use them for optimizing network flows, monitoring throughput, verifying compliance, detecting intrusions, and more. Here we are going to use Network Flow events to identify unknown or undesired traffic and identify the top talker in your network and remove overly permissive or restrictive traffic rules.
NSG Log Schema
We can start the PySpark code by defining the schema for NSG logs, which includes fields like category, macAddress, operationName, properties, resourceId, systemId, and time. This schema structure helps organize and process the log data efficiently.
insightsNeworkFlowEventsSchema = StructType() \
.add("records", ArrayType(StructType() \
.add("category", StringType(), True) \
.add("macAddress", StringType(), True) \
.add("operationName", StringType(), True) \
.add("properties", StructType()\
.add("Version", LongType(), True) \
.add("flows", ArrayType(StructType() \
.add("flows", ArrayType(StructType() \
.add("flowTuples", ArrayType(StringType(), True)) \
.add("mac", StringType(), True)\
, True))\
.add("rule", StringType(), True) \
), True)) \
.add("resourceId", StringType(), True) \
.add("systemId", StringType(), True) \
.add("time", StringType(), True) \
, True))For more details about Azure NSG Flow Events, please refer to this website.
To create the right permissive rules, I chose the following parameters from the Network Security Group.
- Resource ID or SystemID as one of the primary Key
- Rule Name, which is under Properties → Flows → Rule
- FlowTuples, which is under Properties → Flows → Flows → FlowTuples
NSG Flow stores the flow events as JSON files which looks like below.
{"records":[{"time":"2023-01-26T17:30:53.8518900Z","systemId":"57785417-608e-4bba-80d6-25c3a0ebf423","macAddress":"6045BDA85225","category":"NetworkSecurityGroupFlowEvent","resourceId":"/SUBSCRIPTIONS/DA35404A-2612-4419-BAEF-45FCDCE6045E/RESOURCEGROUPS/ROHNU-RESOURCES/PROVIDERS/MICROSOFT.NETWORK/NETWORKSECURITYGROUPS/CVS-NSGLOGS-NSG","operationName":"NetworkSecurityGroupFlowEvents","properties":{"Version":2,"flows":[{"rule":"DefaultRule_DenyAllInBound","flows":[{"mac":"6045BDA85225","flowTuples":["1674754192,185.156.73.107,10.27.0.4,54227,46988,T,I,D,B,,,,","1674754209,185.156.73.150,10.27.0.4,43146,62839,T,I,D,B,,,,","1674754210,185.156.73.91,10.27.0.4,58965,63896,T,I,D,B,,,,","1674754212,89.248.163.30,10.27.0.4,52429,41973,T,I,D,B,,,,","1674754223,87.246.7.70,10.27.0.4,43000,8443,T,I,D,B,,,,","1674754236,92.255.85.15,10.27.0.4,41014,8022,T,I,D,B,,,,"]}]}]}},{"time":"2023-01-26T17:31:53.8673108Z","systemId":"57785417-608e-4bba-80d6-25c3a0ebf423","macAddress":"6045BDA85225","category":"NetworkSecurityGroupFlowEvent","resourceId":"/SUBSCRIPTIONS/DA35404A-2612-4419-BAEF-45FCDCE6045E/RESOURCEGROUPS/ROHNU-RESOURCES/PROVIDERS/MICROSOFT.NETWORK/NETWORKSECURITYGROUPS/CVS-NSGLOGS-NSG","operationName":"NetworkSecurityGroupFlowEvents","properties":{"Version":2,"flows":[{"rule":"DefaultRule_AllowInternetOutBound","flows":[{"mac":"6045BDA85225","flowTuples":["1674754265,10.27.0.4,20.44.10.123,49909,443,T,O,A,B,,,,","1674754265,10.27.0.4,52.152.108.96,49910,443,T,O,A,B,,,,","1674754267,10.27.0.4,52.152.108.96,49911,443,T,O,A,B,,,,","1674754267,10.27.0.4,20.44.10.123,49912,443,T,O,A,B,,,,","1674754268,10.27.0.4,52.185.211.133,49913,443,T,O,A,B,,,,","1674754268,10.27.0.4,20.44.10.123,49914,443,T,O,A,B,,,,","1674754271,10.27.0.4,20.44.10.123,49909,443,T,O,A,E,1,66,1,66","1674754271,10.27.0.4,52.152.108.96,49910,443,T,O,A,E,24,12446,1,66","1674754273,10.27.0.4,20.44.10.123,49912,443,T,O,A,E,15,3542,12,5567","1674754274,10.27.0.4,52.185.211.133,49913,443,T,O,A,E,12,1326,10,4979","1674754277,10.27.0.4,20.44.10.123,49914,443,T,O,A,E,13,2922,14,5722","1674754278,10.27.0.4,23.0.198.228,49916,443,T,O,A,B,,,,","1674754279,10.27.0.4,104.102.142.78,49918,443,T,O,A,B,,,,","1674754279,10.27.0.4,104.102.142.78,49917,443,T,O,A,B,,,,","1674754280,10.27.0.4,13.107.4.50,49919,80,T,O,A,B,,,,","1674754280,10.27.0.4,13.107.4.50,49920,80,T,O,A,B,,,,","1674754280,10.27.0.4,13.107.4.50,49921,80,T,O,A,B,,,,","1674754280,10.27.0.4,13.107.4.50,49922,80,T,O,A,B,,,,","1674754281,10.27.0.4,52.152.108.96,49911,443,T,O,A,E,87,11226,1093,1613130","1674754284,10.27.0.4,104.208.16.88,49923,443,T,O,A,B,,,,","1674754284,10.27.0.4,20.72.205.209,49924,443,T,O,A,B,,,,","1674754289,10.27.0.4,13.107.4.50,49925,80,T,O,A,B,,,,","1674754290,10.27.0.4,104.208.16.88,49923,443,T,O,A,E,14,2877,13,5627","1674754291,10.27.0.4,20.72.205.209,49924,443,T,O,A,E,12,1452,10,4692","1674754300,10.27.0.4,20.50.80.209,49927,443,T,O,A,B,,,,","1674754306,10.27.0.4,20.50.80.209,49927,443,T,O,A,E,10,3220,9,5415"]}]},{"rule":"DefaultRule_DenyAllInBound","flows":[{"mac":"6045BDA85225","flowTuples":["1674754254,89.248.165.197,10.27.0.4,46050,41834,T,I,D,B,,,,","1674754255,45.143.200.102,10.27.0.4,44049,49361,T,I,D,B,,,,","1674754263,51.91.172.152,10.27.0.4,53162,5985,T,I,D,B,,,,","1674754297,122.116.9.72,10.27.0.4,58757,23,T,I,D,B,,,,"]}]}]}}]}Enable Network Security Group Logging
Network Watcher in Azure stores NSG Flow events in an Azure Storage account using the diagnostic settings feature. When enabled, diagnostic settings allow the Network Watcher to send NSG Flow events to a specified storage account for retention and analysis. The NSG Flow events are stored in the storage account in the form of log files. Each log file contains information about the network flows captured by the Network Watcher, including source and destination IP addresses, ports, protocols, timestamps, and action (allow/deny). The storage account can be configured to store NSG Flow events in a specific container within the storage account. The log files are typically stored in the Azure Blob storage service, which provides scalable and durable storage for unstructured data. By leveraging the diagnostic settings and Azure Storage account, organizations can effectively collect and retain NSG Flow events for analysis, monitoring, and compliance purposes. This data can then be used for various security and network analysis scenarios to gain insights into network traffic patterns and identify potential security threats or anomalies.
Note: I strongly recommend creating an ADLS Gen2 Storage account to store the NSG Flow Events with at least 7 days retention policy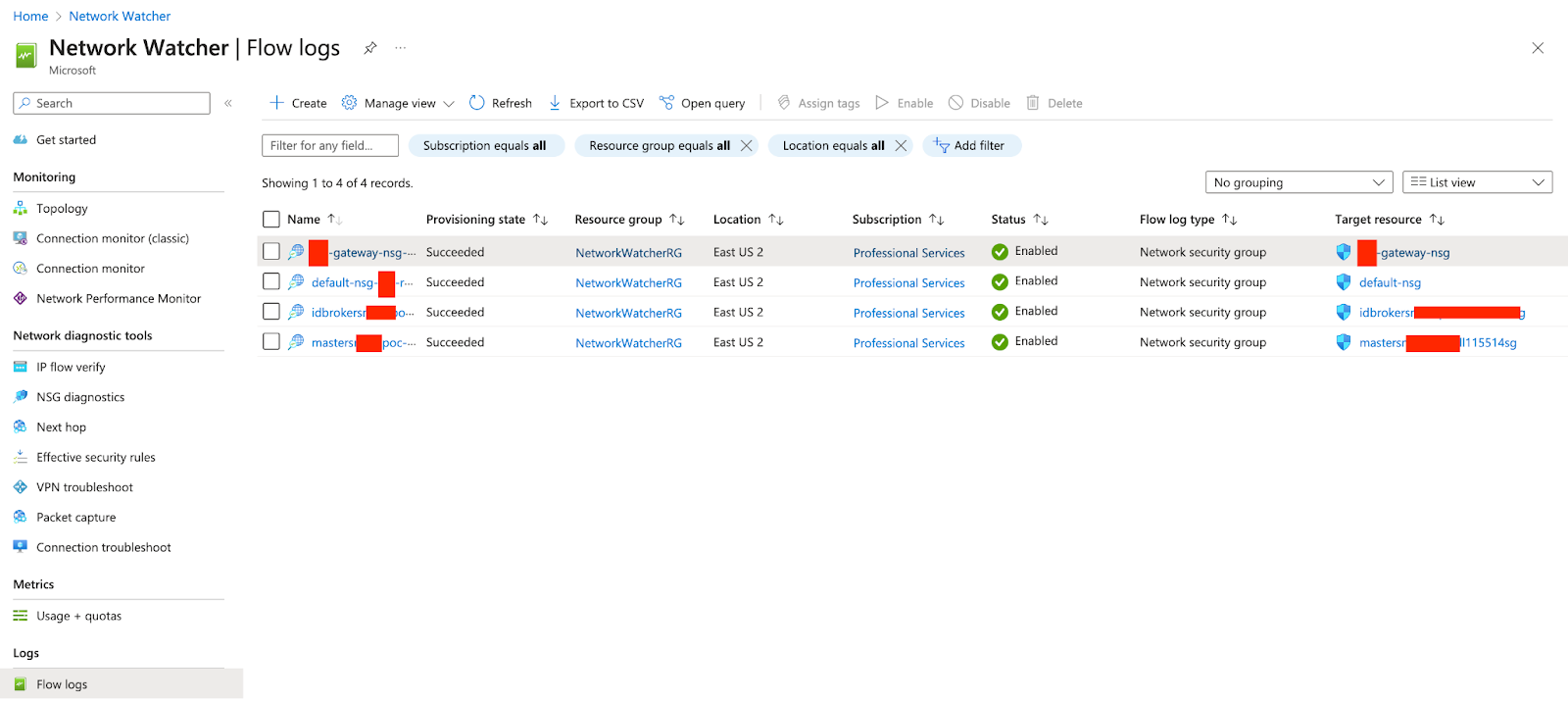
Figure 3 - Enable NSG Flow logging using Network Watcher
The directory structure of NSG Flow events stored in an Azure Storage account typically follows a hierarchical organization. Here is an example of a possible directory structure:
abfs://insights-logs-networksecuritygroupflowevent@<storageaccount>.dfs.core.windows.net/resourceId=/SUBSCRIPTIONS/<Subscriptions>/RESOURCEGROUPS/<ResourceGroups>/PROVIDERS/MICROSOFT.NETWORK/NETWORKSECURITYGROUPS/<NetworkSecurityGroup>/y={year}/m={month}/d={day}/h={hours}/m=00/mac={macID}/PT1H.json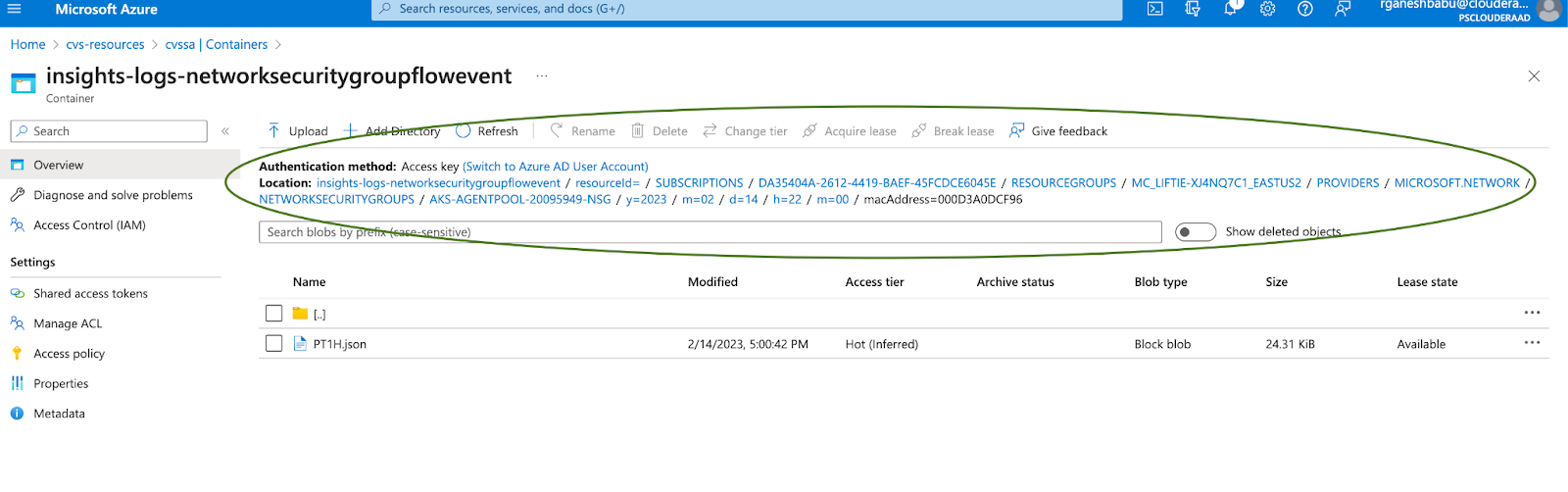
Figure 4 - Directory structure of the NSG flow events
The storage account serves as the top-level container for storing different types of data. Within the storage account, a container is created with the name “” to hold the NSG Flow event logs specifically. The NSG Flow events are then organized based on the subscriptions, resource groups, and network security groups of when they were captured. The logs are typically organized in a hierarchical manner, starting from the year, followed by the month, day, and hour of capture. Under each hour directory, the NSG Flow event log files are stored as PT1H.json under the MAC address. These log files contain the actual captured network flow data, usually in a structured format such as JSON. This directory structure allows for easy organization and retrieval of NSG Flow events based on the specific time period when the events occurred. It enables efficient querying and analysis of the logs based on the desired time range or granularity.
How To Read NSG Flow Files Using Pyspark
Below provided code is written in Python and utilizes Apache Spark to read and process NSG (Network Security Group) Flow logs stored in Azure Blob Storage. The code leverages Apache Spark’s distributed computing capabilities to handle large datasets efficiently and perform the required calculations in a parallelized manner. It utilizes Spark SQL functions and operations to manipulate and analyze the data effectively. Let's break down the code step by step:
Spark Configuration
SparkConf()creates a Spark configuration object.- .
setAppName(appName)sets the name of the Spark application. .setAll([...])sets additional configuration properties for Spark, such as enabling case sensitivity in SQL queries, setting the number of shuffle partitions, and specifying the SAS (Shared Access Signature) token for accessing the Azure Blob Storage.
Spark Session and Spark Context
- SparkSession.builder creates a
SparkSession, which is the entry point for working with structured data in Spark. .config(conf=sparkConf)applies the previously defined Spark configuration..getOrCreate()retrieves an existing SparkSession or creates a new one if none exists.spark.sparkContextgets the Spark Context (sc) from the SparkSession.
Hadoop File System Configuration
sc._gateway.jvmprovides access to the Java Virtual Machine (JVM) running Spark.java.net.URI, org.apache.hadoop.fs.Path,org.apache.hadoop.fs.FileSystem, andorg.apache.hadoop.conf.Configurationare Java classes used for working with Hadoop Distributed File System (HDFS).sc._jsc.hadoopConfiguration().set(...)sets the SAS token for accessing the Azure Blob Storage in the Hadoop configuration.
One of the Options to Access NSG Flow Logs at the Subscription Level i.e. Option 1
fs = FileSystem.get(...)creates aFileSystemobject to interact with the Azure Blob Storage.fs.listStatus(Path("/resourceId=/SUBSCRIPTIONS/"))retrieves the status offiles/directories in the specified path ("/resourceId=/SUBSCRIPTIONS/").- The code then iterates through the files and directories to construct the NSG Flow Logs' paths based on the subscription, resource group, and date.
- The NSG Flow Logs' paths are stored in a dictionary (NSGDict) for further processing.
print(NSGStatus)is outside the loop and represents the last value of NSGStatus. It will print the NSG Flow Log path for the most recent subscription, resource group, and date.
Another Option Is to Access NSG Flow Logs Entirely
- Option 2 provides an alternative option for reading NSG logs at once using a regular expression with "*." It constructs a path pattern with placeholders for subscription, resource group, date, and hour.
from pyspark.sql import SparkSession
from pyspark.conf import SparkConf
# Create Spark configuration
spark_conf = SparkConf() \
.setAppName(app_name) \
.setAll([
('spark.sql.caseSensitive', 'true'),
('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container, blob_account), blob_sas_token),
("spark.sql.shuffle.partitions", "300"),
("spark.default.parallelism", "300")
])
# Create Spark session
spark = SparkSession.builder.config(conf=spark_conf).getOrCreate()
sc = spark.sparkContext
# Set Hadoop configuration for Azure Blob Storage
sc._jsc.hadoopConfiguration().set('fs.azure.sas.%s.%s.dfs.core.windows.net' % (blob_container, blob_account), blob_sas_token)
# OPTION 1 - Read the NSG Flow Logs at subscription level and create dictionary
URI = sc._gateway.jvm.java.net.URI
Path = sc._gateway.jvm.org.apache.hadoop.fs.Path
FileSystem = sc._gateway.jvm.org.apache.hadoop.fs.FileSystem
Configuration = sc._gateway.jvm.org.apache.hadoop.conf.Configuration
fs = FileSystem.get(URI.create("abfs://insights-logs-networksecuritygroupflowevent@storage_account.dfs.core.windows.net"), Configuration())
status = fs.listStatus(Path("/resourceId=/SUBSCRIPTIONS/"))
nsg_dict = dict()
for file_status in status:
subscription_name = str(file_status.getPath().getName())
resource_group_path = "/resourceId=/SUBSCRIPTIONS/"+subscription_name+"/RESOURCEGROUPS/*/PROVIDERS/MICROSOFT.NETWORK/NETWORKSECURITYGROUPS/"
resource_group_status = fs.globStatus(Path(resource_group_path+"*/"))
for resource_group_file in resource_group_status:
nsg_path = str(resource_group_file.getPath())
nsg_status = nsg_path + f"/y={year}/m={month}/d={day}"
if fs.exists(Path(nsg_status)):
if subscription_name in nsg_dict:
nsg_dict[subscription_name].extend([nsg_status])
else:
nsg_dict[subscription_name] = [nsg_status]
print(nsg_status)
# OPTION 2 - Read all the NSG logs at once with "*" Regular expression like below
value = "abfs://insights-logs-networksecuritygroupflowevent@<storage_account>.dfs.core.windows.net/resourceId=/SUBSCRIPTIONS/*/RESOURCEGROUPS/*/PROVIDERS/MICROSOFT.NETWORK/NETWORKSECURITYGROUPS/*/y={year}/m={month}/d={day}/h={hours}"
key = "All_Subscriptions"To determine when to use Option 1 or Option 2 for reading NSG flow logs, you can consider the following factors:
Number of Subscriptions:
- Option 1 is recommended when the number of subscriptions in Azure is quite high.
- In this case, Option 1 allows you to process the NSG logs in parallel using multithreading, utilizing the full processing power of your system.
- The code snippet you provided utilizes the
multiprocessing.pool.ThreadPoolto create a pool of threads (75 in this case) and processes each subscription in parallel. - This approach helps in distributing the workload across multiple threads and improves overall processing efficiency.
Total Size of NSG Flow Events:
- Option 1 is also preferable when the total size of the NSG flow events per day is quite high.
- By utilizing multithreading, you can process multiple NSG logs concurrently, reducing the overall processing time.
- This is particularly beneficial when dealing with large amounts of data, as it allows for parallel processing and efficient utilization of system resources.
import concurrent.futures
def parallel(x):
try: value =nsg_dict[x]
key = x print("Subscriptions:", key)
processNSGRule(value, key)
except Exception as e: print(e)
with concurrent.futures.ThreadPoolExecutor(max_workers=75) as executor: executor.map(parallel,nsg_dict)Simplicity and Resource Constraints:
- Option 2 is recommended when the number of subscriptions is manageable and the total size of NSG flow events per day is relatively small.
- Option 2 involves reading the entire NSG log file at once with a single read operation, making it a straightforward and simpler approach.
- This approach is suitable when resource constraints or processing time are not major concerns.
In summary, if you have a large number of subscriptions in Azure or the total size of NSG flow events per day is significant, Option 1, using parallel processing with multithreading, is recommended. This allows for efficient utilization of system resources and faster processing. On the other hand, if the number of subscriptions is manageable and the total size of NSG flow events is relatively small, Option 2 provides a simpler and straightforward approach.
Load the NSG Flow File
Once the files and directories from the storage account are retrieved, the next step is to load them into Spark as a dataframe. In the provided code snippet, therecursiveFileLookup option is used, which means that Spark will traverse through directories called "hour," "minute," and "macAddress" within the file path even after reaching the "day" folder.
When loading JSON files into Spark, the inferSchema option is enabled by default. This allows Spark to analyze the JSON files and automatically infer the schema while loading them into a dataframe. However, there are some downsides to using inferSchema.One downside is that Spark needs to read each file to analyze its schema before loading it. This process can have a significant impact on the performance of Spark, especially when dealing with a large number of files or large file sizes. Reading and analyzing the schema of each file individually can be time-consuming and resource-intensive.
To overcome this, it is strongly recommended to provide a predefined schema while loading the JSON files into Spark. By providing a schema, Spark can bypass the schema inference step and directly load the files based on the provided schema. This approach improves the performance of Spark by eliminating the need for schema analysis for each file. Creating a schema for the JSON files can be done manually by defining the structure and data types of the JSON fields. This can be achieved using the StructType and StructField classes in Spark. Once the schema is defined, it can be passed to the spark.read.json() method as an argument, ensuring that Spark uses the predefined schema for loading the files. Please refer NSG Log Schema Section. By providing a predefined schema, Spark can efficiently load the JSON files as dataframes without the overhead of schema inference. This approach enhances the performance of Spark, especially when dealing with large volumes of data. Additionally, it provides better control over the schema and ensures consistency in the data structure, improving the reliability of subsequent data processing and analysis tasks.
spark.read.option("recursiveFileLookup","true").format("json").schema(insightsNeworkFlowEventsSchema).load(FILE_LOCATION)Parsing the NSG Flow Events JSON File
The provided code defines a function called NSGruleDef that processes NSG (Network Security Group) flow logs using Spark DataFrames. Let's break down the code step by step:
Loading NSG Flow Logs:
spark.read.option("recursiveFileLookup", "true")sets the recursive file lookup option to enable traversal through nested directories..format("json")specifies that the files being loaded are in JSON format..schema(insightsNeworkFlowEventsSchema)specifies the predefined schema(insightsNeworkFlowEventsSchema)to be used while loading the JSON files..load(filepath)loads the JSON files from the providedfilepathinto a DataFrame calledloadNSGDF.
Exploding Nested Structures:
explodeNSGDF = loadNSGDF.select(explode("records").alias("record"))uses the explode function to flatten the nested records structure withinloadNSGDFDataFrame. Each record is treated as a separate row inexplodeNSGDF.parsedNSGDF = explodeNSGDF.select(col("record.resourceId").alias("resource_id"),col("record.properties").getField("flows").alias("flows"))extracts specific columns fromexplodeNSGDF, including resourceId and flows (which represent the flow data).
Exploding Flow Tuples:
explodeFlowsDF = parsedNSGDF.withColumn("flow", explode("flows")).select("resource_id", col("flow.rule").alias("rule_name"), col("flow.flows.flowTuples").alias("flow_tuples"))uses the explode function again to expand the flows column into multiple rows, creating a new column called flow. It also selects theresource_id,rule_name, andflow_tuplescolumns.
Filtering NSG Allow Rules:
filterNSGAllowDF = explodeFlowsDF.where(~col('rule_name').contains('Deny'))filters out the rows where therule_namecolumn does not contain the string'Deny'. This step retains only the rows representing allowed (non-denied) rules.
Please note that in order to effectively manage permissive rules of the network Security group, in our case, we propose the rules to be set only for the Allowed Inbound and Outbound Rules within the network Security group. Thus, we ignore denied rules in this case.Exploding Flow Tuples:
explodeFlowTuplesDF = filterNSGAllowDF.select("resource_id", "rule_name", explode(col("flow_tuples")).alias("flow_rules"))further expands theflow_tuplescolumn into separate rows using the explode function. It creates a new DataFrame calledexplodeFlowTuplesDFwith columnsresource_id,rule_name, andflow_rules.
Grouping Flow Tuples:
groupFlowTuplesDF = explodeFlowTuplesDF.groupBy("resource_id", "rule_name").agg(collect_set("flow_rules").alias("collect_flow_tuples")
def processNSGRule(filepath, subscription):
loadNSGDF = spark.read.option("recursiveFileLookup", "true").format("json").schema(insightsNeworkFlowEventsSchema).load(filepath)
explodeNSGDF = loadNSGDF.select(explode("records").alias("record"))
parsedNSGDF = explodeNSGDF.select(col("record.resourceId").alias("resource_id"), col("record.properties").getField("flows").alias("flows"))
explodeFlowsDF = parsedNSGDF.withColumn("flow", explode("flows")).select("resource_id", col("flow.rule").alias("rule_name"), col("flow.flows.flowTuples").alias("flow_tuples"))
filterNSGAllowDF = explodeFlowsDF.where(~col('rule_name').contains('Deny'))
explodeFlowTuplesDF = filterNSGAllowDF.select("resource_id", "rule_name", explode(col("flow_tuples")).alias("flow_rules"))
groupFlowTuplesDF = explodeFlowTuplesDF.groupBy("resource_id", "rule_name").agg(collect_set("flow_rules").alias("collect_flow_tuples"))
collectFlowTuplesDF = groupFlowTuplesDF.select("system_id", "rule_name", collect_arrays_udf("collect_flow_tuples").alias("flow_rules")).select("resource_id", "rule_name", "flow_rules")Selecting Columns and Applying UDF:
groupFlowTuplesDF.select("system_id", "rule_name", collect_arrays_udf("collect_flow_tuples").alias("flow_rules"))selects the columnssystem_id,rule_name, andcollect_flow_tuplesfrom thegroupFlowTuplesDFDataFrame.collect_arrays_udfrefers to a user-defined function (UDF) that takes thecollect_flow_tuplescolumn as input and merges multiple arrays into one array. The UDF aggregates the elements of thecollect_flow_tuplescolumn into an array or list structure. The resulting column is then aliased asflow_rules.
Selecting Final Columns:
.select("resource_id", "rule_name", "flow_rules")selects the columnsresource_id,rule_name, andflow_rulesfrom the intermediate DataFrame.- This step ensures that the final DataFrame, named
collectFlowTuplesDF, contains the desired columns for further processing or analysis.
from pyspark.sql.functions import udf
from pyspark.sql.types import ArrayType, StringType
def collect_arrays(list_array):
collect_array = []
for i in range(len(list_array)):
collect_array.extend(list_array[i])
return collect_array
collect_arrays_udf = udf(collect_arrays, ArrayType(StringType()))The code processes the NSG flow logs, extracts relevant information, and transforms the data into a structured format using Spark DataFrames. The resulting DataFrame, collectFlowTuplesDF, contains the resource ID, rule name, and the corresponding flow rules for each NSG.
NSG Data Transformation in Spark
Network Security Group Data is loaded as a Spark DataFrame with multiple records. Each record in the DataFrame contains information about a network security group and its respective rules and flowtuples. To process this data effectively, the records are split into three columns: resourceID, ruleName, and flowTuples, following the parsing format for NSG flow events. This step allows for easier analysis and manipulation of the data. To combine the flowTuples belonging to the same resourceID and ruleName into a single row, the groupBy operation is used on the DataFrame, grouping the data based on these two columns. This process may appear straightforward, but in Spark transformation, it actually creates partitions based on resourceID and ruleName. In essence, the groupBy operation performs a similar function to the repartition (resourceID, ruleName) operation in Spark.
Using groupBy has its advantages and disadvantages. Let's start with the positive aspects. If the NSG user rules and default rules are evenly distributed and created with less permissiveness from the beginning, then there won't be any major issues. The groupBy operation will successfully combine the flowTuples for each resourceID and ruleName, resulting in the desired output.
However, there are negative aspects to consider when using groupBy. One of the main concerns is that it can create uneven partitions, leading to data skew. Data skew occurs when the distribution of data across partitions is not balanced, causing certain partitions to contain significantly more data than others. This can have a negative impact on the performance of Spark jobs, as some partitions may take longer to process, resulting in a bottleneck. In some cases, the data skew can be severe enough that a Spark executor exceeds the maximum buffer size allowed by the Kyro serializer, which is typically set to 2GB. When this happens, the job fails to execute successfully. To avoid such failures, it is crucial to carefully analyze the data and determine whether using groupBy is the best approach.
Data Skew
Spark data skew refers to an imbalance in the distribution of data across partitions when performing parallel processing in Apache Spark. This skew can occur when the data has a non-uniform distribution or when certain keys or values are disproportionately more common than others. This leads to some partitions processing much larger amounts of data than others, causing a performance bottleneck and hindering the efficiency of Spark computations.
To explain this concept visually, let's consider a simple example. Imagine we have a dataset of customer transactions, where each transaction is associated with a customer ID and a monetary value. We want to perform some aggregations on this dataset, such as calculating the total transaction amount for each customer.
In a distributed environment, the data is divided into multiple partitions, and each partition is processed independently by a worker node. In an ideal scenario, the data would be evenly distributed across partitions, as shown in the diagram below:
Partition 1: [Customer1, Customer2, Customer3, Customer4]
Partition 2: [Customer5, Customer6, Customer7, Customer8]
In this balanced scenario, each partition contains an equal number of customers, and the processing is distributed evenly across the worker nodes, resulting in optimal performance.
However, in the case of data skew, the distribution is imbalanced, as illustrated in the diagram below:
Partition 1: [Customer1, Customer2, Customer3, Customer4, Customer5, Customer6]
Partition 2: [Customer7, Customer8]
In this skewed scenario, Partition 1 has a significantly larger number of customers compared to Partition 2. As a result, the worker processing Partition 1 will have a heavier workload, while the worker processing Partition 2 will finish its task much faster. This imbalance leads to a performance bottleneck, as the overall processing time is determined by the slowest worker. To address data skew, Spark provides techniques such as data repartitioning, which redistributes the data across partitions in a more balanced manner. For example, one could use a technique like salting, where a random value is added as a prefix to the key (in this case, the customer ID) to ensure a more uniform distribution of data across partitions. By achieving a balanced data distribution across partitions, Spark can leverage the full parallel processing capabilities of the cluster, improving overall performance and eliminating bottlenecks caused by data skew.
Now we understand what data skew is and how it impacts NSG Data analysis. When we do not use groupBy, the output can be noticeably different. If the groupBy operation is omitted, the result will contain less permissive rules, as they won't be consolidated. To consolidate the rules again, a different script would be required. Alternatively, a weekly or monthly consolidation script can be implemented to overcome this problem and ensure that the rules are appropriately combined. While the process of loading NSG Data as a Spark DataFrame and using groupBy to combine flowTuples appears simple, it involves partitioning the data based on resourceID and ruleName. The use of groupBy can have positive implications when the NSG rules are evenly distributed and less permissive. However, it can also lead to uneven partitions and data skew, potentially causing Spark executor failures. It is crucial to analyze the data and determine whether using groupBy is the most suitable approach, considering the potential downsides and exploring alternative consolidation strategies if necessary.
Core UDFs and Functions To Define NSG Rules
The code includes several user-defined functions (UDFs), and helper functions to perform specific tasks. These functions include:
validateIPv4Address
The function mentioned checks whether an IP address is a valid IPv4 address. It is important to verify if an IP address is in the IPv4 format because the NSG rule mentioned in the code specifically works with IPv4 addresses. Here is an explanation of how the function performs this check:
from ipaddress import IPv4Address
def validateIPv4Address(ipv4string):
try:
ip_object = IPv4Address(ipv4string)
return True
except ValueError:
return FalseExplanation of the function:
- The function
is_valid_ipv4_addresstakes anip_addressas input. - To
validate IPv4Addresses, I used ipaddress module, developed in Python3.6. Some modules are already installed, such as ipaddress. - The function returns False if the IP address check throws an error or fails.
- The function returns True if the checks are passed, and the IP address provided is valid IPv4.
check_subnet
The provided code defines a function called check_subnetthat determines the IP network range based on the octets of the destination IP address. Here is a detailed explanation of how the function works:
def check_subnet(dest_four, dest_three, dest_two, dest_one, dest_ip):
"""
check_subnet function checks each destination IP based on the length of four/three/two/one octet destination IP list,
and returns the destination IP network ranges.
:param dest_four: Number of four octets in the destination IP address
:param dest_three: Number of three octets in the destination IP address
:param dest_two: Number of two octets in the destination IP address
:param dest_one: Number of one octets in the destination IP address
:param dest_ip: Destination IP address
:return: Destination IP network range
"""
if dest_four <= 10:
destination = f"{dest_ip}/32"
elif dest_three <= 10:
dest_ip_part = dest_ip.split(".")
dest_ip = ".".join(dest_ip_part[:3])
destination = f"{dest_ip}.0/24"
elif dest_two <= 10:
dest_ip_part = dest_ip.split(".")
dest_ip = ".".join(dest_ip_part[:2])
destination = f"{dest_ip}.0.0/16"
elif dest_one <= 10:
dest_ip_part = dest_ip.split(".")
dest_ip = ".".join(dest_ip_part[:1])
destination = f"{dest_ip}.0.0.0/8"
else:
destination = "0.0.0.0/0"
return destinationExplanation of the function:
The function then checks the number of octets in the destination IP address against certain thresholds to determine the appropriate IP network range.
Note: In this example, I used 10 as the length of the IP address in order to check, but we can define it according to our needs.- If the number of four octets (
dest_four) is less than or equal to 10, it means the destination IP address has a length of four octets, and the network range is set to the destination IP address with a subnet mask of /32 (indicating a single IP address). - If the number of three octets (
dest_three) is less than or equal to 10, it means the destination IP address has a length of three octets. The function splits the destination IP address by the dot ('.') separator and joins the first three octets together. The network range is set to this joined IP address with a subnet mask of /24 (indicating a range of 256 IP addresses). - If the number of two octets (
dest_two) is less than or equal to 10, it means the destination IP address has a length of two octets. Similarly, the function joins the first two octets of the destination IP address and sets the network range to this joined IP address with a subnet mask of /16 (indicating a range of 65,536 IP addresses). - If the number of one octet (
dest_one) is less than or equal to 10, it means the destination IP address has a length of one octet. The function joins the first octet of the destination IP address and sets the network range to this joined IP address with a subnet mask of /8 (indicating a range of 16,777,216 IP addresses). - If none of the above conditions are met, it means the destination IP address does not fall into any specific length category, and the network range is set to the default value of 0.0.0.0/0 (indicating all IP addresses).
Finally, the function returns the determined destination IP network range. By using this function, you can determine the appropriate IP network range based on the length of the destination IP address in octets.
group_ip_network
This function groups source and destination IP addresses into their respective IP networks and combines them with source ports, destination ports, and protocols. The provided code defines a function called group_ip_network that processes a list of flow tuples related to a network security group (NSG). The function converts source IP addresses and destination IP addresses into source networks and destination networks. It also combines them with source ports, destination ports, and protocols. Here's an explanation of how the function works:
- The function initializes several empty sets, and a dictionary called
ip_network_dictto store the IP network ranges. - It iterates over each flow tuple in the
flow_listparameter. - Within the loop, the function performs the following actions for each flow tuple:
- Adds the tuple's source and destination IP addresses as
four-octetvalues to thefour_octets_listset. - Splits the source and destination IP addresses by the dot ('.') separator and adds the three-octet values to the respective sets (
source_three_octetsanddest_three_octets). - Adds the combination of the source
three-octetIP address, destination IP address, source port, destination port, and protocol as a tuple to thethree_octets_listset. - Similar actions are performed for
two-octetandone-octetvalues, adding them to their respective sets (source_two_octets,dest_two_octets,two_octets_list,source_one_octets,dest_one_octets,one_octets_list). - The function then checks the lengths of the sets containing the different octet values of the source IP address (
source_four_octets,source_three_octets,source_two_octets,source_one_octets). - If the length of
source_four_octetsis less than or equal to 10, the function iterates over thefour_octets_listset and creates the destination IP network ranges using thecheck_subnetfunction. It combines the source network, destination network, source port, destination port, and protocol into a string (source) and stores it in theip_network_dictdictionary, where the source IP network range is the key, and the associated source ports are stored as a list. If the source IP network range already exists in the dictionary, the source ports are appended to the existing list. - Similar actions are performed for lengths of
source_three_octets,source_two_octets, andsource_one_octets. The appropriate subnet masks are used based on the length of the octets. - If none of the above conditions are met, it means the length of the source IP address does not fall into any specific length category. In this case, the function assigns a source IP network range of 0.0.0.0/0 (indicating all IP addresses).
- The function then joins the elements of the ip_network_dict dictionary into a list called
socket_range. Each element is a string consisting of the source IP network range, destination IP network range, source port, destination port, and protocol, separated by semicolons. - Finally, the function returns the
socket_rangelist, which contains the combined information of source IP network ranges, destination IP network ranges, ports, and protocols for each flow tuple.
In summary, the group_ip_network function processes flow tuples from a network security group and converts IP addresses into IP network ranges. It combines them with ports and protocols, storing the information in a dictionary and returning a list of strings representing the combined data for each flow tuple.
def group_ip_network(flow_list):
ip_network_dict = dict()
four_octets_set = set()
source_four_octets_set = set()
dest_four_octets_set = set()
source_three_octets_set = set()
dest_three_octets_set = set()
three_octets_set = set()
source_two_octets_set = set()
dest_two_octets_set = set()
two_octets_set = set()
source_one_octet_set = set()
dest_one_octet_set = set()
one_octet_set = set()
for ip in flow_list:
four_octets_set.add((ip[1], ip[2], ip[3], ip[4], ip[5], ip[6]))
source_ip_parts = ip[1].split(".")
destination_ip_parts = ip[2].split(".")
# Four Octet List of Source and Destination IP
source_four_octets_set.add(ip[1])
dest_four_octets_set.add(ip[2])
# Three Octet List of Source and Destination IP
source_three_octets_set.add(".".join(source_ip_parts[:3]))
dest_three_octets_set.add(".".join(destination_ip_parts[:3]))
three_octets_set.add((".".join(source_ip_parts[:3]), ip[2], ip[3], ip[4], ip[5], ip[6]))
# Two Octet List of Source and Destination IP
source_two_octets_set.add(".".join(source_ip_parts[:2]))
dest_two_octets_set.add(".".join(destination_ip_parts[:2]))
two_octets_set.add((".".join(source_ip_parts[:2]), ip[2], ip[3], ip[4], ip[5], ip[6]))
# One Octet List of Source and Destination IP
source_one_octet_set.add(".".join(source_ip_parts[:1]))
dest_one_octet_set.add(".".join(destination_ip_parts[:1]))
one_octet_set.add((".".join(source_ip_parts[:1]), ip[2], ip[3], ip[4], ip[5], ip[6]))
# If conditions check the length of four/three/two/one octets of source IP list
# If the length is less than or equal to 10, it returns Source IP network ranges
if len(source_four_octets_set) <= 10:
for four_octet in four_octets_set:
destination = check_subnet(len(dest_four_octets_set), len(dest_three_octets_set),
len(dest_two_octets_set), len(dest_one_octet_set), four_octet[1])
source = f"{four_octet[0]}/32;{destination};{four_octet[3]};{four_octet[4]};{four_octet[5]}"
s_port = four_octet[2]
if source in ip_network_dict:
ip_network_dict[source].extend([s_port])
else:
ip_network_dict[source] = [s_port]
elif len(source_three_octets_set) <= 10:
for three_octet in three_octets_set:
destination = check_subnet(len(dest_four_octets_set), len(dest_three_octets_set),
len(dest_two_octets_set), len(dest_one_octet_set), three_octet[1])
source = f"{three_octet[0]}.0/24;{destination};{three_octet[3]};{three_octet[4]};{three_octet[5]}"
s_port = three_octet[2]
if source in ip_network_dict:
ip_network_dict[source].extend([s_port])
else:
ip_network_dict[source] = [s_port]
elif len(source_two_octets_set) <= 10:
for two_octet in two_octets_set:
destination = check_subnet(len(dest_four_octets_set), len(dest_three_octets_set),
len(dest_two_octets_set), len(dest_one_octet_set), two_octet[1])
source = f"{two_octet[0]}.0/16;{destination};{two_octet[3]};{two_octet[4]};{two_octet[5]}"
s_port = two_octet[2]
if source in ip_network_dict:
ip_network_dict[source].extend([s_port])
else:
ip_network_dict[source] = [s_port]
elif len(source_one_octet_set) <= 10:
for one_octet in one_octet_set:
destination = check_subnet(len(dest_four_octets_set), len(dest_three_octets_set),
len(dest_two_octets_set), len(dest_one_octet_set), one_octet[1])
s_port = one_octet[2]
source = f"{one_octet[0]}.0/8;{destination};{one_octet[3]};{one_octet[4]};{one_octet[5]}"
if source in ip_network_dict:
ip_network_dict[source].extend([s_port])
else:
ip_network_dict[source] = [s_port]
else:
for octet in four_octets_set:
destination = check_subnet(len(dest_four_octets_set), len(dest_three_octets_set),
len(dest_two_octets_set), len(dest_one_octet_set), octet[1])
source = f"0.0.0.0/0;{destination};{octet[3]};{octet[4]};{octet[5]}"
s_port = octet[2]
if source in ip_network_dict:
ip_network_dict[source].extend([s_port])
else:
ip_network_dict[source] = [s_port]
# Join the elements of ip_network_dict dictionary into a list with ';'
socket_range = []
for key, value in ip_network_dict.items():
socket_range.append(f"{key};{value}")
return socket_range
dest_ip_network_range
This function classifies destination IP addresses into Class A/B/C and other IP ranges and groups them into IP network ranges.
- The provided code is a function named
classify_destination_ipsthat takes a list of destination IPs as input and classifies them into different IP ranges. Here's a breakdown of how the code works: - The function initializes several empty lists:
ip_ranges,class_a, class_b,class_c, andother_ips. These lists will be used to store the classified IP addresses. - The code then iterates over each destination IP in the destinations list.
- Inside the loop, it first checks if the destination IP is a valid IPv4 address by calling the
validate_ipv4_addressfunction. If it is a valid IP, the code proceeds with the classification. - For each valid IP, it checks if it falls within a specific IP range. If the IP falls within the range of Class A (10.0.0.0 - 10.255.255.255), it adds the destination to the
class_a list. If it falls within the range of Class B (172.16.0.0 - 172.31.255.255), it adds the destination to theclass_b list. If it falls within the range of Class C (192.168.0.0 - 192.168.255.255), it adds the destination to theclass_c list. If it doesn't fall into any of these ranges, it adds the destination to theother_ipslist. - After classifying all the IP addresses, the code checks if there are any IP addresses in the
other_ipslist. If there are, it calls thegroup_ip_networkfunction to group them into IP ranges and appends the resulting ranges to theip_rangeslist. - Similarly, the code checks if there are any IP addresses in the
class_a,class_b, andclass_clists. If there are, it calls the group_ip_network function for each list and appends the resulting ranges to theip_rangeslist. - Finally, the function returns the
ip_rangeslist, which contains all the classified IP ranges.
def classify_destination_ips(destinations):
"""
Classify the destination IPs of flow tuples based on Class A/B/C and other IP
:param destinations: List of destination IPs
:return: List of IP ranges
"""
ip_ranges = []
class_a = []
class_b = []
class_c = []
other_ips = []
for dest in destinations:
if validate_ipv4_address(dest[2]):
if IPv4Address(dest[2]) >= IPv4Address('10.0.0.0') and IPv4Address(dest[2]) <= IPv4Address('10.255.255.255'):
class_a.append(dest)
elif IPv4Address(dest[2]) >= IPv4Address('172.16.0.0') and IPv4Address(dest[2]) <= IPv4Address('172.31.255.255'):
class_b.append(dest)
elif IPv4Address(dest[2]) >= IPv4Address('192.168.0.0') and IPv4Address(dest[2]) <= IPv4Address('192.168.255.255'):
class_c.append(dest)
else:
other_ips.append(dest)
if len(other_ips) > 0:
other_ip_ranges = group_ip_network(other_ips)
ip_ranges += other_ip_ranges
if len(class_a) > 0:
class_a_ranges = group_ip_network(class_a)
ip_ranges += class_a_ranges
if len(class_b) > 0:
class_b_ranges = group_ip_network(class_b)
ip_ranges += class_b_ranges
if len(class_c) > 0:
class_c_ranges = group_ip_network(class_c)
ip_ranges += class_c_ranges
return ip_ranges
source_ip_network_range
This function classifies source IP addresses into Class A/B/C and other IP ranges and groups them into IP network ranges.
- The function
source_ip_network_rangeis renamed toclassify_source_ip_rangesto provide a more descriptive name. - Variable names are modified to follow lowercase with underscores style for improved readability.
- The docstring remains the same to explain the purpose of the function and its parameters.
- The range function is replaced with a loop that directly iterates over the sources list using the variable source.
- The condition
(validate_ipv4address(flow_list[1])== True and flow_list[7]=="A")is simplified tovalidate_ipv4_address(flow_list[1]) and flow_list[7] == "A". - The variables
classA,classB,classC, andotheripare changed toclass_a,class_b,class_c, andother_ip, respectively, following the lowercase with underscores style. - The check for IP ranges is now performed using the ip_address variable instead of calling
IPv4Addressmultiple times for each range comparison. - The addition of lists
ipranges = ipranges + otheriprangesis replaced with the augmented assignmentoperator +=for conciseness. - The function call
dest_ip_network_rangeis changed toip_network_range_udfassuming it is defined elsewhere in the code.
def classify_source_ip_ranges(sources):
"""
Classify the source IPs of flow tuples based on Class A/B/C and other IP ranges.
:param sources: List of flow tuples.
:return: List of IP ranges.
"""
ip_ranges = []
class_a = []
class_b = []
class_c = []
other_ip = []
for source in sources:
flow_list = source.split(",")
if validate_ipv4_address(flow_list[1]) and flow_list[7] == "A":
ip_address = IPv4Address(flow_list[1])
if ip_address >= IPv4Address('10.0.0.0') and ip_address <= IPv4Address('10.255.255.255'):
class_a.append(flow_list)
elif ip_address >= IPv4Address('172.16.0.0') and ip_address <= IPv4Address('172.31.255.255'):
class_b.append(flow_list)
elif ip_address >= IPv4Address('192.168.0.0') and ip_address <= IPv4Address('192.168.255.255'):
class_c.append(flow_list)
else:
other_ip.append(flow_list)
if len(other_ip) > 0:
other_ip_ranges = dest_ip_network_range(other_ip)
ip_ranges += other_ip_ranges
if len(class_a) > 0:
class_a_ranges = dest_ip_network_range(class_a)
ip_ranges += class_a_ranges
if len(class_b) > 0:
class_b_ranges = dest_ip_network_range(class_b)
ip_ranges += class_b_ranges
if len(class_c) > 0:
class_c_ranges = dest_ip_network_range(class_c)
ip_ranges += class_c_ranges
return ip_ranges
ip_network_range_udf = udf(classify_source_ip_ranges)
classify_source_ip_ranges that classifies source IP addresses of flow tuples into different categories based on their IP class (A, B, C) or other IP addresses. The function takes a parameter called sources, which is nothing but the list of flow tuples.
Inside the function, there are four empty lists created: classA, classB, classC, and otherip. These lists will be used to store the flow tuples based on their IP classification. The code then iterates over each element in the sources list using a for loop. In each iteration, the current element (a flow tuple) is split by a comma (,) to extract its individual components.
The flow tuple is then checked for two conditions: whether the second element, i.e., Source IP Address (index 1), is a valid IPv4 address and whether the eighth element, i.e., Policy of the rule (Allow or Deny) (index 7) is equal to 'A.' If both conditions are met, the flow tuple is classified based on its IP class (A, B, or C) by comparing the IP address with predefined IP ranges. If the IP address falls within the range of Class A IP addresses (10.0.0.0 - 10.255.255.255), the flow tuple is added to the class A list. Similarly, if it falls within the range of Class B IP addresses (172.16.0.0 - 172.31.255.255) or Class C IP addresses (192.168.0.0 - 192.168.255.255) it is added to the respective class B or class C list. If the IP address does not fall within any of these ranges, it is considered as "other" and added to the otherip list.
After processing all flow tuples in the sources list, the code checks if there are any flow tuples in the other list. If so, it calls a function called dest_ip_network_range to perform a similar IP classification for the destination IP addresses of these flow tuples. The resulting IP ranges are then added to the ip_ranges list. The same process is repeated for the class A, class B, and class C lists if they contain any flow tuples. The IP ranges from the destination IP classification are added to theip_ranges list. Finally, the function returns theip_ranges list, which contains the IP ranges for the classified source IP addresses.
The last line of code defines a user-defined function (UDF) called ip_network_range_udfusing the udf function. This UDF can be used with Spark DataFrame operations to apply the source_ip_network_range function on the data. Using the defined UDFs and functions, the code performs a permission check on NSG rules. It processes flow tuples from the NSG logs and groups them based on IP network ranges, source ports, destination ports, and protocols. It also classifies IP addresses into different categories, such as Class A/B/C and other IPs, and creates IP network ranges accordingly.
Final NSG Daily Rule
The below-provided code consists of a series of transformations applied to a DataFrame named dataframe for batch processing. Let's break down the code step by step:
coreUDFNSGDF Transformation:
coreUDFNSGDF = dataframe.withColumn("flow_tuples_network",ip_network_range_udf("flow_rules")).select("system_id","rule_name","flow_tuples_network")- This step applies a user-defined function (UDF) called
ip_network_range_udfto the"flow_rules"column of the input DataFrame. - The UDF transforms the
"flow_rules"values into a network range representation and creates a new column called"flow_tuples_network." - The resulting DataFrame,
coreUDFNSGDF, selects the columns"system_id","rule_name", and"flow_tuples_network."
splitNSGRuleDF Transformation:
splitNSGRuleDF = coreUDFNSGDF.select(col("system_id"),col("rule_name"),split(col("flow_tuples_network"),"],").alias("flow_net_array"))- This step splits the
"flow_tuples_network"column by the delimiter"],". - The resulting DataFrame,
splitNSGRuleDF, selects the columns"system_id","rule_name,"and creates a new column"flow_net_array"that contains the split values.
explodeNSGRuleDF Transformation:
explodeNSGRuleDF = splitNSGRuleDF.select("system_id","rule_name",explode("flow_net_array").alias("flow_explode"))- This step uses the explode function to expand the
"flow_net_array"column, resulting in multiple rows for each element in the array. - The resulting DataFrame,
explodeNSGRuleDF, selects the columns"system_id,""rule_name,"and creates a new column,"flow_explode."
regexNSGRuleDF Transformation:
regexNSGRuleDF = explodeNSGRuleDF.select(col("system_id"),col("rule_name"),F.regexp_replace(F.col("flow_explode"), "[\[\]]", "").alias("flow_range"))- This step uses the regexp_replace function to remove the square brackets
"["and"]"from the"flow_explode"column values. - The resulting DataFrame,
regexNSGRuleDF, selects the columns"system_id,""rule_name,"and creates a new column"flow_range."
finalNSGRuleDF Transformation:
finalNSGRuleDF = regexNSGRuleDF.select(col("system_id"),col("rule_name"),split(col("flow_range"),";").alias("flow_array")).select(col("system_id"),col("rule_name"),col("flow_array")[0].alias("sourcerange"),col("flow_array")[1].alias("destinationrange"),col("flow_array")[2].alias("destination_ports"),col("flow_array")[3].alias("protocols"),col("flow_array")[4].alias("policy"),col("flow_array")[5].alias("source_portlist"))- This step splits the
"flow_range"column by the delimiter";"and creates a new column"flow_array,"with the split values. - The resulting DataFrame, finalNSGRuleDF, selects the columns
"system_id"and"rule_name"and extracts specific elements from the"flow_array"column using indexing. - The extracted elements are given meaningful aliases such as
"sourcerange","destinationrange,""destination_ports,""protocols,""policy,"and"source_portlist."
Writing the DataFrame:
finalNSGRuleDF.write.format('parquet').save(output_file_path)
This step writes the finalNSGRuleDF DataFrame in the Parquet file format and saves it to the specified output file path.
Overall, the provided code performs a series of transformations on the input DataFrame, splitting columns, extracting specific values, and finally saving the transformed DataFrame in the Parquet format.
def processBatchData(input_dataframe):
coreUDFNSGDF = input_dataframe.withColumn("flow_tuples_network", ip_network_range_udf("flow_rules")).select("system_id", "rule_name", "flow_tuples_network")
splitNSGRuleDF = coreUDFNSGDF.select(col("system_id"), col("rule_name"), split(col("flow_tuples_network"), "],").alias("flow_net_array"))
explodeNSGRuleDF = splitNSGRuleDF.select("system_id", "rule_name", explode("flow_net_array").alias("flow_explode"))
regexNSGRuleDF = explodeNSGRuleDF.select(col("system_id"), col("rule_name"), F.regexp_replace(F.col("flow_explode"), "[\[\]]", "").alias("flow_range"))
finalNSGRuleDF = regexNSGRuleDF.select(col("system_id"), col("rule_name"), split(col("flow_range"), ";").alias("flow_array")).select(col("system_id"), col("rule_name"), col("flow_array")[0].alias("sourcerange"), col("flow_array")[1].alias("destinationrange"), col("flow_array")[2].alias("destination_ports"), col("flow_array")[3].alias("protocols"), col("flow_array")[4].alias("policy"), col("flow_array")[5].alias("source_portlist"))
finalNSGRuleDF.write.format('parquet').save(output_file_path)
Consolidate NSG Rule
As discussed in the NSG data transformation in the Spark section, consolidating the proposed rule on a daily, weekly, or monthly basis is considered a good practice in network security. This process involves reviewing and analyzing the rules that have been suggested for implementation. By consolidating the proposed rules, you ensure that the network security group (NSG) is effectively managed and operates optimally. Throughout the document, I discussed two types of rules: less permissive rules and over-permissive rules. Less permissive rules refer to rules that have stricter access controls, providing limited access to network resources. On the other hand, over-permissive rules are rules that have looser access controls, potentially granting more access than necessary. These concepts were discussed at a high level in the document. The default rules in a network security group are the rules that are applied when no specific rules are defined for a particular network resource. While default rules may provide some basic level of security, they are not always considered good practice. Relying solely on default rules indicates a poorly managed network security group. It is important to define specific rules for each network resource to ensure proper security measures are in place.
In contrast to default rules, user rules are defined based on their relative importance. User rules prioritize specific requirements and access needs for different network resources. However, user rules may not always be precise, as they are subjective and can vary depending on individual perspectives and requirements. To address these challenges, it is suggested to propose rules based on daily NSG logs. By analyzing the logs generated by the NSG on a daily basis, you can gain insights into the actual network traffic patterns, security incidents, and potential vulnerabilities. Consolidating these rules daily allows for a more accurate and up-to-date understanding of the network security requirements.
Furthermore, when consolidating the proposed rules, it is advisable to define them as absolutely as possible. This means setting rules that are clear, unambiguous, and strictly enforceable. Absolute rules provide a higher level of certainty and help minimize any potential misinterpretation or misconfiguration that could lead to security breaches. In the process of consolidating and defining rules, collaboration with the network security team is crucial. Working together with the team allows for a comprehensive understanding of the network infrastructure and helps in identifying the confidence level of the proposed rules. Utilizing Spark analysis, a powerful data processing framework, can aid in extracting insights from the NSG logs and assist in determining the effectiveness and reliability of the proposed rules.
Conclusion
Micro-segmentation and permissive rule checks in network security groups play a vital role in maintaining a secure and compliant network infrastructure. By leveraging Apache Spark’s distributed computing capabilities, organizations can efficiently analyze and validate NSG rules, ensuring that the defined rules are permissive enough to allow legitimate traffic while maintaining a high level of security. Automating the permission check process using Apache Spark not only enhances network security but also simplifies network management and enables rapid detection and response to potential security incidents. By implementing micro-segmentation and adhering to permissive rule best practices, organizations can strengthen their network security posture, minimize the attack surface, and protect their sensitive data from unauthorized access. In an ever-evolving threat landscape, organizations need to prioritize network security and adopt advanced techniques like micro-segmentation and permissive rule checks. By staying proactive and leveraging the power of technologies like Apache Spark, organizations can effectively mitigate security risks and maintain robust network infrastructure.
