Reactive Database Access on the JVM

A couple of years ago, Reactive Programming was all the rage, but it had one big issue: reactive stopped as soon as you access a SQL database. You had a nice reactive chain up to the database, defeating the whole purpose. Given the prevalence of SQL databases in existing and new apps, one couldn't enjoy the full benefits of Reactive Programming but still pay the full price of complexity.
Since then, the landscape has changed tremendously. Most importantly, it offers many reactive drivers over popular databases: PostgreSQL, MariaDB and MySQL, Microsoft SQL Server, Oracle, you name it! Even better, some frameworks provide a reactive API over them.
Even though I'm not providing consulting services regularly, I wanted to keep up-to-date on accessing data reactively. In this post, I'll describe Hibernate Reactive, Spring Data R2DBC, and jOOQ in no particular order.
The base application uses Project Reactor and its types — Flux and Mono. For an added twist, I use Kotlin (without coroutines). Most code snippets have unnecessary type hints for better understanding.
The Demo Model
I don't want a complicated demo model, but I don't want it to be too simple. I'll use a single many-to-many relationship and a field with LocalDate:

Spring Data R2DBC
As far as I remember, the Spring ecosystem was the first to offer a reactive database access API. At first, it was limited to H2 — not very useful in production. However, new reactive drivers were easy to integrate.
Spring Data RDBC builds upon the widespread Spring Data JPA. The biggest difference is that there's a single required annotation for entities, @Id.
Here's the code for the person table:
data class Person(
@Id val id: Long,
val firstName: String,
val lastName: String,
val birthdate: LocalDate?,
@Transient
val addresses: MutableSet<Address> = mutableSetOf()
)
interface PersonRepository : ReactiveCrudRepository<Person, Long>R2DBC repositories look similar to regular Spring Data repositories with one big difference. They integrate Project Reactor's reactive types, Mono and Flux. Note that it's easy to use Kotlin's coroutines with an additional bridge dependency.

Now comes the hard problem: mapping the many-to-many relationship with the Address.
First, we must tell Spring Data R2DBC to use a specific constructor with an empty set of addresses.
data class Person(
@Id val id: Long,
val firstName: String,
val lastName: String,
val birthdate: LocalDate?,
@Transient
val addresses: MutableSet<Address> = mutableSetOf()
) {
@PersistenceCreator
constructor(
id: Long,
firstName: String,
lastName: String,
birthdate: LocalDate? = null
) : this(id, firstName, lastName, birthdate, mutableSetOf())
}We also need to define the Address repository, as well as a query to list all addresses of a person:
interface AddressRepository : ReactiveCrudRepository<Address, Long> {
@Query("SELECT * FROM ADDRESS WHERE ID IN (SELECT ADDRESS_ID FROM PERSON_ADDRESS WHERE PERSON_ID = :id)")
fun findAddressForPersonById(id: Long): Flux<Address>
}Now comes the least tasteful part: Spring Data R2DBC doesn't support many-to-many relationships at the moment. We need a hook that queries the addresses after loading a person.
class PersonLoadOfficeListener(@Lazy private val repo: AddressRepository) //1
: AfterConvertCallback<Person> {
override fun onAfterConvert(person: Person, table: SqlIdentifier) =
repo.findAddressForPersonById(person.id) //2
.mapNotNull {
person.addresses.add(it) //3
person
}.takeLast(1) //4
.single(person) //5
}- Annotate with
@Lazyto avoid running into circular dependencies exception during injection - Use the above query
- Add each address
- Reactive trick to wait for the last bit of data
- Turn into a single
Person
As far as I can understand, Spring Data R2DBC still needs to execute additional queries, thus leading to the (in)famous N+1 query problem.
One configures database access via all available Spring alternatives: properties, YAML, Spring profiles, environment variables, etc. Here's a YAML example:
spring.r2dbc:
url: r2dbc:postgresql://localhost:5432/postgres?currentSchema=people
username: postgres
password: rootHibernate Reactive
If you're familiar with regular Hibernate, you'll feel right at home with Hibernate Reactive. The mapping is the same in both cases:
@Entity
@Table(name = "person", schema = "people") //1
class Person(
@Id var id: Long?,
@Column(name = "first_name") //2
var firstName: String?,
@Column(name = "last_name") //2
var lastName: String?,
var birthdate: LocalDate?,
@ManyToMany
@JoinTable( //3
name = "person_address",
schema = "people",
joinColumns = [ JoinColumn(name = "person_id") ],
inverseJoinColumns = [ JoinColumn(name = "address_id") ]
)
val addresses: MutableSet<Address> = mutableSetOf()
) {
internal constructor() : this(null, null, null, null) //4
}- Define the table and the schema if necessary
- Define column names, if necessary
- Define the join column
- JPA requires a no-argument constructor
We also need to configure the database. Hibernate Reactive uses the traditional XML-based JPA approach:
<persistence xmlns="https://jakarta.ee/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://jakarta.ee/xml/ns/persistence https://jakarta.ee/xml/ns/persistence/persistence_3_0.xsd"
version="3.0">
<persistence-unit name="postgresql">
<provider>org.hibernate.reactive.provider.ReactivePersistenceProvider</provider> <!--1-->
<properties>
<property name="jakarta.persistence.jdbc.url" value="jdbc:postgresql://localhost:5432/postgres?currentSchema=people" />
<property name="jakarta.persistence.jdbc.user" value="postgres" />
<property name="jakarta.persistence.jdbc.password" value="root" />
<property name="jakarta.persistence.schema-generation.database.action" value="validate" />
</properties>
</persistence-unit>
</persistence>- The only difference so far from the regular Hibernate configuration
Here's the source for the query itself:
val emf = Persistence.createEntityManagerFactory("postgresql") //1
val sessionFactory: Mutiny.SessionFactory = emf.unwrap(Mutiny.SessionFactory::class.java) //2
val people: Mono<MutableList<Person>> = sessionFactory
.withSession {
it.createQuery<Person>("SELECT p FROM Person p LEFT JOIN FETCH p.addresses a").resultList
}.convert().with(UniReactorConverters.toMono()) //3- Regular
EntityManagerFactory - Unwrap the underlying session factory implementation. Because we configured a
ReactivePersistenceProviderin thepersistence.xml, it's aMutiny.SessionFactory - Hibernate Reactive integrates with Vert.x, but an extension allows to bridge to Project Reactor if wanted
Note that Hibernate Reactive is the only library among the three to return a Mono<List> instead of a Flux. In layman's terms, it means you get the whole list at once instead of getting the elements one by one and being able to do something on each one individually.
jOOQ Reactive
As for the two above frameworks, jOOQ Reactive is similar to its non-reactive version. You first generate the code from the database schema, then use it.
<plugin>
<groupId>org.jooq</groupId>
<artifactId>jooq-codegen-maven</artifactId> <!--1-->
<executions>
<execution>
<id>jooq-codegen</id>
<phase>generate-sources</phase>
<goals>
<goal>generate</goal>
</goals>
</execution>
</executions>
<dependencies>
<dependency>
<groupId>org.postgresql</groupId> <!--2-->
<artifactId>postgresql</artifactId>
<version>42.6.0</version>
</dependency>
</dependencies>
<configuration>
<generator>
<name>org.jooq.codegen.KotlinGenerator</name> <!--3-->
<database>
<inputSchema>people</inputSchema> <!--4-->
</database>
<target>
<packageName>ch.frankel.blog.reactivedata.jooq</packageName>
</target>
</generator>
<jdbc> <!--4-->
<driver>org.postgresql.Driver</driver>
<url>jdbc:postgresql://localhost:5432/postgres</url>
<user>postgres</user>
<password>root</password>
</jdbc>
</configuration>
</plugin>- The version is defined in the parent Spring Boot Starter parent POM
- Set the necessary database driver(s). Note that one should use the non-reactive driver
- There's a Kotlin generator!
- Configure database configuration parameters
Once you've generated the code, you can create your data class and design the query. jOOQ class hierarchy integrates with Java's collections, Java's Reactive Streams, and Project Reactor.
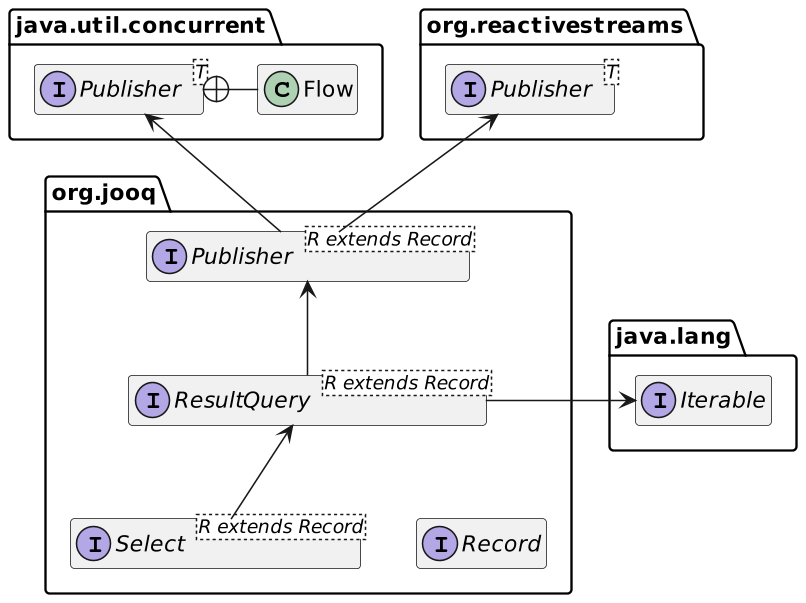
The code may look complex if you're neither a SQL nor a jOOQ expert.
Remember that variable types are unnecessary but added for documentation purposes:
fun findAll(): Flux<PersonWithAddresses> { //1
val people: SelectJoinStep<Record5<Long?, String?, String?, LocalDate?, MutableList<Address>>> = //2
ctx.select(
PERSON.ID,
PERSON.FIRST_NAME,
PERSON.LAST_NAME,
PERSON.BIRTHDATE,
DSL.multiset( //2
DSL.select(
PERSON_ADDRESS.ADDRESS_ID,
PERSON_ADDRESS.address.FIRST_LINE,
PERSON_ADDRESS.address.SECOND_LINE,
PERSON_ADDRESS.address.ZIP,
PERSON_ADDRESS.address.CITY,
PERSON_ADDRESS.address.STATE,
PERSON_ADDRESS.address.COUNTRY,
).from(PERSON_ADDRESS)
.where(PERSON_ADDRESS.PERSON_ID.eq(PERSON.ID))
).convertFrom { it.map(addressMapper) } //3
).from(PERSON)
return Flux.from(people) //4
.map(personWithAddressesMapper) //3
}- Return a regular Project Reactor's
Flux - Use
multiset, see below. - Convert the row to an ordinary Java object via a function
- The magic happens here: wrap the regular query in a
Fluxforpeopleis a Project ReactorPublisher
Let's dive a bit into multiset from the point of view of a non-jOOQ expert — me. Initially, I tried to execute a regular SQL query with results I tried to flatten with Project Reactor's API. I failed miserably because of my lack of knowledge of the API, but even if I had succeeded, it would have been the wrong approach.
After hours of research, I found multiset via a post from Vlad Mihalcea:
The
MULTISETvalue constructor is one of jOOQ's and standard SQL's most powerful features. It allows for collecting the results of a non scalar subquery into a single nested collection value withMULTISETsemantics.-- MULTISET value constructor
In the above query, we first select all addresses of a person, map each row to an object, and flatten them in a list on the same result row as the person. The second mapper maps the row, including the address list, to a dedicated person with an addresses list.
I'm not a SQL master, so multiset is hard at first glance. However, I confirm that it's a powerful feature indeed.
Note that nested collections are fetched eagerly on a per-record basis, whereas top-level records are streamed reactively.
Conclusion
We have browsed the surface of the main three reactive database access: Spring Data R2DBC, Hibernate, and jOOQ. So, which one should one choose?
The main deciding factor is whether you already use one of their non-reactive flavors. Use the framework you're familiar with since both reactive and non-reactive usages are similar.
I think that jOOQ is extremely powerful but requires a familiarity I currently lack. If you have complex queries that don't map easily to other approaches, it's the way to go. Besides that, I've no strong opinion, though I find Hibernate Reactive's configuration too limited by JPA and its Mono<List> return type puzzling.
Thanks to Lukas Eder and Mark Paluch for their reviews on their respective sections of expertise.
The complete source code for this post can be found on GitHub.
To go further:
- Hibernate Reactive Reference Documentation
- Integrating Hibernate Reactive with Spring
- jOOQ Reactive Fetching
- How to fetch multiple to-many relationships with jOOQ MULTISET
- How to Turn a List of Flat Elements into a Hierarchy in Java, SQL, or jOOQ
- Spring Data R2DBC
- Comment bien s'entendre avec avec Spring Data R2DBC... ou pas
