Scalable Data Grid Using Apache Ignite

In this article, I introduce the concept of a Data Grid, it's properties, services it offers, and finally how to design a scalable Data Grid for your needs.
What Is a Data Grid?
A Data Grid is a set of services that delivers a shared data management system, wherein heterogeneous data from various applications and services will be accessible by forming a grid-like structure. This is possible using strong middle-ware applications and services that support data ingress/query from various application requests.
The data in the grid is accessed by APIs (REST preferred and in JSON format). The data can be persisted to a disk or can be backed by another database. The grid has to be very elastic in nature (horizontally scalable) and should support virtually any amount of data. Multiple services can save data in JSON format to this grid and query back in sub-milliseconds (similar to cache).
Below are the properties of Data Grid:
- Data access from the grid is performed using an API — REST-based with JSON format.
- Truly elastic in nature — can be horizontally scaled with no upper bounds.
- Durability — can handle downtime and system failure.
- Offers low latency responses.
Optional (good to have) properties:
- Considering the criticality of data, every request for data from the grid can be authorized
- Solutions like JWT, TSL client validation, etc.
- Ability to clear data and make space for more relevant data.
- Ability to persist data to disk.
- Ability to hot-load data from other data sources like RDBMS or NoSQL stores.
Use of a Data Grid
In a true Microservice architecture world, where each service has its own private database (database per service model), it is challenging if any one of the services requires to fetch data across multiple services. The upfront challenge could be handling responses from these services in various formats like JSON, XML, or binary format. Some requests could be over HTTP(S) using REST standards, some using SOAP, some using RPC, etc.
These aren't technical challenges, but rather cumbersome to implement in a Microservice for scenarios like: handling failures like security exceptions, data validation, handshake, network, data parsing, etc. While it's safe to assume that this is the most used approach, a factor of high-dependency is introduced. Any change in any of the producer services could possibly change the response structure, and the consumer service also may need to accommodate this change. This may not be efficient if the consumer services are only querying data (and not requesting any computational results) from the other services.
To solve the above problem, we introduce a Data Grid approach that offers virtually any volume of custom data storage with low latency responses that are highly scalable and easy to maintain. We can use Apache Ignite (referred to as Ignite going forward) as one of the prime components in our Data Grid design that offers a durable, elastic, and distributed in-memory platform. Ignite offers a variety of caching options, the ability to connect to RDBMS and NoSQL stores, and computing services.
Data Definitions
As a rule, to build a Data Grid for your infrastructure, all microservices should publish the format of the data they write to the grid. For example, a User Service (service to manage all users of a system) should publish all user information for all upserts and delete operations. The User Service should publish a data definition of the user data structure. This data definition should support versioning, so that any new service can query for a specific/latest version. All dependent consumer services can query the data definition from the Data Grid and start building the service functionality. Below is an example of a published user data structure (version 1).
https://<host>/grid/datadefinition&type=user&version=1.
{
"user": {
"description": "Structure of a user data.",
"owner": "user_service",
"version": 1,
"fields": [
{ "name": "id", "type": "uuid", "description": "Unique identifier for this user." },
{ "name": "email", "type": "string", "required": true },
{ "name": "mobile", "type": "string", "required": true },
{ "name": "name", "type": "string", "description": "Firstname of the user." },
{ "name": "zipcode", "type": "string", "description": "Zipcode of the user location." },
{ "name": "status", "type": "string", "required": true, "values": ["registered", "inactive", "deleted"]}
]
}
}
For version 2 of the user data definition, the query could be: https://<host>/grid/datadefinition&type=user&version=2.
xxxxxxxxxx
{
"user": {
"description": "Structure of a user data.",
"owner": "user_service",
"version": 2,
"fields": [
{ "name": "id", "type": "uuid", "description": "Unique identifier for this user." },
{ "name": "salutation", "type": "string", "description": "Salution for the user.", "required": true, "values": ["Mr.", "Ms.", "Mrs.", "Dr."]},
{ "name": "lastLogin", "type": "dateTime", "description": "Last login time of the user."},
{ "name": "email", "type": "string", "required": true },
{ "name": "mobile", "type": "string", "required": true },
{ "name": "name", "type": "string", "description": "Firstname of the user." },
{ "name": "zipcode", "type": "string", "description": "Zipcode of the user location." },
{ "name": "status", "type": "string", "required": true, "values": ["registered", "inactive", "deleted"]}
]
}
}
High-Level Design
The system design for a Data Grid can be explained using an example of an online shopping site. The shopping site is build using various microservices like User Service, Order Service, Product Catalog Service, and Other Services that help in achieving the order placement of a product from various catalogs and finally delivering it to the customer.
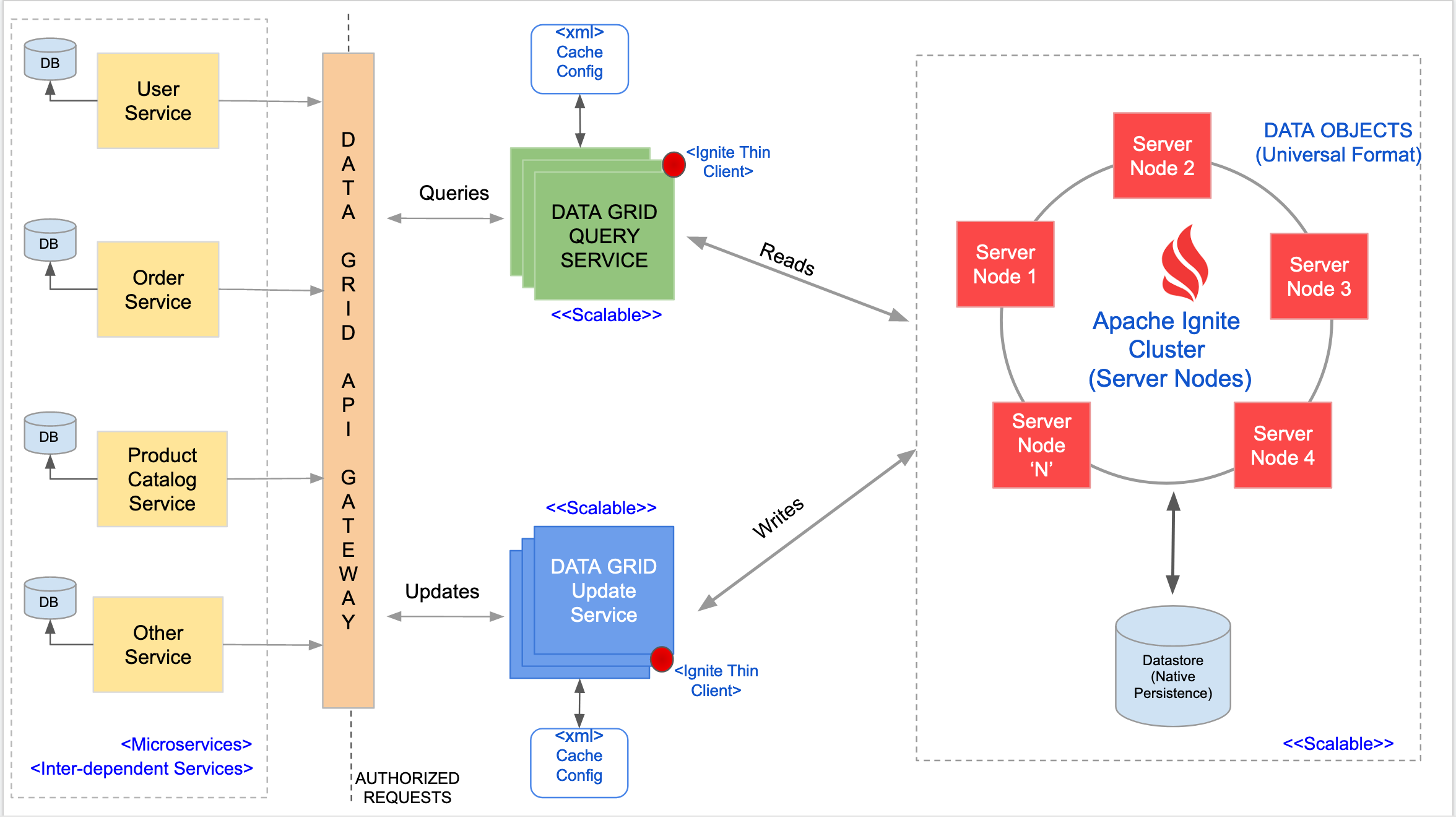
Component Services
Data Layer
This is the heart of the Data Grid, where an Apache Ignite setup (server mode) is deployed. This setup forms the "Ignite Server Cluster." Some of the features that Ignite offers off the shelf that help in building a scalable grid are:
- In-memory caching — for low latency responses.
- Distributed and Durable storage.
- Elasticity (horizontally scalable by the addition of nodes).
- Fault tolerance (data replication and auto-load balancing upon node failure).
- Data replication and persistence (to disk or a database).
Ignite also works on masterless architecture, and spinning up additional nodes only adds additional in-memory cache space to the cluster group. Ignite also offers various cache configurations; depending on your needs, this can be tuned and enhanced. Configurations include data persistence options, cache eviction policies, data replication, etc.
Data Grid API Gateway
This is a gateway to route queries to appropriate servers. Multiple services can be registered with the Gateway, so that the requests can be handled and scaled as per load.
Query Services and Update Services
These are a slew of application servers meant to either query data or update/add data into the data layer. These services query/update data from/to the "Ignite Server Cluster" (see the image above for a visualization of the Data Layer).
Query Services categorizes services that ONLY query data. The services in this setup use an Ignite client library (configured as client mode) to connect to Ignite Server Cluster and become a part of the Ignite cluster topology. In case these services are not intended to join the cluster topology as Ignite client nodes, then we can use thin Ignite clients (like Java Thin Client or Node.js Thin Client) to connect to Ignite Server Cluster and execute cache operations. Each of the services may update 1 or more caches in the Ignite Server Cluster.
There could be an overhead of pushing the data to the Data Grid, but that can be overcome by using asynchronous mechanisms or by pushing the data into some Kafka topic, where data will be consumed by the Data Grid Update Service which pushes it to the Ignite Server cluster.
Note: The application services use Ignite client libraries for cache operations. By default, they also participate in caching by joining the Ignite Server cluster topology to work as server nodes. This isn't required; the client mode flag (set to true) has to be enabled in the Ignite configuration file, or a similar Ignite API has to be called upon application service initialization. See this link for more info on Ignite client and server setup.
Use of Data Grid in the example
In the diagram above, the components in the left-most side are the microservices, where each service has its own database. In a non-Data Grid approach, the Order Service may need to query the User Service for user-related information (like user email, address, etc). During specific times like Christmas sale or thanksgiving sale, the Order Service may encounter high volume transactions. In such cases, the Order Service may have to call the User Service for fetching user-related information (like user email, address, etc) proportional to the number of order transactions.
Optionally, the Order Service could cache the user information to avoid multiple network calls. Or, to cater to the increasing load on the User Service, we may need to add more User Service nodes to the cluster to handle read requests. Similarly, other services may also need to scale up to which encounters a lot of read traffic. This is where the Data Grid can be introduced.
Whenever there is a data update in one of the microservice, that data will be pushed to the Data Grid using the Data Grid Update Service. This Update Service connects to the Ignite Server and then inserts the data into the cache. The data inserted into the cache will be based on the cache configuration deployed in the Update Service. This ensures that any data that is updated in any microservice will be available in the Data Grid as well. Also since Ignite is durable, we can add any number of nodes to support a large data set from various services. The Ignite Server cluster can be enabled with native persistence or be connected to a database so that the cache data can be persisted.
When one of the microservices needs to access specific data, it would query the Data Grid using the Data Grid Query Service by passing necessary query parameters. The Query Service connects to the Ignite Server and then queries the data from the cache. If the data is available in the cache, it would be sent as a response. If the data is unavailable in the cache, Ignite can load it from the persistent store (if persistence is enabled).
There might be a scenario where the data is unavailable in the cache and also in the persistent store. The Query Service can have built-in logic to reroute the request to the respective microservice, fetch the data, and insert it into the cache. The same response can be sent back to the consumer service who requested this data. On the next request, the data will be fetched from the Data Grid itself.
The data inserted into the cache will be based on the cache configuration deployed in the Update Service. This ensures that any data that is updated in any microservice will be available in the Data Grid as well. Also, since Ignite is durable, we can add any number of nodes to support a large data set from various services.
Summary
This article attempts to address the issue where consumer services can be decoupled from the producer services. This also give users the flexibility to add more services to the microservices regiment and build and deploy new sets of functionality.
