Lambda Architecture Principles

"Lambda Architecture" (introduced by Nathan Marz) has gained a lot of traction recently. Fundamentally, it is a set of design patterns of dealing with Batch and Real time data processing workflow that fuel many organization's business operations. Although I don't realize any novice ideas has been introduced, it is the first time these principles are being outlined in such a clear and unambiguous manner.
In this post, I'd like to summarize the key principles of the Lambda architecture, focus more in the underlying design principles and less in the choice of implementation technologies, which I may have a different favors from Nathan.
One important distinction of Lambda architecture is that it has a clear separation between the batch processing pipeline (ie: Batch Layer) and the real-time processing pipeline (ie: Real-time Layer). Such separation provides a means to localize and isolate complexity for handling data update. To handle real-time query, Lambda architecture provide a mechanism (ie: Serving Layer) to merge/combine data from the Batch Layer and Real-time Layer and return the latest information to the user.
Data Source Entry
At the very beginning, data flows in Lambda architecture as follows ...- Transaction data starts streaming in from OLTP system during business operations. Transaction data ingestion can be materialized in the form of records in OLTP systems, or text lines in App log files, or incoming API calls, or an event queue (e.g. Kafka)
- This transaction data stream is replicated and fed into both the Batch Layer and Realtime Layer

Batch Layer
For storing the ground truth, "Master dataset" is the most fundamental DB that captures all basic event happens. It stores data in the most "raw" form (and hence the finest granularity) that can be used to compute any perspective at any given point in time. As long as we can maintain the correctness of master dataset, every perspective of data view derived from it will be automatically correct.Given maintaining the correctness of master dataset is crucial, to avoid the complexity of maintenance, master dataset is "immutable". Specifically data can only be appended while update and delete are disallowed. By disallowing changes of existing data, it avoids the complexity of handling the conflicting concurrent update completely.
Here is a conceptual schema of how the master dataset can be structured. The center green table represents the old, traditional-way of storing data in RDBMS. The surrounding blue tables illustrates the schema of how the master dataset can be structured, with some key highlights
- Data are partitioned by columns and stored in different tables. Columns that are closely related can be stored in the same table
- NULL values are not stored
- Each data record is associated with a time stamp since then the record is valid

Notice that every piece of data is tagged with a time stamp at which the data is changed (or more precisely, a change record that represents the data modification is created). The latest state of an object can be retrieved by extracting the version of the object with the largest time stamp.
Although master dataset stores data in the finest granularity and therefore can be used to compute result of any query, it usually take a long time to perform such computation if the processing starts with such raw form. To speed up the query processing, various data at intermediate form (called Batch View) that aligns closer to the query will be generated in a periodic manner. These batch views (instead of the original master dataset) will be used to serve the real-time query processing.
To generate these batch views, the "Batch Layer" use a massively parallel, brute force approach to process the original master dataset. Notice that since data in master data set is timestamped, the data candidate can be identified simply from those that has the time stamp later than the last round of batch processing. Although less efficient, Lambda architecture advocates that at each round of batch view generation, the previous batch view should just be simply discarded and the new batch view is computed from master dataset. This simple-mind, compute-from-scratch approach has some good properties in stopping error propagation (since error cannot be accumulated), but the processing may not be optimized and may take a longer time to finish. This can increase the "staleness" of the batch view.
Real time Layer
As discussed above, generating the batch view requires scanning a large volume of master dataset that takes few hours. The batch view will therefore be stale for at least the processing time duration (ie: between the start and end of the Batch processing). But the maximum staleness can be up to the time period between the end of this Batch processing and the end of next Batch processing (ie: the batch cycle). The following diagram illustrate this staleness.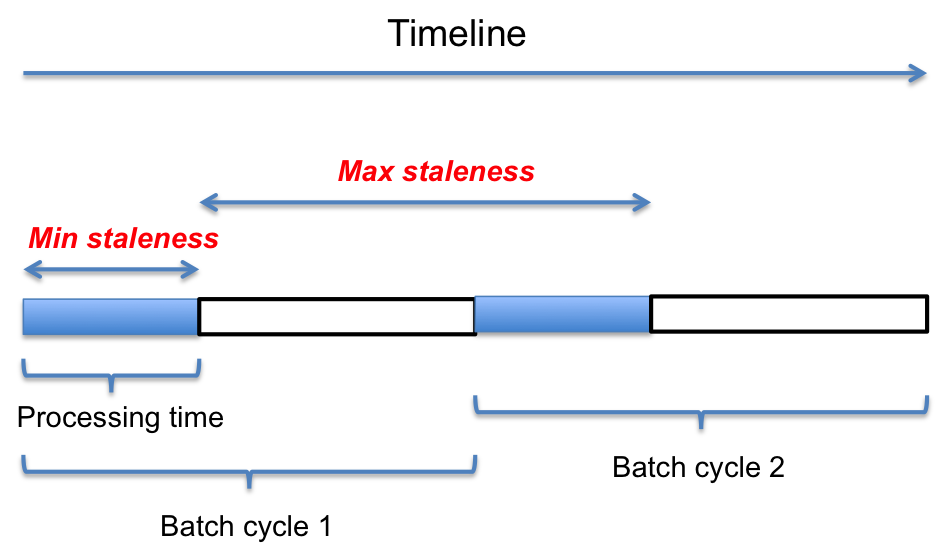
Even the batch view is stale period, business operates as usual and transaction data will be streamed in continuously. To answer user's query with the latest, up-to-date information. The business transaction records need to be captured and merged into the real-time view. This is the responsibility of the Real-time Layer. To reduce the latency of latest information availability close to zero, the merge mechanism has to be done in an incremental manner such that no batching delaying the processing will be introduced. This requires the real time view update to be very different from the batch view update, which can tolerate a high latency. The end goal is that the latest information that is not captured in the Batch view will be made available in the Realtime view.
The logic of doing the incremental merge on Realtime view is application specific. As a common use case, lets say we want to compute a set of summary statistics (e.g. mean, count, max, min, sum, standard deviation, percentile) of the transaction data since the last batch view update. To compute the sum, we can simply add the new transaction data to the existing sum and then write the new sum back to the real-time view. To compute the mean, we can multiply the existing count with existing mean, adding the transaction sum and then divide by the existing count plus one. To implement this logic, we need to READ data from the Realtime view, perform the merge and WRITE the data back to the Realtime view. This requires the Realtime serving DB (which host the Realtime view) to support both random READ and WRITE. Fortunately, since the realtime view only need to store the stale data up to one batch cycle, its scale is limited to some degree.
Once the batch view update is completed, the real-time layer will discard the data from the real time serving DB that has time stamp earlier than the batch processing. This not only limit the data volume of Realtime serving DB, but also allows any data inconsistency (of the realtime view) to be clean up eventually. This drastically reduce the requirement of sophisticated multi-user, large scale DB. Many DB system support multiple user random read/write and can be used for this purpose.
Serving Layer
The serving layer is responsible to host the batch view (in the batch serving database) as well as hosting the real-time view (in the real-time serving database). Due to very different accessing pattern, the batch serving DB has a quite different characteristic from the real-time serving DB.As mentioned in above, while required to support efficient random read at large scale data volume, the batch serving DB doesn't need to support random write because data will only be bulk-loaded into the batch serving DB. On the other hand, the real-time serving DB will be incrementally (and continuously) updated by the real-time layer, and therefore need to support both random read and random write.
To maintain the batch serving DB updated, the serving layer need to periodically check the batch layer progression to determine whether a later round of batch view generation is finished. If so, bulk load the batch view into the batch serving DB. After completing the bulk load, the batch serving DB has contained the latest version of batch view and some data in the real-time view is expired and therefore can be deleted. The serving layer will orchestrate these processes. This purge action is especially important to keep the size of the real-time serving DB small and hence can limit the complexity for handling real-time, concurrent read/write.
To process a real-time query, the serving layer disseminates the incoming query into 2 different sub-queries and forward them to both the Batch serving DB and Realtime serving DB, apply application-specific logic to combine/merge their corresponding result and form a single response to the query. Since the data in the real-time view and batch view are different from a timestamp perspective, the combine/merge is typically done by concatenate the results together. In case of any conflict (same time stamp), the one from Batch view will overwrite the one from Realtime view.
Final Thoughts
By separating different responsibility into different layers, the Lambda architecture can leverage different optimization techniques specifically designed for different constraints. For example, the Batch Layer focuses in large scale data processing using simple, start-from-scratch approach and not worrying about the processing latency. On the other hand, the Real-time Layer covers where the Batch Layer left off and focus in low-latency merging of the latest information and no need to worry about large scale. Finally the Serving Layer is responsible to stitch together the Batch View and Realtime View to provide the final complete picture.The clear demarcation of responsibility also enable different technology stacks to be utilized at each layer and hence can tailor more closely to the organization's specific business need. Nevertheless, using a very different mechanism to update the Batch view (ie: start-from-scratch) and Realtime view (ie: incremental merge) requires two different algorithm implementation and code base to handle the same type of data. This can increase the code maintenance effort and can be considered to be the price to pay for bridging the fundamental gap between the "scalability" and "low latency" need.
Nathan's Lambda architecture also introduce a set of candidate technologies which he has developed and used in his past projects (e.g. Hadoop for storing Master dataset, Hadoop for generating Batch view, ElephantDB for batch serving DB, Cassandra for realtime serving DB, STORM for generating Realtime view). The beauty of Lambda architecture is that the choice of technologies is completely decoupled so I intentionally do not describe any of their details in this post. On the other hand, I have my own favorite which is different and that will be covered in my future posts.
