Monitoring and Troubleshooting Deadlocks With SQL Monitor

Deadlocks can occur when two or more sessions inside of the database engine are waiting for access to locked resources held by each other. Technically, a deadlock can be viewed as a circular locking chain, because every process (SPID) in the blocking chain will be waiting for one or more other processes in that same blocking chain, such that none can complete.
As soon as SQL Server detects a deadlock, it will act to resolve it by killing one of the deadlocked processes and rolling back whatever transaction it was running; potentially an important business transaction, which would need to check the error code for a deadlock and respond accordingly. Also, while the protagonist processes are deadlocked, other processes may also be blocked from accessing the affected tables.
This article will discuss why deadlocks occur, why they require immediate investigation by the DBA, and the diagnostic data required to troubleshoot them. It then demonstrates a deadlock incident as detected in SQL Monitor and shows how we can find the cause quickly using the Extended Events deadlock graph provided in the alert details, along with supporting diagnostic data on resource usage and the queries and processes executing around the time of the alert.
How SQL Server Resolves Deadlocks
SQL Server has a lock monitor that auto-detects deadlocks by periodically checking for the existence of any circular locking chains.
For example, let's say that Session A holds a lock on one resource but can't proceed until Session B releases a lock on a resource it needs to access, and Session B can't proceed until Session C releases a lock, and Session C can't proceed until Session A releases its lock.
SQL Server will resolve the deadlock by killing one of these sessions (the deadlock victim) and rolling back its transaction, therefore releasing any locks it held. This allows the other sessions in the blocking chain to continue executing.
The unfortunate deadlock victim receives the dreaded 1205 error message:
Transaction (Process ID XX) was deadlocked on resources with another process and has been chosen as the deadlock victim. Rerun the transaction.
The DBA needs to ensure proper handling of this 1205 exception to avoid UnhandledException errors in the application. Whether this is done using a BEGIN TRY/CATCH block inside the SQL being executed or within the application code, the most common approach is to pause and then retry the transaction a set number of times.
So Why Do We Need to Diagnose Deadlocks?
Just because DBAs don't need to intervene manually to resolve a deadlock, that doesn't mean that they can ignore them. It's an important error condition and they should investigate immediately to find out what caused the deadlock and take steps to prevent it recurring.
Firstly, the deadlock victim may turn out to be an important business process. We can avoid a session being chosen as a deadlock victim if it's running an important process by assigning it that session a DEADLOCK_PRIORITY setting of HIGH. However, if two or more sessions involved in a deadlock have the same deadlock priority, then SQL Server's only criteria for choosing the deadlock victim is the estimated cost to roll back the session. On that basis, if a session that's modified a single row of data deadlocks with a complex reporting query that's been running for five hours, the latter will be chosen as the victim.
Secondly, some of the most common causes of deadlocks include poor database design, lack of indexing, poorly-designed queries, transactionitis (unnecessary or overly-long explicit transactions), and inappropriate choice of transaction isolation level. If these problems afflict your databases, it's likely that your applications are suffering not only from deadlocks but also slow-running queries, severe blocking, and other performance problems. By monitoring and diagnosing deadlocks, we can then go on to improve the overall database performance.
Diagnosing Deadlocks: The Deadlock Graph
The key piece of diagnostic data is the deadlock graph, which shows us which processes and resources were involved in a deadlock, which one was chosen as the deadlock victim, and more.
One way to capture the graph is to set up a server-side Profiler trace to capture the Deadlock Graph event and wait for the deadlock to recur. However, a much more convenient method is to use the Extended Events xml_deadlock_report event captured automatically by the system_health event session, which is running by default on all installations of SQL Server 2008 and later. The xml_report field of this event holds the deadlock graph. Also, uniquely, the Extended Events deadlock graph allows for the diagnosis of multi-victim deadlocks where SQL Server had to kill multiple sessions to resolve the deadlock condition.
If you're trying to resolve deadlocks on instances that pre-date SQL Server 2008 or for some other reason can't use Extended Events or Profiler traces, then I'll refer you to Jonathan Kehayias' article Handling Deadlocks in SQL Server for other ways to do this.
Figure 1 shows an Extended Events xml_deadlock_report event in the event_file target of the system_health default event session. You can download the ReaderWriterDeadlock code file to reproduce the deadlock.
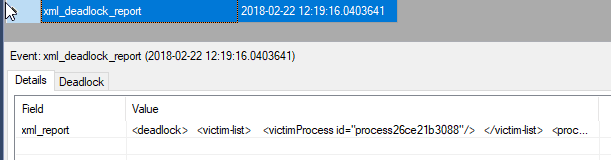 Figure 1: Capturing the deadlock graph using Extended Events.
Figure 1: Capturing the deadlock graph using Extended Events.
You can click on xml_report to open the full XML deadlock graph, as shown in Figure 2. I've added the colored boxes manually to highlight the three main sections of the deadlock graph: victim list, process list, and resource list.
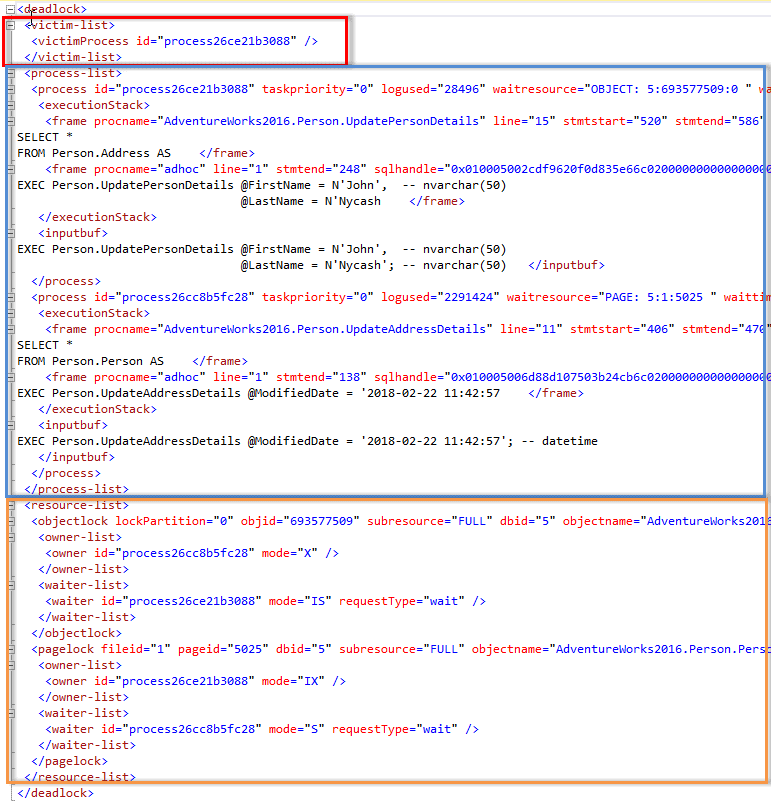 Figure 2: The XML deadlock graph.
Figure 2: The XML deadlock graph.
Reading an XML Deadlock Graph takes patience, and some of the elements, particularly the <process> elements, contain many fields, so you'll find yourself scrolling left and right to find some of the important details such as the isolation level requested for each of the deadlocked processes.
However, once you've mastered the basics, all the information you need to diagnose the deadlock condition is in there. The alternative is to switch to the Deadlock tab in Figure 1 to see a basic visual representation of the graph.
 Figure 3: Visual representation of the deadlock graph is SSMS.
Figure 3: Visual representation of the deadlock graph is SSMS.
The blue cross indicates clearly which process (SPID 84) was the deadlock victim. Clicking on it brings up a tooltip showing the last SQL batch it issued: a stored procedure execution. We can see that to execute this batch, Process 84 issued a request for an Intent Shared (IS) lock on an object, although which object isn't immediately obvious (it's Person.Address) — but was blocked. We can also see that Process 84 already owned an IX lock on a page in on the Person.Person table.
The other process (SPID 82) already owned an Exclusive (X) lock the object on which 84 had requested in IS lock, which is why 84's request was blocked. We can also see that Process 82 made a request for an S lock on a page in Person.Person to read it, but was blocked because Process 84 held an IX lock on it. So, we can get a feel for what's happened here and the processes and resources involved, but the full details are elusive.
Generally, not many developers or DBAs find SSMS's visual depiction of the deadlock graph easy to read and understand, so most stick to wading through the XML version.
Monitoring Deadlocks in SQL Monitor
SQL Monitor's key mode of operation is to raise alerts based on abnormal or undesirable conditions and properties or error on any of the monitored servers, instances, and databases. It provides a range of alerts for specific SQL Server errors and problems, including deadlocks.
SQL Monitor 8 includes a built-in alert called Deadlocks (Extended Events), which will by default raise a medium-severity alert whenever a deadlock occurs and captures the Extended Events Deadlock Graph. This means that you get through SQL Monitor the same XML Deadlock Graph as you get from Extended Events, but with some useful enhancements and advantages.
Firstly, SQL Monitor presents a much simpler, clearer graphical version of the deadlock graph, which includes all the important information you need to diagnose the problem. Secondly, it provides all the important contextual data that you need to understand about the activity on the server and on the affected database at the time of the deadlock.
Armed with all this diagnostic data, you can build a full picture of why and when the deadlocks occur and what other processes might be affected, and you can formulate the best strategy for eradicating the problem.
SQL Monitor's Graphical Deadlock Graph
In SQL Monitor, we can see immediately that a deadlock alert was raised on one of our SQL Server instances.
 Figure 4: A deadlock alert was raised.
Figure 4: A deadlock alert was raised.
Clicking on the deadlock alert will, as for any alert, take us to the Details tab of the Alerts screen. For every alert, the top of the Alerts screen (not shown) will indicate the time the alert was raised (and ended, if relevant) and the status of the alert.
In the body of the Details tab, we see the details that are specific to the alert. In this case, we see a graphical depiction of the deadlock graph, as shown in Figure 5.
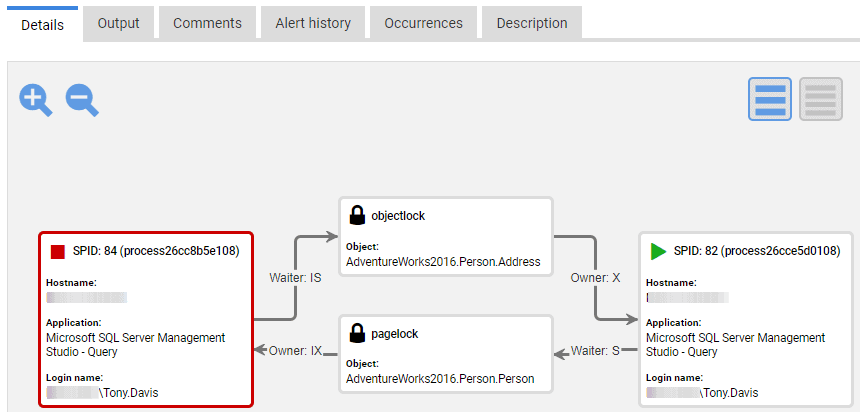 Figure 5: The Details tab for a Deadlock alert showing a graphical deadlock graph.
Figure 5: The Details tab for a Deadlock alert showing a graphical deadlock graph.
The source of the Extended Events XML Deadlock Graph is still fully available; just click on the Output tab to see it. However, in SQL Monitor, the graphical version makes it very easy to see all the critical details.
We can see straight away that Processes 84 and 82 were engaged in a deadlock, and the red border indicates that SQL Server chose Process 84 as the deadlock victim and rolled it back. For each process, we can see the machine, application, and login name for the client that issued the SQL batch.
Process 84 needed to acquire a lock on the Person.Address table to read it but was blocked since Process 82 held an X lock on this object. In turn, Process 82 needed to acquire a lock on a page in the Person.Person table to read it but was blocked since Process 84 held an IX lock on this page. At this point, SQL Server's lock monitor detects a circular lock chain and kills the suspended thread that is running the process with the lowest rollback cost.
If we click on either of the processes, we further important diagnostic details including the text of the SQL batch issued by that process. In Figure 6, we see that Process 82 issued a batch to execute a stored Procedure called Person.UpdateAddressDetails, and that the last SQL statement executed was a SELECT* query on the Person.Person table.
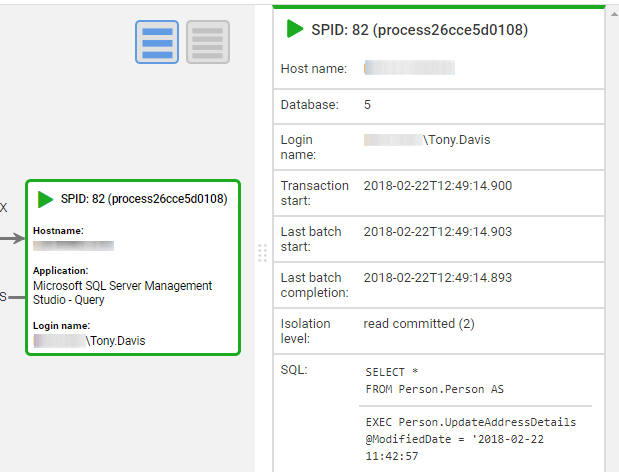 Figure 6: Details of each process involved in the deadlock.
Figure 6: Details of each process involved in the deadlock.
Likewise, if we examine the deadlock victim, we'll see that it was executing an UpdatePersonDetails stored procedure, and the last SQL statement it issued was a query on the Person.Address table.
We also see the transaction isolation level for the SQL Server session, which, in this case, was the default READCOMMITTED level. However, it's worth knowing if the application specified the use of a more restrictive transaction isolation level (such as REPEATABLEREAD or SERIALIZABLE), which forces SQL Server to lock resources for longer and is a common cause of blocking and deadlock issues.
Root Cause Analysis
The advantage of using a tool like SQL Monitor is that not only do we see the deadlock data, we get to see it within the full context of the activity occurring on the SQL Server instance around the time of the alert.
Server- and Database-Level Diagnostic Data for the Alert
Scroll down on the Alerts screen and you'll see a host of performance data arranged by tabs showing snapshots and summaries of resource usage and activity levels on the host machine and SQL Server instance at the time of the alert, as well as details of SQL Server queries and processes or other server-level processes. For example, the SQL Server tab shows a spike in the average lock wait time metric around the time of the incident.
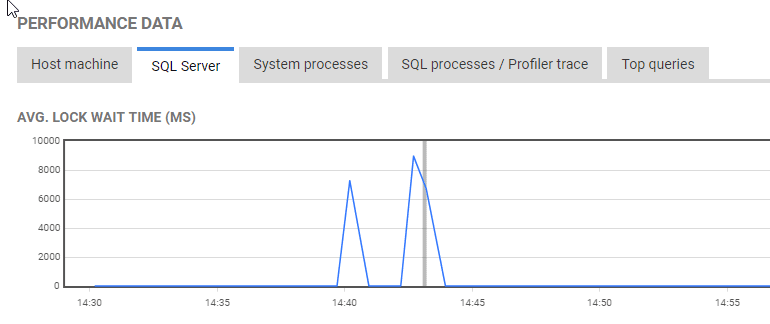 Figure 7: SQL Server instance-level metrics around the time of an alert.
Figure 7: SQL Server instance-level metrics around the time of an alert.
On the Top queries tab, we see queries that were executing around the time of the alert. By default, SQL Monitor lists them in order of duration, but by clicking on the desired column (such as Logical reads), we can reorder the results by that column.
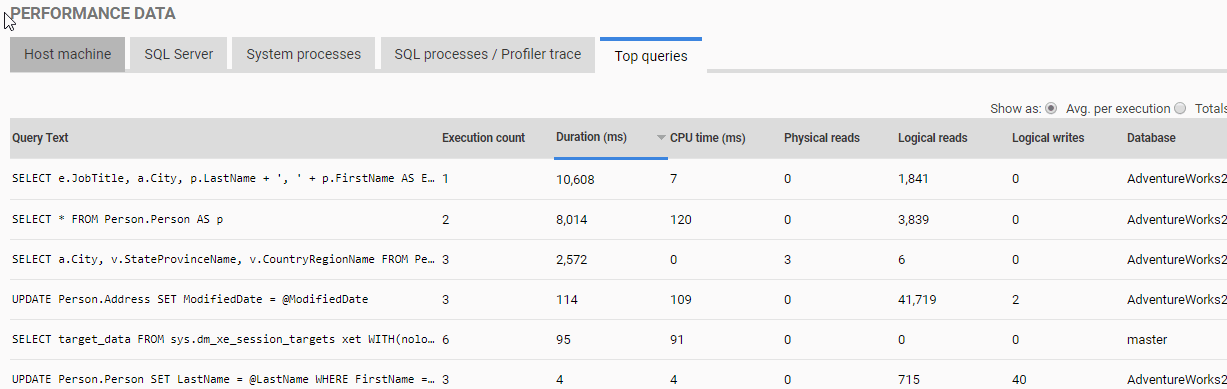 Figure 8: Top queries from the time of the deadlock alert.
Figure 8: Top queries from the time of the deadlock alert.
We recognize a few of these queries to be part of the stored procedures involved in the deadlock. If we click on the SELECT * query on Person.Person, we see the text of the query, a link to view its query plan from the plan cache, and a list of any significant waits associated with the query. In this case, we can see that it was forced to wait when trying to acquire a shared read lock.
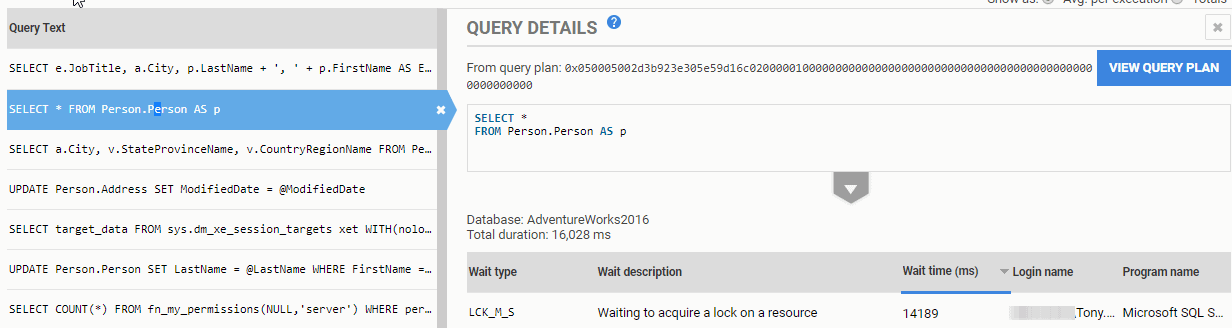 Figure 9: Details of one of the top queries.
Figure 9: Details of one of the top queries.
Figure 10 shows the associated query plan. This query is part of the Person.UpdateAddressDetails stored procedure (executed by SPID 82), and we see the plans for each statement in the stored procedure. In this case, the stored procedure (written purely for demo purposes!) starts an explicit transaction, updates the Address table, and then queries the Person table (before rolling back).
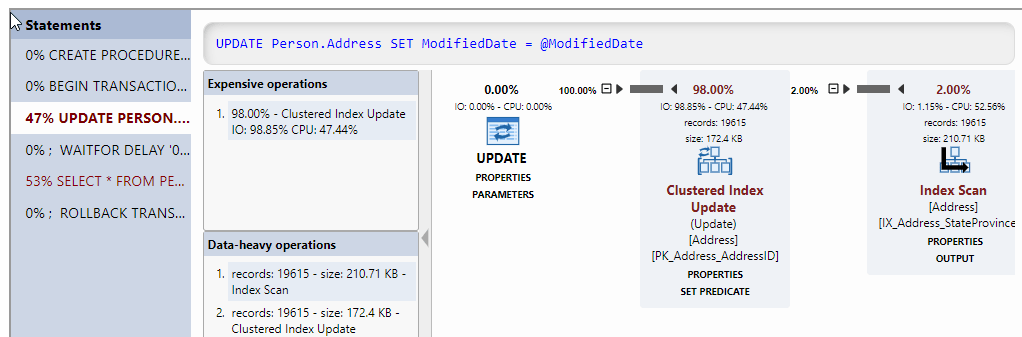 Figure 10: Query plan for one of the stored procedures executed to cause the deadlock.
Figure 10: Query plan for one of the stored procedures executed to cause the deadlock.
If we were to examine the sixth query in the list from Figure 9, we'd see that it's a query from the Person.UpdatePersonDetails stored procedure (executed by SPID 84, the deadlock victim), which accesses the same tables in the opposite order, first updating the Person table and then querying the Address table.
We can also see details of other processes and queries that may have been affected by the incident. In this case, the longest-running query in the list was a separate ad hoc query that also needed access to the Person and Address tables and suffered locking waits caused by the occurrence of the deadlock.
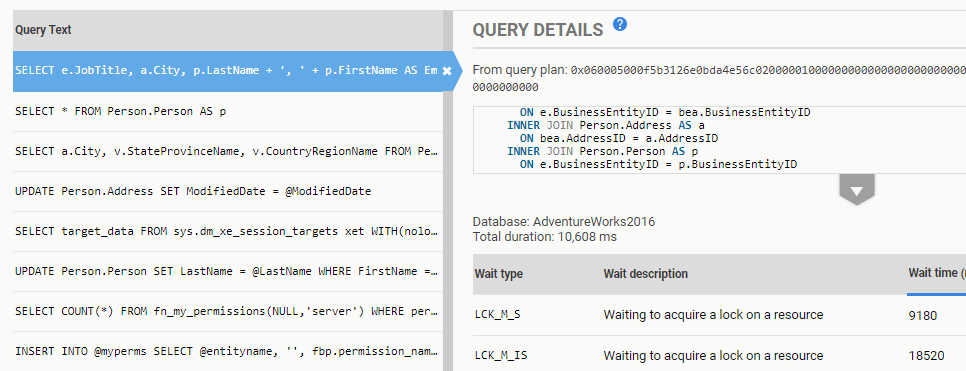 Figure 11: Other affected queries.
Figure 11: Other affected queries.
The Interactive Incident Timeline
Alongside the specific diagnostic data for an alert, it's also very useful to review the Overview graph for the affected SQL Server instance, which displays CPU, Memory, I/O, and Waits over a selected period, along with an "incident timeline" showing the occurrence of alerts. In this case, we see a cluster of alerts, including the deadlock alert we investigated. We can see a "bump" on waits around this period and a significant peak in disk IO activity.
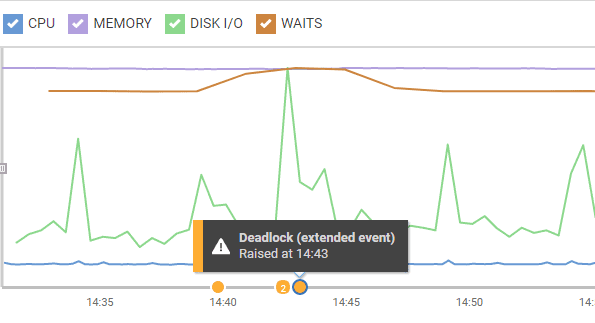 Figure 12: Interactive Overview graph and incident timeline.
Figure 12: Interactive Overview graph and incident timeline.
Scrolling down the Overviews page, we see top queries and waits that occurred in the set period, along with snapshots of server- and database-level metrics, as well as specific summaries of processes running at the time of the alert such as Blocking Processes (Top 10 by time) and others.
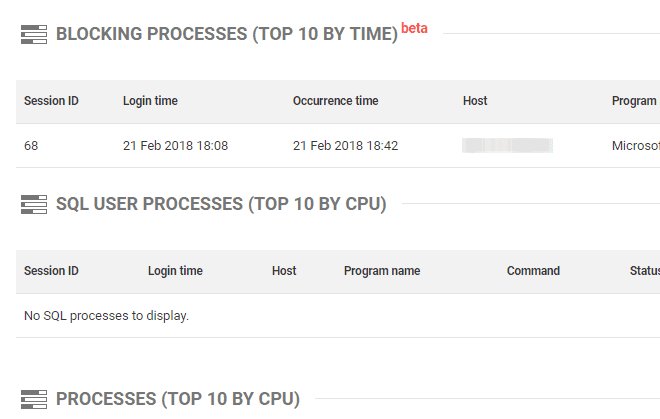 Figure 13: Blocking Processes (Top 10 by time).
Figure 13: Blocking Processes (Top 10 by time).
Next Steps
Armed with the knowledge of the queries involved in the deadlock and with the broader knowledge of concurrent activity on the server, we can take steps to resolve the problem to ensure it does not recur. This might involve query tuning, adding a new index, or modifying an existing one, or some other standard mitigation for deadlocks. Often, the cause is transactionitis, where the developer has unnecessary transactions, holds them open for too long, or places statements within a transaction that have no need to be in there.
The deadlock in this article, albeit contrived and simplified for demo purposes, was an example of a reader-writer deadlock, caused by two processes that each updated and then queried the same two tables in a different order within an explicit transaction. Questions to ask in resolving this problem would include:
- Is a case of transactionitis? In other words, given that in neither case does the stored procedure included multiple data modification statements that need to form an atomic unit, is the explicit transaction necessary?
- Can we move either
SELECTstatement outside the transaction? - Can we reverse the order of either, or both, sets of statements?
If any of these changes are possible, the deadlock will be prevented, though the third solution on the list relies on the use of the default Read Committed isolation level, where shared locks are released no later than the end of the query.
For more general advice on coding techniques to help avoid deadlocks, see the Reducing Deadlocks article in the Redgate documentation (reference below).
Summary
With SQL Monitor, you will be alerted to deadlocks as they happen, giving you the chance to recover any lost processes and put procedures in place to minimize their occurrence in the future.
SQL Monitor 8 supports the Extended Events deadlock graph and adds much simpler and clearer visualization than is available in SSMS. With the added benefit of snapshots of historic data from the time of the alert, you can start to build a full picture of what happened and what was affected as a result.
Further Reading
- SQL Server Deadlocks by Example, Simple-Talk article by Gail Shaw
- Handling Deadlocks in SQL Server, Simple-Talk article by Jonathan Kehayias
- Reducing deadlocks, Redgate documentation
- Detecting and Ending Deadlocks, Microsoft TechNet resource
