RDF Storage: Apache Jena TDB

Overview
RDF Storage is a database used to store and query RDF data. RDF stands for Resource Description Framework, which is a standard model for describing and interchanging data on the web.
RDF storage contains collections of RDF statements, which are three-part statements known as triples. Each triple has a resource (subject), property (predicate), and property value (object).

For example, the following statement represents “Alphabet Inc has a CEO named Pichai Sundararajan.”.

Moreover, RDF statements can be linked together to create a graph. For instance:
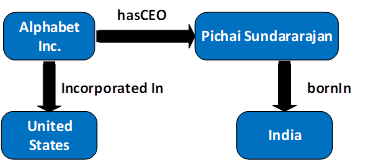
There are many RDF storages available in the market, such as MarkLogic, Amazon Neptune, Virtuoso, and Apache Jena – TDB. This article only introduces Apache Jena – TDB, which is a free and open-source Java framework to manage RDF data.
Apache Jena TDB
TDB is a component of Apache Jena for RDF storage and query. Apache Jena is a free and open-source Java web framework that provides several APIs and components to process RDF data. The following picture shows the framework architecture of Apache Jena:
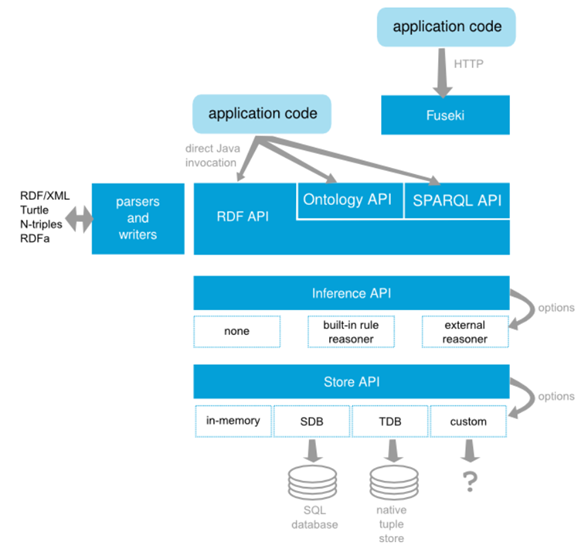
The core APIs of Apache Jena is the RDF API used to process RDF data and SPARQL API used to query RDF data.
SPARQL is an RDF query language able to retrieve and manipulate data stored in RDF format, including Apache Jena TDB. It is similar to SQL in a relational database. Typically, the SPARQL consists of two parts:
- The SELECT clause identifies the variables (prefixed with ‘?’) to appear in the query results
- The WHERE clause provides the triple pattern to match against the RDF data
xxxxxxxxxx
SELECT ?subject ?predicate ?object
WHERE {
?subject ?predicate ?object
}
For example, to query who is the CEO of Alphabet Inc. from the above example, the SPARQL looks like:
xxxxxxxxxx
SELECT ?NAME
WHERE {
“Alphabet Inc.” hasCEO ?Name
}
The value of the variable (?NAME) will be “Pichai Sundararajan”.
The SPARQL can be sent to the Apache Jena TDB through the TDB command line (bat\tdb2_tdbquery.bat) or the Apache Jena Fuseki component. Apache Jena Fuseki is a SPARQL server that can run as a Java web application (WAR file) and provide the web interface for users to send SPARQL queries to the Apache Jena TDB.
Use Case Scenario: Open PermID Entity Bulk Download
In this section, I will demonstrate how to load RDF data into the Apache Jena TDB in the real use case scenario. To do this, I will use as an example, Open PermID from Refinitiv. Open PermID is freely available at https://permid.org/.
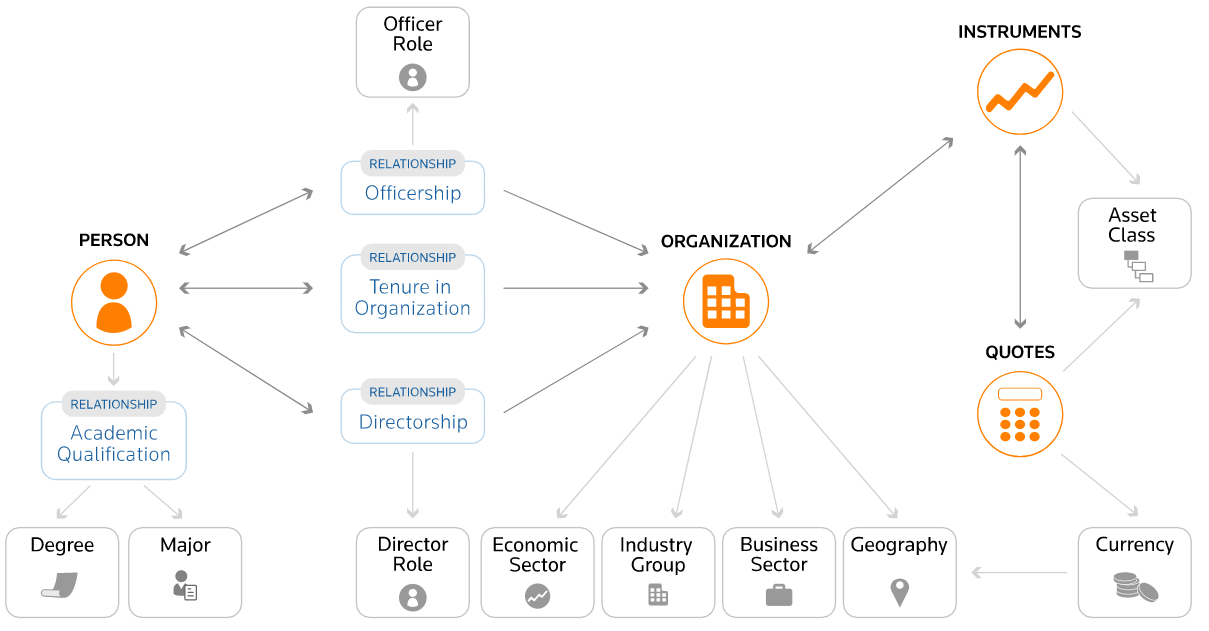
PermID is a shortening of “Permanent Identifier”, which is a machine-readable number assigned to entities, securities, organizations (companies, government agencies, universities, etc.), quotes, individuals, and more.
It is specifically designed for use by machines to reference related information programmatically. Open PermID also provides bulk files (one per entity type), containing the complete lists of the entities including organization, instrument, quote, asset class, currency, instrument code, and person entities. These files are updated weekly. The following picture represents relationships among entities.
The following steps demonstrate how to load organization, industry, and quote files into the Apache Jena TDB. Apache Jena and Apache Jena Fuseki must be installed properly on the machine. To install Apache Jena and Apache Jane Fuseki, please refer to the Apache Jena website.
First download organization, industry, and quote files from the permid.org website. There are two types of files (ttl and ntriples). In this step, ntriples files will be used.
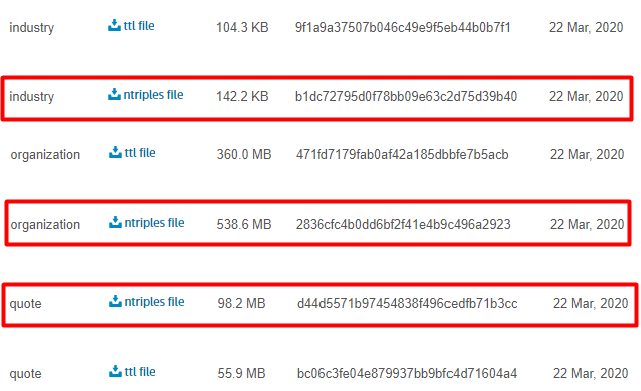
After downloading, decompress those files and rename the files’ extensions from ntriples to nt.
Next, run the following command in the Apache Jena directory to load those files to Apache Jena TDB. The location of the database is at c:\workspace\database.
xxxxxxxxxx
C:\workspace\apache-jena-3.14.0>bat\tdb2_tdbloader.bat --loc c:\workspace\database OpenPermID-bulk-organization-xxx.nt OpenPermID-bulk-industry-xxx.nt OpenPermID-bulk-quote-xxx.nt
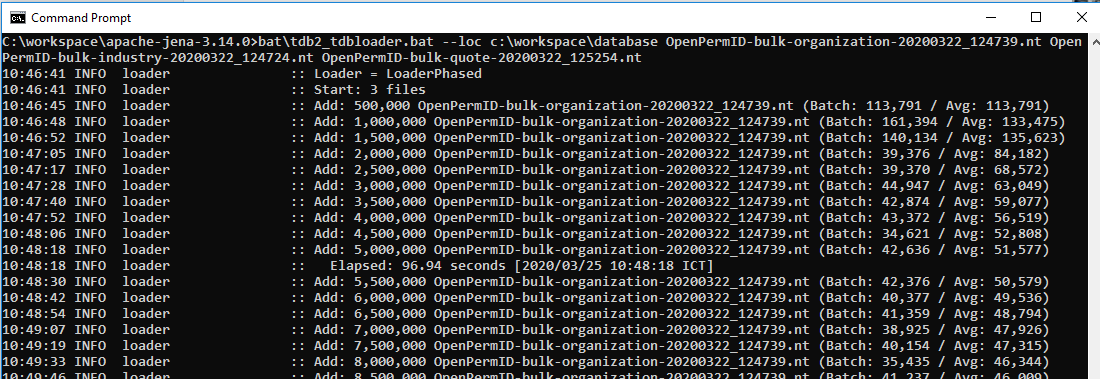
It may take more than four minutes to populate the database.
At this point, the database is ready and SPARQL can be used to query the database. For example, the following SPARQL lists active US companies in the Healthcare Providers and Services industry.
prefix skos: <http://www.w3.org/2004/02/skos/core#>
prefix vcard: <http://www.w3.org/2006/vcard/ns#>
prefix tr-org: <http://permid.org/ontology/organization/>
prefix tr-fin: <http://permid.org/ontology/financial/>
SELECT ?orgPermID ?orgName ?exchangeCode ?ticker ?mic ?ric
WHERE {
?industry skos:prefLabel "Healthcare Providers & Services" .
?orgPermID tr-org:hasPrimaryIndustryGroup ?industry .
?orgPermID tr-org:isIncorporatedIn <http://sws.geonames.org/6252001/> .
?orgPermID tr-org:hasActivityStatus tr-org:statusActive .
?orgPermID vcard:organization-name ?orgName .
?orgPermID tr-fin:hasOrganizationPrimaryQuote ?orgQuote .
OPTIONAL {?orgQuote tr-fin:hasExchangeCode ?exchangeCode .}
OPTIONAL {?orgQuote tr-fin:hasExchangeTicker ?ticker .}
OPTIONAL {?orgQuote tr-fin:hasMic ?mic .}
OPTIONAL {?orgQuote tr-fin:hasRic ?ric .}
}
The query can be run through the tdb2_tdbquery.bat command or Apache Jena Fuseki.
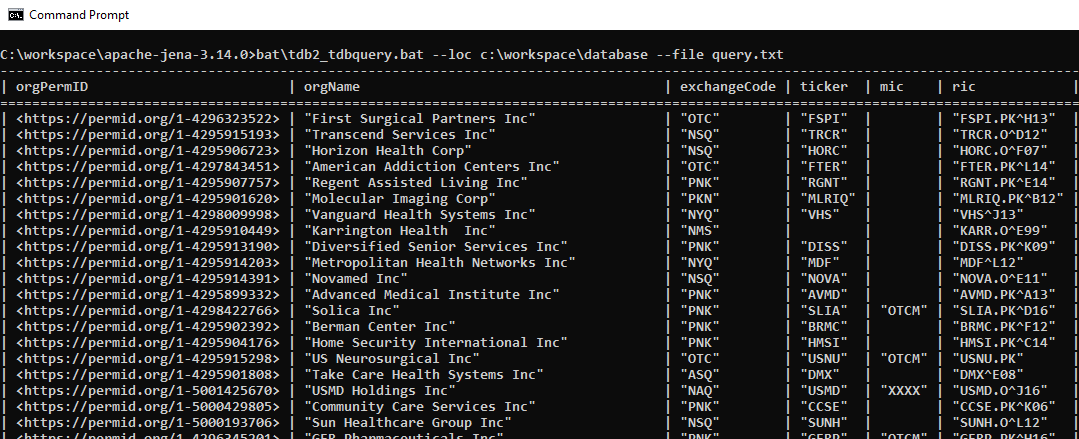
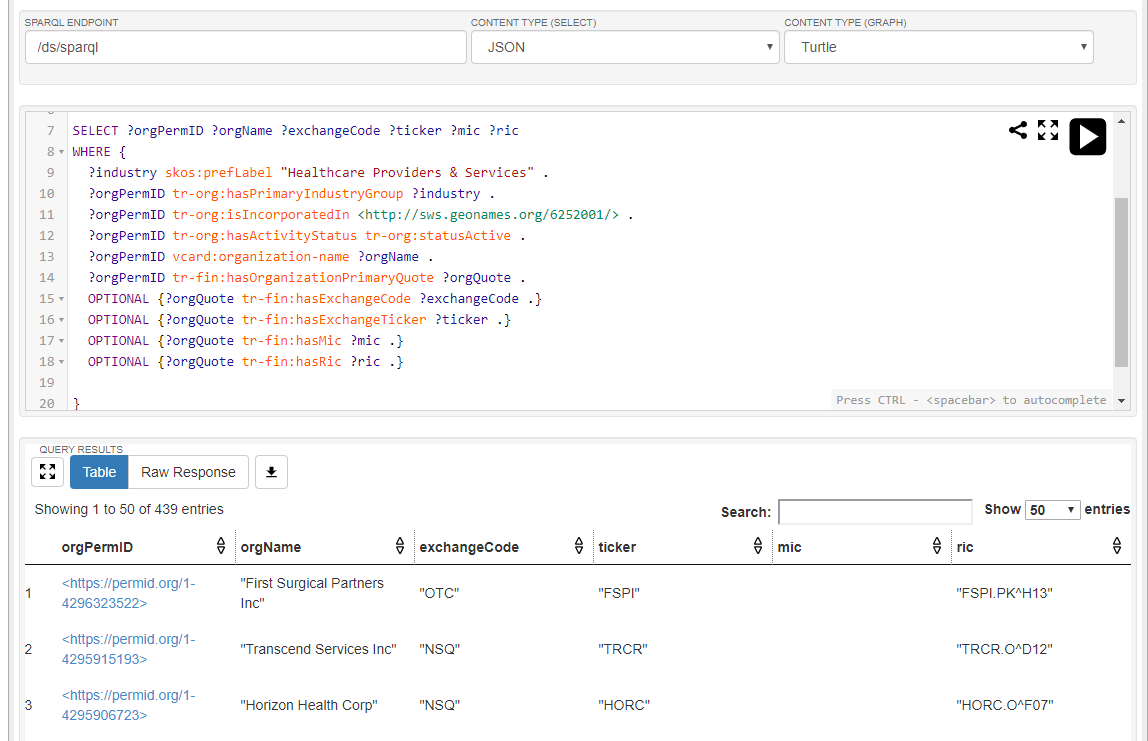
The results contain organizations’ PermIDs, organization names, exchange codes, tickers, Market Identifier Codes (MICs), and Reuters Instrument Codes (RICs).
Summary
Apache Jena TDB is a free RDF database used to store and query RDF data. RDF is a standard model for describing and interchanging data on the web. The underlying structure of RDF is a collection of triples, each consisting of a subject, a predicate, and an object.
Triples can be linked together to create graphs. Therefore, RDF storage is a type of graph database. The database can be populated with the tdb2_tdbloader.bat command. It uses SPARQL as a query language. The query can be run through the tdb2_tdbquery.bat command or Apache Jena Fuseki.
References
- Apache Jena. n.d. Apache Jena. [online] Available at: <https://jena.apache.org/index.html> [Accessed 25 March 2020].
- Apache Jena. n.d. Apache Jena - Apache Jena Fuseki. [online] Available at: <https://jena.apache.org/documentation/fuseki2/index.html> [Accessed 25 March 2020].
- Apache Jena. n.d. Apache Jena - Jena Architecture Overview. [online] Available at: <https://jena.apache.org/about_jena/architecture.html> [Accessed 26 March 2020].
- Apache Jena. n.d. Apache Jena - TDB. [online] Available at: <https://jena.apache.org/documentation/tdb/index.html> [Accessed 25 March 2020].
- Cambridge Semantics. n.d. Learn RDF. [online] Available at: <https://www.cambridgesemantics.com/blog/semantic-university/learn-rdf/> [Accessed 25 March 2020].
- Open PermID. n.d. Permid. [online] Available at: <https://permid.org/> [Accessed 25 March 2020].
- W3C. 2014. RDF - Semantic Web Standards. [online] Available at: <https://www.w3.org/RDF/> [Accessed 25 March 2020].
- Db-engines.com. n.d. RDF Stores - DB-Engines Encyclopedia. [online] Available at: <https://db-engines.com/en/article/RDF+Stores> [Accessed 25 March 2020].
- Wikipedia, the free encyclopedia. 2020. SPARQL. [online] Available at: <https://en.wikipedia.org/wiki/SPARQL> [Accessed 25 March 2020].
- W3C. 2013. SPARQL 1.1 Overview. [online] Available at: <https://www.w3.org/TR/2013/REC-sparql11-overview-20130321/> [Accessed 25 March 2020].
- Wikipedia, the free encyclopedia. 2019. Triplestore. [online] Available at: <https://en.wikipedia.org/wiki/Triplestore> [Accessed 25 March 2020].
- Ontotext. n.d. What Is RDF? Making Data Triple Their Power. [online] Available at: <https://www.ontotext.com/knowledgehub/fundamentals/what-is-rdf/> [Accessed 25 March 2020].
