Game of Microservices

This article covers some variants of Microservices design patterns and some special considerations. All categories in this article are very short, precise and covers to the point - just like a shooter!
Microservices a paradigm that is one of the most discussed and debated topic in many phases of application development and delivery. The concept had a humble beginning during the time of the aging monolithic architecture which was very sluggish to move at a fast pace. Enterprises found it difficult to deploy monolithic applications at a pace to match the changing business needs or customer requirements. Microservices is an architecture pattern which helps enterprises to move fast and deploy new features at a rapid pace. It leverages small teams allowing them to design, develop and deploy each services atomically as they have full ownership over the life-cycle of their applications.
Microservice architecture gained rapid adoption and greater acceptance due to it's development & deployment pace and maintenance ease. There have been tremendous advancements in this area which will be covered in this article. The below image represents few services which functions together to build a larger e-Commerce application.
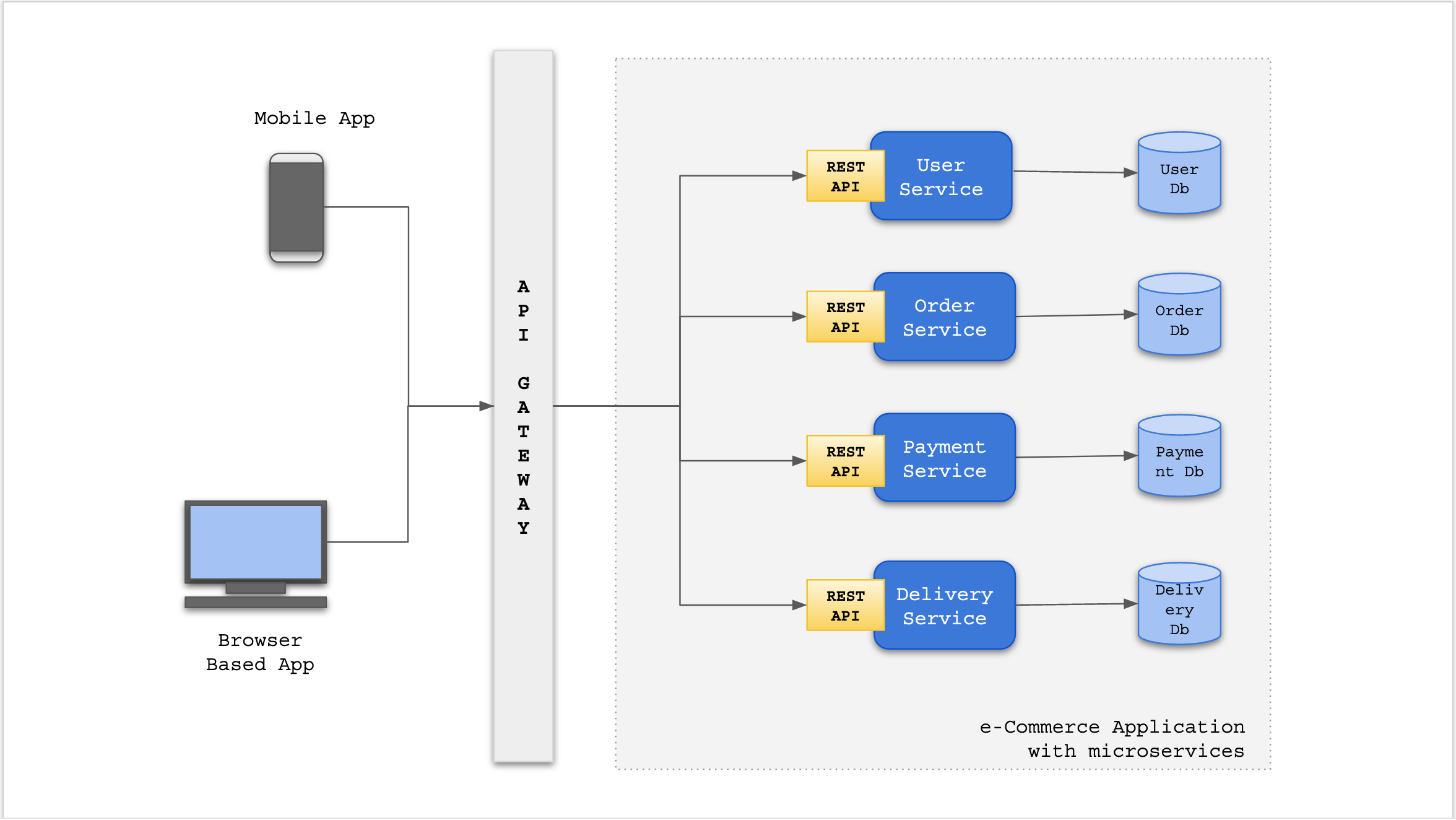
Microservices Face-off
There are plenty resources on the internet that speaks about the long-term benefits of Microservices, it's advantages, how it helps organizations/teams to move at a rapid pace in addition with CI/CD pipelines etc. But there are other aspects in this architecture that needs to be addressed and the following sections covers those aspects.
Database per Service
A microservice works best when it has it's own private database (database per service). This ensures loose coupling with other services and the data integrity will be maintained i.e. each microservice controls and updates it's own data. It gives no scope for manual or software systems (applications or automated scripts) that would change data owned by a particular service. All read and write queries for data will be using well defined APIs.
One main point to be highlighted here is, what if a particular microservice has more traffic compared to other microservices? This creates a hot-spot in the application architecture. A hot-spot service is one which handles many requests compared to the other microservices. For example consider a dating application (like Tinder) which is built up of many microservices like, user profile service, photo service, chat service, etc. A typical example of a hot-spot in this example could be the 'User Profile Service'. This is because when many users are online, they are typically browsing or viewing profiles of other users (with profile pictures) and this could yield in couple thousands (or millions) requests per second. This requires the application to be scaled or else it would increase the latency leading to a bad user experience. The 'User Profile Service' can be scaled horizontally but it's database has to be tuned differently to handle additional traffic like sharding, process write requests to primary database and read requests from slave setups, add a cache layer to store most frequently accessed profiles and pictures.
Distributed Transactions & Queries
The next question is, "How to maintain data consistency across different microservices when there are distributed transactions?" In such cases we follow the SAGA-based approach in which services can maintain their data consistency allowing distributed transactions. SAGA-based microservice architecture is covered in the next section.
Another issue is querying for data that resides in two or more microservices. How can this be solved as we understand microservices follow the database per service mandate. There is no option to join tables across databases as we lose data integrity. If the data is stored in different types one service uses an RDBMS while other NoSQL like MongoDB, then it is impossible to join tables and get a consolidated resultset. This limitation is overcome by the CQRS and Event Sourcing approach.
Microservices Based on SAGA
A SAGA is a sequence of local transactions. In SAGA, a set of services work in tandem to execute a piece of functionality and each local transaction updates the data in one service and sends an event or a message that triggers the next transaction in other services.
The architecture for microservices mandates (usually) the Database per Service paradigm. The monolithic approach though having it's own operational issues, it does deal with transactions very well. It truly offers a inherent mechanism to provide ACID transactions and also roll-back in cases of failure. In contrast, in the Microservices approach as we have distributed the data and the datasources based on the service, there might be cases where some transactions, spreads over multiple services. Achieving transactional guarantees in such cases is of high importance or else we tend to lose data consistency and the application can be in an unexpected state. A mechanism to ensure data consistency across services is following the SAGA approach. SAGA ensures data consistency across services.
Consider Figure 1, which is an example of a very high level working of an e-commerce platform. The platform ensures that a when a user (customer) places an order, it will ensure that the payment is initiated and after a successful payment and the order will be delivered. Since Orders, Payments and Delivery services owns different databases the application cannot simply use a local ACID transaction.
Types of SAGA implementations:
- Choreography - An event based pattern to handle distributed transactions. The events are handled asynchronously and the transactions would be completed.
- Orchestration - A command based pattern which has an orchestration mechanism which takes care of delegating commands to dependent microservices.
Choreography
In Choreography based design pattern, every service registers for events with a Queue. Based on the events the corresponding actions will be executed.
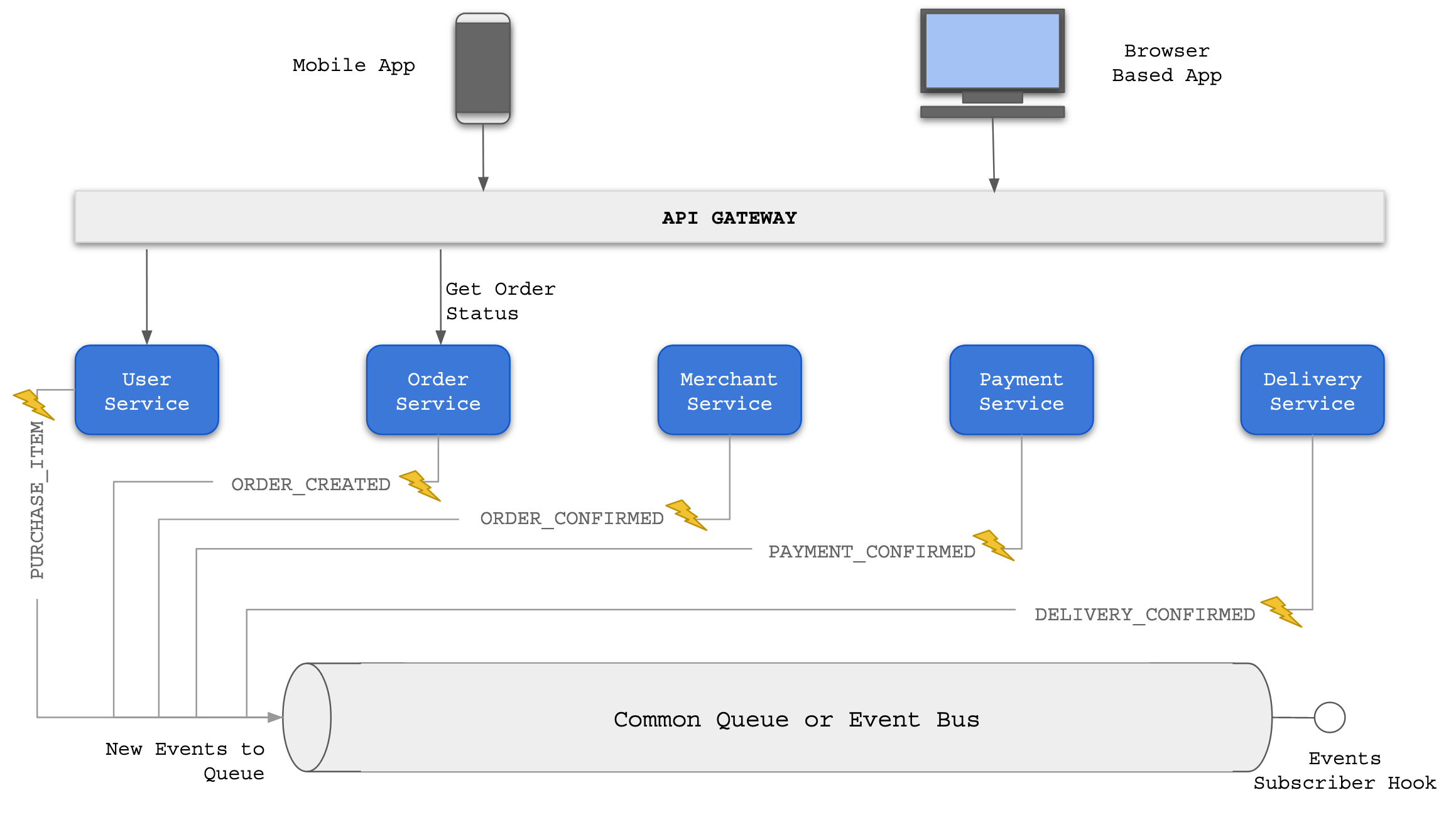

In above example 'Order Service' registers for all events because it is collating information and maintaining a state of an order. Each service generates different events based on the work flow.
The main disadvantage of this approach is that too many events can make the system convoluted and also end up in a dead lock situation.
Orchestration
In this design pattern, there is a central 'Orchestrator Service' that controls the whole work flow between microservices. This control is achieved by sending commands to various services to which the services respond with an acknowledgement back. The Orchestrator is aware of all the services it has to call in order to execute a certain functionality. With this architecture, we can achieve data consistency across microservices.
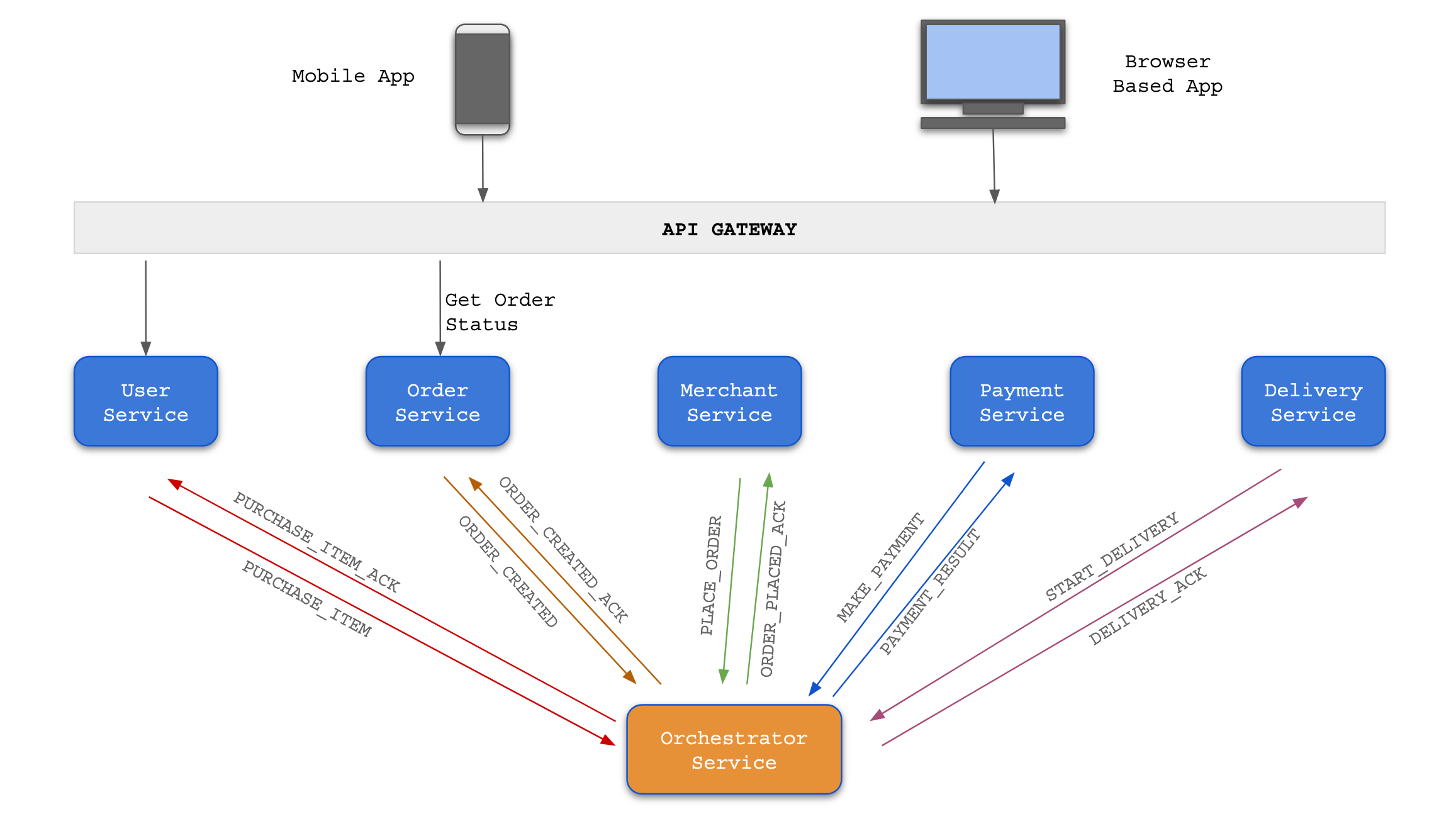

- The 'Orchestrator Service' poses a single point of failure.
- Coupling between services increases as the 'Orchestrator Service' has to be aware of all the services.
- Any change in a service may need a change in the 'Orchestrator Service' as well. This is against the microservices architecture.
CQRS and Event Sourcing
CQRS stands for Command Query Responsibility Segregation. CQRS is a microservice design pattern which has two different service layers, a Command layer and Query layer.
Command layer includes a service, model and database. This layer is used to manage data for all insert, update and delete operations. Query layer will also include it's own service, model and database and provides functionality to query data (that may include data from other services as well).
Event Sourcing - To understand Event Sourcing, we have to understand the underlying challenge in maintaining data consistency across services. In the above e-Commerce example, consider a case where a user account has to be suspended due to some fraudulent activities. In such a case, the following sequence of actions have to be executed - temporarily suspend the user account until issue is resolved, cancel any outstanding orders, block any ongoing or outstanding payments, cancel all pending deliveries. The following services have to be invoked to execute the above mentioned actions.
- 'User Service' - to suspend the user account.
- 'Order Service' - to cancel all outstanding orders.
- 'Payment Service' - to block any ongoing or outstanding payments.
- 'Delivery Service' - to be informed to not proceed with any further deliveries.
In the above sequence, if any of the action above fails due to any reason like 'User Service' is downtime then the whole work flow doesn't promise in a user account suspension. The system may not execute the other actions like cancelling outstanding orders or blocking further payments. In order the mitigate this and similar use cases we use the Event Sourcing pattern.
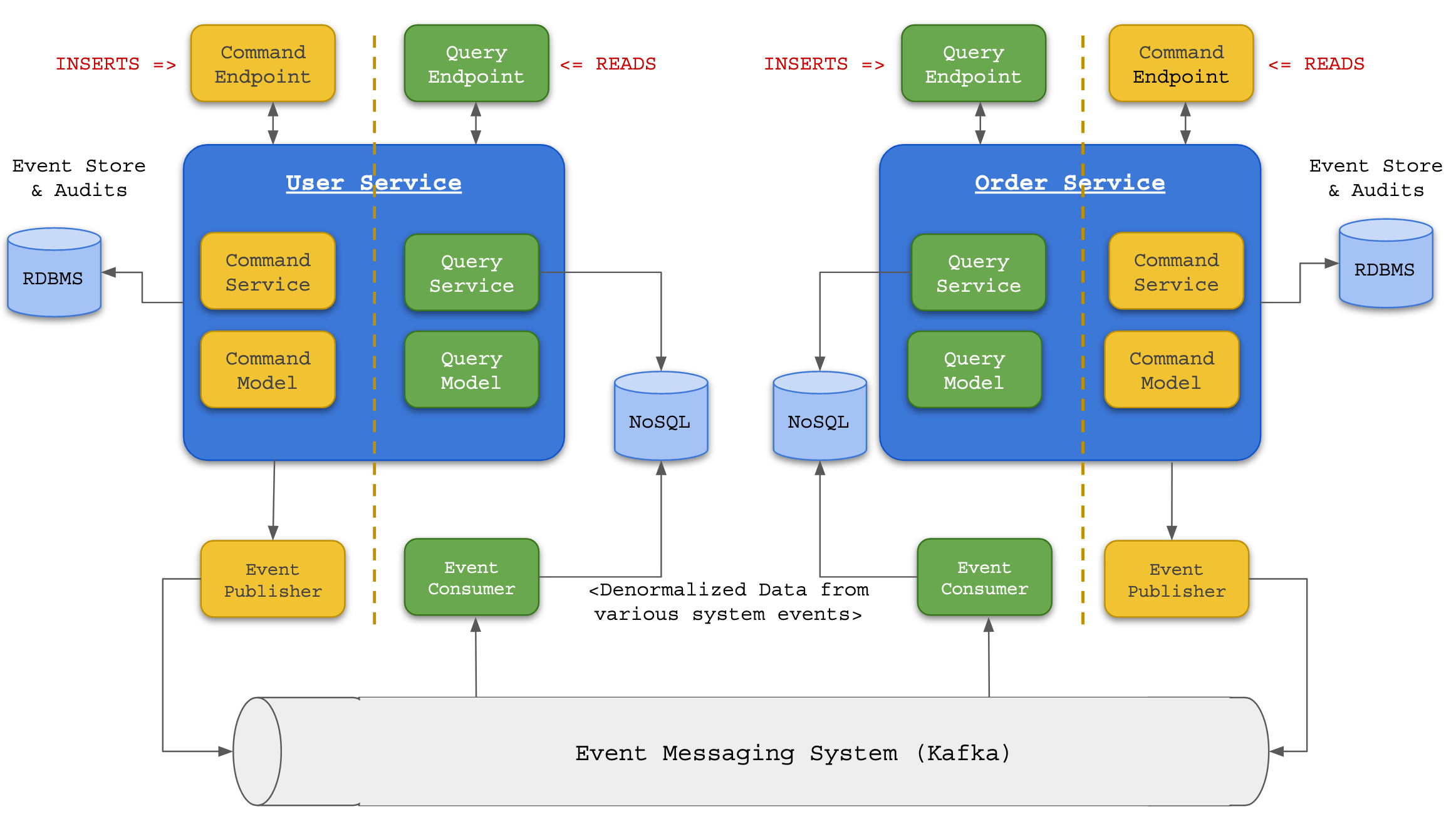

Advantages of CQRS and Event Sourcing:
- Leveraging microservices architecture for modularity and database per service.
- Leverage event sourcing for handling atomic operations.
- Maintain historical (audit) data for analytics with event sourcing.
- Request loads can be distributed between inserts and read operations.
- Insert and Read DTO models can be completely different.
- Query services can respond with additional denormalized data from different events from various services.
Disadvantages of CQRS and Event Sourcing:
- Additional maintenance of services and infrastructural costs.
- Troubleshooting and handling events that are published can be time-consuming.
This article covers some fundamental aspects of microservices and some of their patterns. The next article will cover how the OSS layers helps in load balancing, centralized configuration management, service discovery and application traceability.
