Step-By-Step Guide To Building a Serverless Text-to-Speech Solution Using Golang on AWS

The field of machine learning has advanced considerably in recent years, enabling us to tackle complex problems with greater ease and accuracy. However, the process of building and training machine learning models can be a daunting task, requiring significant investments of time, resources, and expertise. This can pose a challenge for many individuals and organizations looking to leverage machine learning to drive innovation and growth.
That's where pre-trained AI Services come in and allow users to leverage the power of machine learning without having extensive machine learning expertise and needing to build models from scratch - thereby making it more accessible for a wider audience. AWS machine learning services provide ready-made intelligence for your applications and workflows and easily integrate with your applications. And, if you add Serverless to the mix, well, that's just icing on the cake, because now you can build scalable and cost-effective solutions without having to worry about the backend infrastructure.
In this blog post, you will learn how to build a serverless text-to-speech conversion solution using Amazon Polly, AWS Lambda, and the Go programming language. Text files uploaded to Amazon Simple Storage Service (S3) will trigger a Lambda function which will convert it into an MP3 audio format (using the AWS Go SDK) and store it in another S3 bucket.
The Lambda function is written using the aws-lambda-go library and you will use the Infrastructure-Is-Code paradigm to deploy the solution with AWS CDK (thanks to the Go bindings for AWS CDK).
As always, the code is available on GitHub.
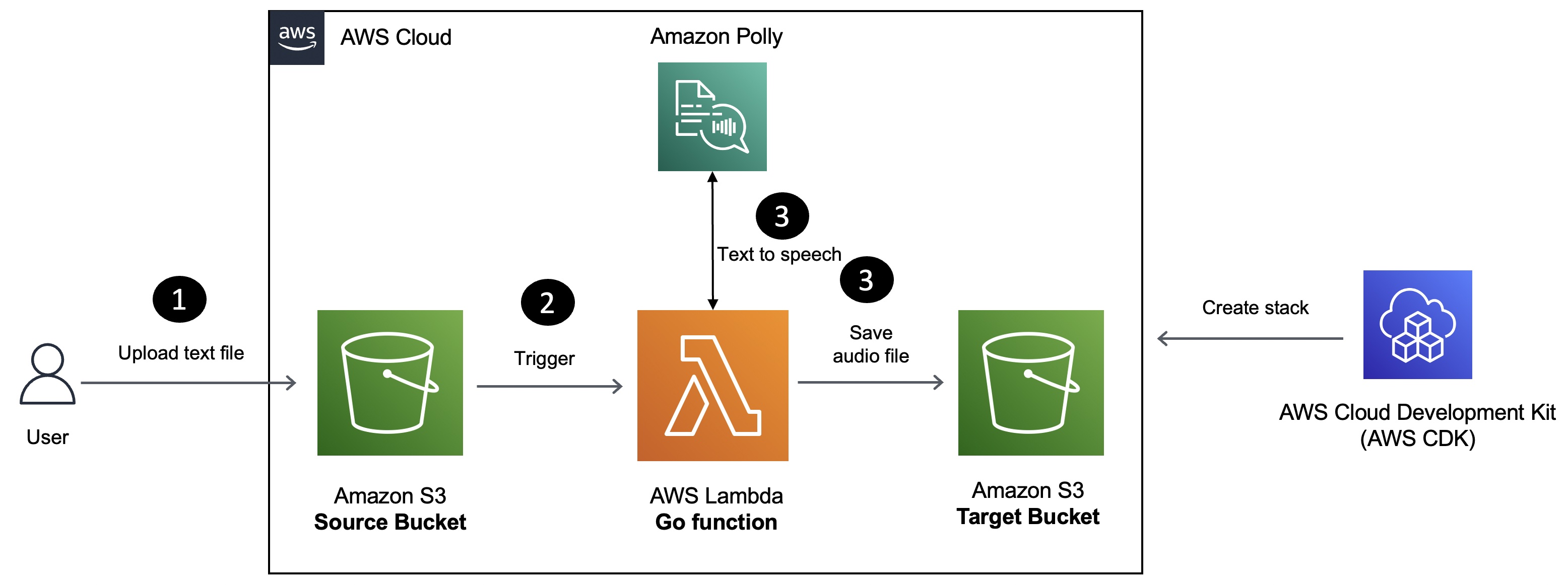
Introduction
Amazon Polly is a cloud-based service that transforms written text into natural-sounding speech. By leveraging Amazon Polly, you can create interactive applications that enhance user engagement and make your content more accessible. With support for various languages and a diverse range of lifelike voices, Amazon Polly empowers you to build speech-enabled applications that cater to the needs of customers across different regions while selecting the perfect voice for your audience.
Common use cases for Amazon Polly include, but are not limited to, mobile applications such as newsreaders, games, eLearning platforms, accessibility applications for visually impaired people, and the rapidly growing segment of the Internet of Things (IoT).
- E-learning and training: Create engaging audio content for e-learning courses and training materials, providing a more immersive learning experience for students.
- Accessibility: Convert written content into speech, making it accessible to people with visual or reading impairments.
- Digital media: Generate natural-sounding voices for podcasts, audiobooks, and other digital media content, enhancing the overall listening experience.
- Virtual assistants and chatbots: Use lifelike voices to create more natural-sounding responses for virtual assistants and chatbots, making them more user-friendly and engaging.
- Call centers: Create automated voice responses for call centers, reducing the need for live agents and improving customer service efficiency.
- IoT devices: Integrate it into Internet of Things (IoT) devices, providing a voice interface for controlling smart home devices and other connected devices.
Overall, Amazon Polly's versatility and scalability make it a valuable tool for a wide range of applications.
Let's learn Amazon Polly with a hands-on tutorial.
Prerequisites
Before you proceed, make sure you have the following installed:
- Go programming language (v1.18 or higher)
- AWS CDK
- AWS CLI
Clone the project and change to the right directory:
git clone https://github.com/abhirockzz/ai-ml-golang-polly-text-to-speech
cd ai-ml-golang-polly-text-to-speech
Use AWS CDK To Deploy the Solution
The AWS Cloud Development Kit (AWS CDK) is a framework that lets you define your cloud infrastructure as code in one of its supported programming and provision it through AWS CloudFormation.
To start the deployment, simply invoke cdk deploy and wait for a bit. You will see a list of resources that will be created and will need to provide your confirmation to proceed.
cd cdk
cdk deploy
# output
Bundling asset LambdaPollyTextToSpeechGolangStack/text-to-speech-function/Code/Stage...
Synthesis time: 5.94s
//.... omitted
Do you wish to deploy these changes (y/n)? y
Enter y to start creating the AWS resources required for the application.
If you want to see the AWS CloudFormation template which will be used behind the scenes, run cdk synth and check the cdk.out folder.
You can keep track of the stack creation progress in the terminal or navigate to the AWS console: CloudFormation > Stacks > LambdaPollyTextToSpeechGolangStack.
Once the stack creation is complete, you should have:
- Two S3 buckets - Source bucket to upload text files and the target bucket to store the converted audio files
- A Lambda function to convert text to audio using Amazon Polly
- A few other components (like IAM roles, etc.)
You will also see the following output in the terminal (resource names will differ in your case). In this case, these are the names of the S3 buckets created by CDK:
LambdaPollyTextToSpeechGolangStack
Deployment time: 95.95s
Outputs:
LambdaPollyTextToSpeechGolangStack.sourcebucketname = lambdapollytexttospeechgolan-sourcebuckete323aae3-sh3neka9i4nx
LambdaPollyTextToSpeechGolangStack.targetbucketname = lambdapollytexttospeechgolan-targetbucket75a012ad-1tveajlcr1uoo
.....
You can now try out the end-to-end solution!
Convert Text to Speech
Upload a text file to the source S3 bucket. You can use the sample text files provided in the GitHub repository. I will be using the S3 CLI to upload the file, but you can use the AWS console as well.
export SOURCE_BUCKET=<enter source S3 bucket name - check the CDK output>
aws s3 cp ./file_1.txt s3://$SOURCE_BUCKET
# verify that the file was uploaded
aws s3 ls s3://$SOURCE_BUCKET
Wait for a while and check the target S3 bucket. You should see a new file with the same name as the text file you uploaded, but with a .mp3 extension - this is the audio file generated by Amazon Polly.
Download it using the S3 CLI and play it to verify that the text was converted to speech.
export TARGET_BUCKET=<enter target S3 bucket name - check the CDK output>
# list contents of the target bucket
aws s3 ls s3://$TARGET_BUCKET
# download the audio file
aws s3 cp s3://$TARGET_BUCKET/file_1.mp3 .
Don’t Forget To Clean Up
Once you're done, to delete all the services, simply use:
cdk destroy
#output prompt (choose 'y' to continue)
Are you sure you want to delete: LambdaPollyTextToSpeechGolangStack (y/n)?
You were able to set up and try the complete solution. Before we wrap up, let's quickly walk through some of the important parts of the code to get a better understanding of what's going on behind the scenes.
Code Walkthrough
We will only focus on the important parts - some of the code has been omitted for brevity.
CDK
You can refer to the complete CDK code here.
We start by creating the source and target S3 buckets.
sourceBucket := awss3.NewBucket(stack, jsii.String("source-bucket"), &awss3.BucketProps{
BlockPublicAccess: awss3.BlockPublicAccess_BLOCK_ALL(),
RemovalPolicy: awscdk.RemovalPolicy_DESTROY,
AutoDeleteObjects: jsii.Bool(true),
})
targetBucket := awss3.NewBucket(stack, jsii.String("target-bucket"), &awss3.BucketProps{
BlockPublicAccess: awss3.BlockPublicAccess_BLOCK_ALL(),
RemovalPolicy: awscdk.RemovalPolicy_DESTROY,
AutoDeleteObjects: jsii.Bool(true),
})
Then, we create the Lambda function and grant it the required permissions to read from the source bucket and write to the target bucket. A managed policy is also attached to the Lambda function's IAM role to allow it to access Amazon Polly.
function := awscdklambdagoalpha.NewGoFunction(stack, jsii.String("text-to-speech-function"),
&awscdklambdagoalpha.GoFunctionProps{
Runtime: awslambda.Runtime_GO_1_X(),
Environment: &map[string]*string{"TARGET_BUCKET_NAME": targetBucket.BucketName()},
Entry: jsii.String(functionDir),
})
sourceBucket.GrantRead(function, "*")
targetBucket.GrantWrite(function, "*")
function.Role().AddManagedPolicy(awsiam.ManagedPolicy_FromAwsManagedPolicyName(jsii.String("AmazonPollyReadOnlyAccess")))
We add an event source to the Lambda function to trigger it when a new file is uploaded to the source bucket.
function.AddEventSource(awslambdaeventsources.NewS3EventSource(sourceBucket, &awslambdaeventsources.S3EventSourceProps{
Events: &[]awss3.EventType{awss3.EventType_OBJECT_CREATED},
}))
Finally, we export the bucket names as CloudFormation output.
awscdk.NewCfnOutput(stack, jsii.String("source-bucket-name"),
&awscdk.CfnOutputProps{
ExportName: jsii.String("source-bucket-name"),
Value: sourceBucket.BucketName()})
awscdk.NewCfnOutput(stack, jsii.String("target-bucket-name"),
&awscdk.CfnOutputProps{
ExportName: jsii.String("target-bucket-name"),
Value: targetBucket.BucketName()})
Lambda Function
You can refer to the complete Lambda Function code here.
func handler(ctx context.Context, s3Event events.S3Event) {
for _, record := range s3Event.Records {
sourceBucketName := record.S3.Bucket.Name
fileName := record.S3.Object.Key
err := textToSpeech(sourceBucketName, fileName)
}
}
The Lambda function is triggered when a new file is uploaded to the source bucket. The handler function iterates over the S3 event records and calls the textToSpeech function to convert the text to speech.
Let's go through the textToSpeech function.
func textToSpeech(sourceBucketName, textFileName string) error {
voiceID := types.VoiceIdAmy
outputFormat := types.OutputFormatMp3
result, err := s3Client.GetObject(context.Background(), &s3.GetObjectInput{
Bucket: aws.String(sourceBucketName),
Key: aws.String(textFileName),
})
buffer := new(bytes.Buffer)
buffer.ReadFrom(result.Body)
text := buffer.String()
output, err := pollyClient.SynthesizeSpeech(context.Background(), &polly.SynthesizeSpeechInput{
Text: aws.String(text),
OutputFormat: outputFormat,
VoiceId: voiceID,
})
var buf bytes.Buffer
_, err = io.Copy(&buf, output.AudioStream)
outputFileName := strings.Split(textFileName, ".")[0] + ".mp3"
_, err = s3Client.PutObject(context.TODO(), &s3.PutObjectInput{
Body: bytes.NewReader(buf.Bytes()),
Bucket: aws.String(targetBucket),
Key: aws.String(outputFileName),
ContentType: output.ContentType,
})
return nil
}
- The
textToSpeechfunction first reads the text file from the source bucket. - It then calls the Amazon Polly
SynthesizeSpeechAPI to convert the text to speech. - The output is an audio stream in MP3 format which is written to the target S3 bucket.
Conclusion and Next Steps
In this post, you saw how to create a serverless solution that converts text to speech using Amazon Polly. The entire infrastructure life-cycle was automated using AWS CDK. All this was done using the Go programming language, which is well-supported in AWS Lambda and AWS CDK.
Here are a few things you can try out to improve/extend this solution:
- Ensure that the Lambda function is only provided fine-grained IAM permissions - for S3 and Polly.
- Try using different voices and/or output formats for the text-to-speech conversion.
- Try using different languages for text-to-speech conversion.
Happy building!
