Nested Transactions in CockroachDB 20.1

CockroachDB 20.1 introduces support for nested transactions, a SQL feature which simplifies the work of programmers of certain client applications. In this post, we'll explore when and where to use nested transactions, when not to use them, and how they work in a distributed environment.
What Are Nested Transactions?
A regular SQL transaction groups one or more statements together and provides them the A (Atomicity) and I (Isolation) of ACID. These are guarantees over the effects of the transaction from the perspective of concurrent clients running other transactions, or subsequent transactions by the same client. Atomicity means that all the statements inside the transaction appear to execute either successfully, or not at all. Isolation means that a concurrent transaction cannot see the intermediate steps inside the transaction and can only perceive the state of the database before the first statement starts, or after the last completes.
Nested transactions are additional transactions that occur within a regular transaction or other nested transactions, like Russian dolls. Nested transactions are invisible to concurrent clients, due to the atomicity and isolation of their surrounding, “outermost” transaction. Therefore, they are a feature that exists only for the benefit of the client issuing the outer transaction.
More specifically, nested transactions have been invented for the benefit of software engineers of client applications.
In component-based design, different programmers are responsible for the internals of different components and may not know about each other's work. If their components need to collectively operate over a database, they face an important challenge: how can each component safely contribute its portion of the database work, in the context of a multi-component transaction? If one component fails its work, it is usual to want another component to “take over” and complete the work in a different way, without giving up on the overall transaction. Nested transactions facilitate this, by providing atomicity (all succeed, or all fail) to the work of sub-components in the client app.
An example of this could be an hypothetical order system of your favorite assemble-your-own-furniture store. As the customer is walking the aisle and selecting their parts, their partial order starts a transaction that gets a lock on the supplies they need, incrementally. At some point, they may be reaching the kitchen area and start a design project using the provided interactive console. As they are experimenting, they wish to move forward with their new kitchen only if all the parts are available. What if the logic that allocates the parts encounters an insufficient supply and fails to instantiate the full kitchen on their order?
At that point, the customer may want to resume their shopping, without the kitchen order, but with all the other items they had in their shopping cart before: they want to roll back the kitchen sub-transaction, without giving up on the surrounding transaction. Nested transactions help achieve that.
Nested Transactions in Client Apps
Nested transactions are useful in component-based design of client apps. An app large enough to use component-based design rarely lets programmers use SQL directly and database access is typically abstracted in some framework (e.g. Spring, Flyway, or similar ORMs).
When database access is suitably abstracted, a nested transaction looks like a transaction “obtained from” another transaction, in contrast to regular transactions “obtained from” a database connection object.
For example:
# regular txn
myTxn := conn.BeginTxn()
myTxn.Execute("INSERT 1")
myTxn.Execute("INSERT 2")
myTxn.Commit()
# regular txn with nested sub-transaction
myTxn := conn.BeginTxn()
if component1.doSomething(myTxn) != success:
component2.doSomethingElse(myTxn)
myTxn.Commit()
# then in component1:
def doSomething(txn):
subTxn := txn.BeginTxn() # implicitly starts a nested txn
r := subTxn.Query("SELECT A")
if r != expected:
subTxn.Rollback() # aborts the nested txn
return failure
subTxn.Execute("INSERT B")
subTxn.Commit() # completes the nested txn
return success
This example provides a typical example of component-based design: the top-level component logic does not need to know what the sub-components component1 and component2 are doing with the transaction. It can assume that they leave the txn they're given in a good state. It can also assume that if component1.doSomething fails, it will leave myTxn “in the state it found it upon entry”. This separation of concern would not be possible if an error in component1 was trashing the outer transaction and forced the top level logic to restart the transaction from scratch.
How Client Drivers Implement Nested Transactions
Nested transactions look and feel like regular transactions in client code. However, this is only possible thanks to some translation magic by the client SQL driver. Under the hood, a SQL driver maps requests to begin, commit or roll back a nested transaction as follows:
Begin a nested transaction:
- auto-generate a name for the sub-transaction; for example subtxn123123
- send "SAVEPOINT subtxn123123" to the database. This tells the database to “start a nested txn and remember it is called 'subtxn123123'."
Commit a nested transaction:
- send "RELEASE SAVEPOINT subtxn123123" to the database. This tells the database to “commit the nested txn called subtxn123123."
Roll back (abort) a nested transaction:
- send "ROLLBACK TO SAVEPOINT subtxn123123" to the database. This tells the database to “rewind the nested txn called subtxn123123 to its beginning state."
- then send "RELEASE SAVEPOINT subtxn123123". This commits the nested txn; however, since it was just rewound by ROLLBACK, this cancels all its effects and thus aborts it.
The reason why ROLLBACK TO SAVEPOINT does not automatically imply RELEASE SAVEPOINT (i.e. RELEASE is necessary in any case) has to do with how certain client drivers abstract transactions in object-oriented languages. In particular, it is common for drivers to provide transaction objects that auto-commit when they are finalized. For example:
xxxxxxxxxx
with outerTxn.BeginTxn() as nested:
nested.Execute("SELECT")
if some condition:
nested.Rollback()
return
nested.Execute("INSERT")
In such a language, the destructor/finalizer of the transaction object (“nested” in this case) will issue RELEASE SAVEPOINT unconditionally. The Rollback() call issues just ROLLBACK TO SAVEPOINT. If ROLLBACK TO SAVEPOINT implied RELEASE, the RELEASE would be executed two times.
Nested Transactions In CockroachDB SQL
CockroachDB receives just SQL statements from client drivers; from its perspective, it has just three things to care about: the SAVEPOINT, ROLLBACK TO SAVEPOINT and RELEASE SAVEPOINT statements.
In this section, we ignore the special meaning that CockroachDB was giving these statements prior to v20.1 (this is covered later below) and instead consider how they work for nested transactions.
From the database's perspective, the statements mean the following:
- SAVEPOINT: mark the beginning of a nested sub-transaction.
- ROLLBACK TO SAVEPOINT: rewind a nested sub-transaction to its beginning state.
- RELEASE SAVEPOINT: “commit” (really: forget) a nested sub-transaction.
Each of these statements are given a savepoint name: the name given by the client app to the nested transaction. Because of component-based design, it's possible for a client component holding a nested transaction to give it as a starting point to a child component using its own nested transaction. The nested transactions can thus nest inside each other like Russian dolls. This means that the database can receive a SAVEPOINT statement “under” another and needs to remember the nesting of names. For example, the following is valid SQL:
xxxxxxxxxx
SAVEPOINT somename;
SAVEPOINT somename; -- same name, but this is really a sub-nested transaction
RELEASE SAVEPOINT somename; -- release inner
RELEASE SAVEPOINT somename; -- release outer
In other words, the database must remember and maintain a stack of nested transaction names. This is done in CockroachDB by allocating a unique internal token for each nested transaction, and then mapping client-provided names to the internal tokens using a stack data structure.
This data structure can be observed inside CockroachDB using the new statement SHOW SAVEPOINT STATUS inside a (nested) transaction.
The True Cost of Nested Transactions
If one were to attempt to design an implementation of nested transactions, it's likely one would come to several ideas in succession.
(For convenience, this section uses the shorthand "ROLLBACK" to refer to "ROLLBACK TO SAVEPOINT". This is different from SQL's plain "ROLLBACK" which we will only talk about later.)
A first idea could be to make the statements in the nested transaction operate on a memory copy (or temporary disk area) of the data, and delay performing actual data updates until the RELEASE statement. This way, a ROLLBACK merely has to delete the copy and the surrounding transaction can continue as if nothing happened. The problem with this approach is that in the common case (no ROLLBACK), the work has to be done twice: once on the copy, then one on the actual data during RELEASE. This is expensive.
A next idea could be to make the nested transaction update actual data in the same way the outer transaction would, but memorize all changes being made. In the common case of just a RELEASE, nothing else needs to happen. However, a ROLLBACK can then rewrite everything that has been modified so far. The limitation of this approach is that it also requires paying memory/disk space to memorize all the changes even in the common case where ROLLBACK is not issued.
The solution adopted in CockroachDB, like in most other mature SQL engines, is to minimize the cost in the common case and instead incur an incremental cost on the remainder of the transaction in the less likely case ROLLBACK is used.
Conceptually, this is done by:
- labeling every data update in a transaction with a marker that identifies the nested transaction.
- upon ROLLBACK, mark the corresponding nested transaction marker as "to be ignored"
- upon any read of the data, skip over any data updates with a (nested) transaction marker known to be ignored.
The expense in this approach is the extra work performed by data reads when there has been at least one ROLLBACK prior. ROLLBACKs add markers to an “ignore list” and cause it to grow, and the performance of each subsequent read operation is slightly slowed down by the increasing ignore list.
How It Works: Update Markers and The Ignore List
The reason why it is possible to “skip over ignored updates”, as stated above, is that CockroachDB uses an MVCC algorithm to access data. During data writes, the original data is not modified in-place. Instead, another data item is written next to it with the new value. This is called a write intent. During read operations, all write intents (and the original data record) are considered together to determine the current logical value.
The intent object contains metadata about the write, not just the updated value. It contains, for example, the ID of the transaction modifying the value, so that other transactions know to skip over it (so as to guarantee isolation).
Sometime before v20.1 (in v19.1, in fact), CockroachDB started numbering every write in a transaction, and writing that sequence number inside the intent objects.
This is the mechanism that was reused for nested transactions. The numbering itself wasn't changed; instead, read operations are now also provided a list of ranges of ignored sequence numbers (the “seqnum ignore list”). When a read considers a write intent, it now checks whether its sequence number is included in the ignore list. If it is, it is skipped over and does not count. This makes ignored intents invisible to reads, as if the write never occurred in the first place.
This makes nested transactions work as follows (approximately):
- The SAVEPOINT statement memorizes the current write sequence number.
- The ROLLBACK TO SAVEPOINT statement takes the current write sequence number (at the point ROLLBACK is issued), then the sequence number when SAVEPOINT was issued, then adds this range to the ignore list. (Overlapping ranges are combined together, as an optimization.)
- The RELEASE statement does... nothing.
At the end of the outermost transaction, all write intents are “resolved”:
- If the transaction is committed, the intents are transmuted into an actual data value so that subsequent transactions don't skip over them any more.
- If the translation is aborted, the intents are simply deleted.
The intent resolution algorithm also uses the new seqnum ignore list as input, and simply deletes all intents whose sequence number is included in the list—even when the outermost transaction commits.
To summarize:
- In the most common case where clients do not use nested transactions at all, the ignore list remains empty all the time and there is no additional performance price to pay.
- In the next most common case where clients use nested transactions but do not use ROLLBACK TO SAVEPOINT, the ignore list also remains empty all the time and there is no additional price to pay during read/write operations. The only price is the management of the stack of names of nested transactions.
- In the occasional case where ROLLBACK TO SAVEPOINT is used, the ignore list starts to grow; then every subsequent read by the same transaction, as well as intent resolution at the end, must perform some additional work to skip over all intents marked as ignored.
Error State Recovery
The explanation so far covers the case where ROLLBACK TO SAVEPOINT is used to cancel the effects of data writes in a transaction that's otherwise healthy (also called “open”).
Additionally, if ROLLBACK TO SAVEPOINT is used after a database error, it can also cancel the error state of the transaction.
This is best understood using a state diagram. With regards to errors, transactions generally operate as follows:
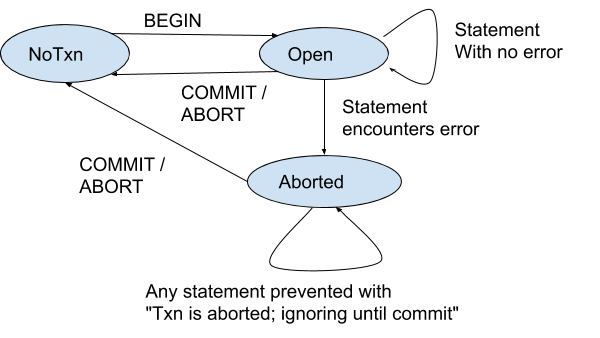
The idea here is that when a statement inside a transaction encounters an error, the transaction is marked internally as "Aborted". It still exists, but further statements cannot operate and encounter errors, until the transaction is canceled by the client using either COMMIT or ROLLBACK/ABORT. (In the Aborted state, COMMIT and ROLLBACK/ABORT are equivalent.)
This general principle remains valid for nested transactions. Inside a nested transaction, an error also moves the nested transaction into the Aborted state and prevents further SQL statements. However, ROLLBACK TO SAVEPOINT clears that aborted state. This can be represented as follows:
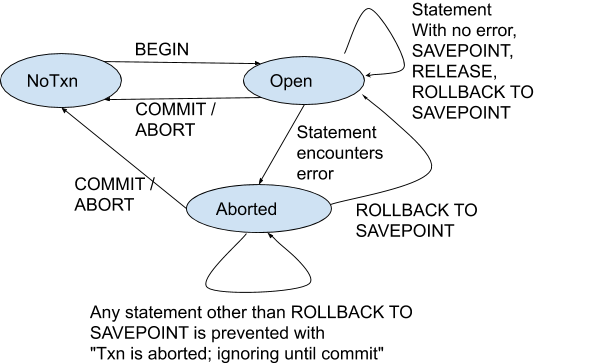
This implies that it is possible to use ROLLBACK TO SAVEPOINT to “recover” from a logical error, such as that reported by a foreign key constraint check (row does not exist in referenced table), a unique index (duplicate row), etc. It can also recover from mistakes in queries (e.g. column does not exist). The client code can use ROLLBACK TO SAVEPOINT to “paper over” the error and continue with a different statement instead.
(Reminder: the current error state of a transaction can be observed inside CockroachDB by issuing the statement SHOW TRANSACTION STATUS.)
Current Limitations
CockroachDB's support for nested transactions in v20.1 is limited in three noticeable ways, which can impact the design of new applications and compatibility with applications designed for PostgreSQL.
Locking Semantics
Like other SQL engines, CockroachDB places locks on updated rows during write operations, so that concurrent transactions cannot operate on them until the first transaction commits (or aborts). These locks are implicit in mutation statements like INSERT or UPDATE; or explicit in the newly introduced FOR UPDATE clause for SELECT statements.
As per the SQL standard, ROLLBACK TO SAVEPOINT should “rewind” all the effects performed by the nested transaction so far; this theoretically includes all the row locks. In other SQL engines, this is also what happens: when a nested transaction is rolled back, its row locks are released.
In CockroachDB v20.1, this is not what happens: as described in a previous section above, ROLLBACK TO SAVEPOINT preserves all the write intents written so far. Additionally, other concurrent transactions cannot see the “ignore list” of sequence numbers, and thus cannot perceive when an intent has been marked as ignored. Therefore, locks persist upon rewinding a nested transaction, unlike in other SQL engines and unlike in PostgreSQL.
To illustrate this, consider the example introduced at the beginning: that of a customer walking through their furniture store. Suppose that they had started an ambitious project to design a large kitchen with blue tiles. Then, upon placing their order, it turns out that there were not enough blue tiles in inventory to satisfy that order. If that store was running PostgreSQL, the customer canceling their nested kitchen transaction could continue shopping while the blue tiles would immediately become available to other customers in the kitchen area. With CockroachDB, the other customers must wait for the first customer to check out their entire shopping cart before they, in turn, can order blue tiles.
This current difference in behavior may thus impact the design of commerce-oriented client applications or any kind of OLTP system really. We acknowledge this; this divergence from the SQL standard may be lifted in a future version of CockroachDB.
Canceling Schema Changes
Another limitation is that ROLLBACK TO SAVEPOINT does not yet know how to rewind over DDL statements in certain cases.
For example, in other SQL engines, it is possible to rewind over e.g. CREATE TABLE or DROP INDEX using ROLLBACK TO SAVEPOINT and let the transaction proceed as if the DDL had not taken place at all.
In CockroachDB, attempting to rewind a nested transaction that has executed some DDL statement(s) will likely encounter the error "ROLLBACK TO SAVEPOINT not yet supported after DDL statements".
This limitation will likely be lifted in a subsequent version. Meanwhile, as in previous versions, CockroachDB v20.1 can cancel the effect of DDL using ABORT/ROLLBACK on the outer “regular” transaction.
The specific reason for this limitation is that CockroachDB caches metadata about tables accessed by statements inside a transaction. When rewinding a nested transaction, it would need to invalidate these caches but only for the subset of the tables altered inside the nested transaction. This additional complexity in the management of these caches is not yet implemented.
The particulars of this limitation also hint at when ROLLBACK TO SAVEPOINT actually can cancel DDL: if there was no query using a SQL table (any table!) prior to the nested transaction. This is not a particularly interesting case for client apps that need nested transactions due to component-based design, but happens to be common for CockroachDB clients for an unrelated reason; see the next sections.
Recovering from Serializability Conflicts, A.K.A. “Retry Errors”
Reminder: under various circumstances, a data read/write operation or transaction commit can encounter a conflict with a concurrent transaction. This occurs when the current transaction and the other transaction happen to operate on the same data and one of the two is writing. CockroachDB tries very hard to handle this conflict internally and hide it from the SQL client application. However, in some cases, an internal resolution is impossible and the conflict is reported to the client as a SQL error, with SQLSTATE 40001 and an error message containing a variant of the string "restart transaction". This general situation is common to all SQL engines implementing the SERIALIZABLE isolation level, including CockroachDB since v1.0 and PostgreSQL.
As of CockroachDB v20.1, ROLLBACK TO SAVEPOINT cannot cancel the error state that occurs from a serializability conflict except in a very particular scenario: when the nested transaction being rewound is a direct child of the outermost transaction, and its write set coincides exactly with it. In other words, it is only possible if the outer transaction did not write anything before the nested transaction was created; this includes hidden writes such as that performed when the transaction accesses a stored SQL table.
For example:
xxxxxxxxxx
BEGIN;
INSERT;
SAVEPOINT foo; -- nested transaction starts here
INSERT; -- encounters serializability failure
ROLLBACK TO SAVEPOINT foo;
-- rollback itself causes error 40001
-- "restart transaction: cannot rollback to savepoint"
The error is encountered because there was a write in the outer transaction (the first INSERT) before the nested transaction was created.
In contrast, the following works:
xxxxxxxxxx
BEGIN;
SAVEPOINT foo; -- nested transaction starts here
INSERT; -- encounters conflict and error 40001
ROLLBACK TO SAVEPOINT foo; -- ok
INSERT; -- something else
RELEASE SAVEPOINT foo;
COMMIT; -- end of txn
The following also works, and also illustrates the case where ROLLBACK TO SAVEPOINT can rewind over DDL:
xxxxxxxxxx
BEGIN;
SAVEPOINT foo;
CREATE TABLE t(x INT); -- CREATE in nested txn
INSERT INTO t(x) VALUES( 1);
INSERT INTO other ... ; -- encounters conflict and error 40001
ROLLBACK TO SAVEPOINT foo; -- ok, also cancels the CREATE TABLE
CREATE TABLE t(x INT); -- client retries the CREATE in nested txn
INSERT INTO t(x) VALUES( 2);
RELEASE SAVEPOINT foo; -- end of nested txn
COMMIT; -- end of txn
What this means for programmers of client apps is that they must continue to handle retry errors, and they can only do so in the top level transaction—the one held by the coordinating component for the database transaction. It is not (yet) possible to handle retry errors at the level of individual components in a multi-component app using nested transactions.
A Special Case: The Restart Protocol
As another artifact of SERIALIZABLE isolation shared with PostgreSQL, CockroachDB can encounter a serializability conflict while committing a transaction.
If the transaction is committed as a side effect of the client issuing a COMMIT statement, there is little the client can do to recover from the error: by that time, all the data structures and other state in the client code used during the transaction is (usually) already destroyed. (Remember that COMMIT is often issued in the destructor of transaction objects in client frameworks, as part of an RAII protocol.) The recommended way forward is thus to propagate the error in the application to a level in the source code able to restart the SQL transaction from scratch.
Due to peculiarities in the design of CockroachDB v1.0, it was not desirable then to let clients restart from scratch upon serializability conflicts. Instead, CockroachDB v1.0 would perform better if the client reused the original SQL transaction somehow after a serializability conflict. To achieve this, CockroachDB has historically provided its own bespoke restart protocol, triggered by a “magic word”: the special statement "SAVEPOINT cockroach_restart" (note the specific name "cockroach_restart").
That magic word, since v1.0 and up to and including v20.1, is wholly unrelated to nested transactions as discussed so far. It happens to use a common SQL keyword ("SAVEPOINT") but triggers quite unrelated logic and behavior inside CockroachDB. Therefore, it is useful to think of it as a separate feature.
When the magic word is encountered, CockroachDB upgrades the transaction to a different mode, where subsequent statements are interpreted differently. In that alternate mode, the words "RELEASE SAVEPOINT cockroach_restart" become equivalent to the COMMIT statement in the simple/normal mode. Then, the COMMIT statement becomes (more-or-less) a no-op.
In other words, in the alternate transaction mode started with "SAVEPOINT cockroach_restart", the transaction commits when "RELEASE SAVEPOINT cockroach_restart" is sent by the client. After that statement, the transaction is already committed even before the SQL COMMIT statement is issued. Because it is committed, no other statements are allowed. This can be represented by the following state diagram:
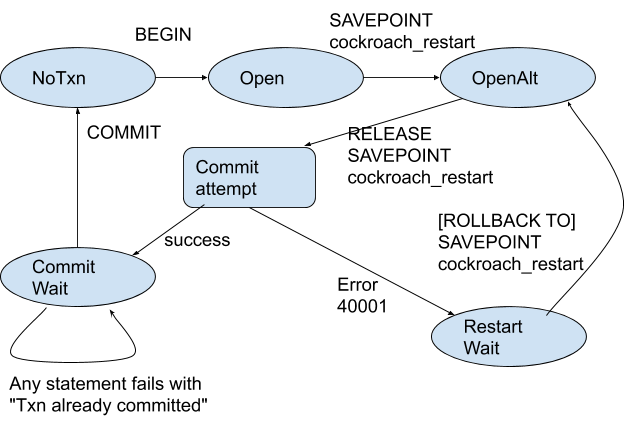
The alternate mode can only be enabled immediately after the BEGIN statement. The magic word is rejected with an error if it is encountered later.
For backward compatibility with previous CockroachDB versions, v20.1 preserves this feature and the associated complexity, even though the motivation for it does not exist any more. Indeed, since v1.0, it has become less important to reuse the same SQL transaction to effectively recover from serializability errors at commit time. In fact, since v19.1 we do not actively recommend clients to implement the special restart protocol any more. One reason is that CockroachDB has become better at handling serializability conflicts internally without participation from the client app (i.e. the retry errors with code 40001 have become rarer). Additionally, CockroachDB has become better at letting clients recover from a serializability error by retrying the transaction from scratch, as in other SQL engines.
The preservation of this special restart protocol in v20.1 was thus done mainly out of care for backward compatibility. The restart protocol may be phased out in a later version.
Beware: Don't (Over) Use Nested Transactions
Even though nested transactions are part of the SQL standard, PostgreSQL supports them and many of our users have demanded their inclusion in CockroachDB, we do not recommend their use in new applications.
The reality is that nested transactions are a product of the early days of software engineering, in the 1990s, back when systems were tightly coupled and the Internet and the Cloud were not yet very relevant. They only make sense in the context of apps a) whose design is component-based but tightly coupled and b) whose architecture has promoted database transactions spanning multiple components. Only this combination makes it possible to pass an outer transaction from one component to the next to build nested transactions upon, and thus implicitly design one component with hidden, implicit knowledge of global state held by another component via its transaction handle.
Nowadays, such tight coupling has a bad rep. This is because two additional decades of software engineering have taught us that implicit global state really, really does not play well with distributed services where some components may fail even as part of normal load. It makes it hard to fail over a component gracefully by transferring its responsibility to a hot spare. It makes it hard to reason about the current state of a component and troubleshoot it by just looking at the log of its inputs and outputs.
Additionally, nested transactions can amplify performance anomalies. The row locks established by a large transaction whose latency extends across multiple components/services are more likely to incur transaction conflicts which, at best, increase the average latency of queries and, at worse, increase the error rate quadratically with the current query load.
Finally, nested transactions can run afoul of correctness in distributed apps. In fact, the idea of multi-component transactions in client code really evokes the idea of a bull in a china shop. As long as all is well and the transaction is due to commit, the idea somewhat makes sense. However, what happens when the database (and not the client) decides the transaction is un-committable and must be aborted, for example because of a serializability conflict or a node restarting for maintenance? It is not just the database state that must be rolled back; all the possible side effects performed by the components holding the transaction must also be rolled back. Think about payment transactions. Think about email notifications. For one, the programmer is unlikely to think about this properly before the app is deployed. Also, as the number of components involved grows, the chance they are collectively performing unabortable external side effects (logging, payments, notification emails or SMS, REST queries to external HTTP APIs, etc) increases dramatically.
So, in truth, CockroachDB supports nested transactions to ease adoption by users who are already pulling a weight of legacy software. We want to help them, too, bring their legacy code to the Cloud era and offer them the reliability and scalability of CockroachDB. But we do not wish more of their problems to appear elsewhere.
If you have a choice in the matter, keep your database transactions as small as possible. Do not let them span multiple components. Do not interleave database transactions with application-level side effects or external calls to APIs. Favor append-only event logs where it makes sense. Partition the data to ensure that each locale of data access is isolated from other locales and cannot cause transaction conflicts. Reduce the scope of transactions to minimize the number of rows they ever access and may lock.
In that world of best practices, there is little need for nested transactions, and that is a good thing.
Summary
CockroachDB v20.1 has introduced support for SQL nested transactions. Nested transactions are a legacy feature of certain SQL engines that facilitates component-based design in certain client applications. Although we do not encourage the use of nested transactions, because the concept is antithetical to good cloud application design, we provide the feature for compatibility with existing PostgreSQL client apps and ease adoption of CockroachDB by legacy code.
Support for nested transactions is provided in a way compatible with PostgreSQL's dialect, using the SAVEPOINT, RELEASE SAVEPOINT and ROLLBACK TO SAVEPOINT statements.
When learning, understanding and using this feature, the user should be careful to distinguish nested transactions, a standard SQL feature newly supported in v20.1, from CockroachDB's bespoke transaction restart protocol triggered by the magic SQL phrase "SAVEPOINT cockroach_restart", introduced back in CockroachDB v1.0. This magic phrase happens to use a common keyword ("SAVEPOINT") but triggers a behavior and mechanisms quite unrelated to nested transactions. It is thus essential to distinguish the two features using the terms “nested transactions” and “restart protocol” and avoid the word “savepoint” which has become ambiguous.
At the time of this writing, there are some limitations in CockroachDB's support for nested transactions. In particular, a nested transaction cannot be rolled back if it contains DDL statements (schema changes) or if it encounters a serializability conflict which CockroachDB cannot handle internally, unless the nested transaction was created immediately after the outer transaction. Rolling back a nested transaction also does not release row locks, unlike in other SQL engines, but these limitations may be lifted in a later version.
