Introduction to Spring Data Elasticsearch 4.1

Preface
I was recently playing around with Spring Data Elasticsearch (the Spring Data project for Elasticsearch) and came across several issues. One of these was a lack of up-to-date articles. This led me to share my experience using the latest Elasticsearch 7 and Spring Data Elasticsearch 4.1. I hope that my advice can help others gain insight into the tool and how to effectively use it for a variety of reasons.
In this Article, You Will Learn
- What Elasticsearch and Spring Data Elasticsearch are.
- Basic Elasticsearch cluster setup via Docker (including management and monitoring tool).
- How to configure Spring Data Elasticsearch in a project.
- How to use Spring Data Elasticsearch to upload and access Elasticsearch data.
- What are some pitfalls related to Elasticsearch usage?
First, I will briefly explain the purpose of Elasticsearch.
Elasticsearch
Elasticsearch is the heart of the Elastic stack known as ELK. The ELK stands for Elasticsearch (a distributed search and analytics engine for all kinds of data), Logstash (a server-side data processing pipeline for collecting, transforming, and sending data to the Elasticsearch), and Kibana (a visualization of Elasticsearch data and navigation in the Elastic Stack ).
For the purposes of this article, we will only discuss Elasticsearch as this is what we use here as a NoSQL database. Therefore, no other tool from the ELK umbrella is needed.
Let’s start with how to set up Elasticsearch from scratch.
Docker Setup
There are many ways to install and configure Elasticsearch. One of the easiest, convenient and available options is to use Docker image.
Custom Network
As we use several Docker images (two in our case), we need to create a Docker network to be shared between the images first. Such a network is necessary for connecting different services together, e.g., Kibana or monitoring tools (as we’re doing here). We call the network sat-elk-net and it is created as:
xxxxxxxxxx
docker network create sat-elk-net
Elasticsearch
There are plenty of Docker images available on Elasticsearch, but we can also use custom ones. Here, we use a Docker image from Docker HUB available at https://hub.docker.com/_/elasticsearch. This image provides a single node of Elasticsearch in the development mode (Elasticsearch cluster). We can create our Docker container based on that image with this command:
xxxxxxxxxx
docker run -d --name sat-elasticsearch --net sat-elk-net -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:7.9.3
Command Arguments
- We name our Docker container with
sat-elasticsearchname (specified by the--nameargument). - We want to connect our Elasticsearch cluster to
sat-elk-netnetwork as created before (specified by the--netargument). - Also, we need to expose ports 9200 and 9300 (specified by the
--pargument). You can find the difference between these ports (what's their purpose) on https://discuss.elastic.co/t/what-are-ports-9200-and-9300-used-for/238578.
Note: we use the 7.9.3 version for Docker image here due to the compatibility with Spring Data Elasticsearch 4.1. The Docker hub already contains a newer version.
Verification of a Running Cluster
To verify the running Elasticsearch cluster (just a single node in our case as already mentioned) we can easily call http://localhost:9200 (e.g., with CURL tool) as:
x
curl http://localhost:9200
We should get a JSON response that should look like this:
x
{
"name" : "79567a47ed4b",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "7BycQOMRTPC9yI2o9LvDOg",
"version" : {
"number" : "7.9.3",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "c4138e51121ef06a6404866cddc601906fe5c868",
"build_date" : "2020-10-16T10:36:16.141335Z",
"build_snapshot" : false,
"lucene_version" : "8.6.2",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
ElasticHQ
We can optionally add a monitoring tool for our Elasticsearch cluster. We can use the ElasticHQ tool for that. ElasticHQ is also available as a Docker image at https://hub.docker.com/r/elastichq/elasticsearch-hq. The ElasticHQ can be easily created with this command (similar to the previous one for Elasticsearch):
xxxxxxxxxx
docker run -d --name sat-elastichq --net sat-elk-net -p 5000:5000 elastichq/elasticsearch-hq
Note: as you can see we also need to export port 5000 (or choose any other available) to be able to access ElasticHQ outside the Docker container.
The running ElasticHQ can be verified by calling http://localhost:5000 in your favorite browser. There, we need to specify our Elasticsearch instance first (or keep the prefilled value for the cluster on localhost).
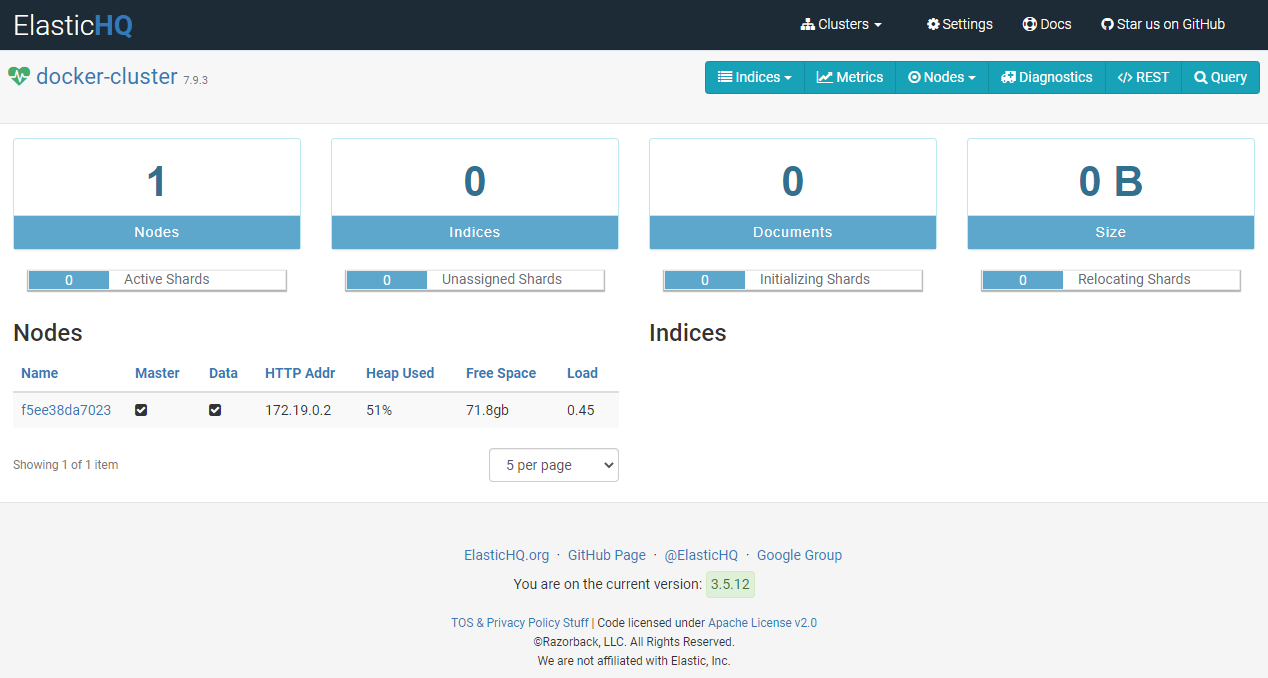
Once we specify the URL for our Elasticsearch cluster then we are forwarded to the ElasticHQ home page. There, we can see the details of our Elasticsearch cluster (e.g., number of nodes), available indices, metrics (e.g., number of stored documents), etc. It’s still empty for now as we don't have any data in the Elasticsearch cluster yet.
Spring Data Elasticsearch
To understand the purpose of Spring Data Elasticsearch, we can look at the definition on the official project site:
The Spring Data Elasticsearch project applies core Spring concepts to the development of solutions using the Elasticsearch Search Engine. It provides:
Templates as a high-level abstraction for storing, searching, sorting documents and building aggregations.
Repositories which for example enable the user to express queries by defining interfaces having customized method names.
Configuration
To get started with Spring Data Elasticsearch we need, other than the running Elasticsearch cluster (e.g., as described before), to add the maven dependency and define some configurations.
Maven Dependencies
First, we need to add the spring-boot-starter-data-elasticsearch dependency into our Maven project (pom.xml) as shown below. We can find the latest available 4.1.x version in the Maven Central repository.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
<version>2.4.6</version>
</dependency>Additionally, our code depends on the Spring MVC (for exposing REST endpoints) and the jackson.dataformat CSV module (for reading CSV files). We should add them into our project as:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>2.4.6</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.dataformat</groupId>
<artifactId>jackson-dataformat-csv</artifactId>
<version>2.11.4</version>
</dependency>Note: Our project relies on Spring Boot dependencies so we don't need to care about the latest version (unless you have a specific reason to use it).
Spring Data Elasticsearch
Additionally, we might want to configure some basic settings of our Elasticsearch (e.g. URL to our running cluster). Well, the truth is that the URL is optional as well since http://localhost:9200 is the default value. You can define the settings in the YAML file (or adequately via properties) as:
x
spring
elasticsearch
rest
urishttp//localhost9200
Note: we can also use JavaConfig (as available in many examples), but it's really not necessary in such a simple case.
When we have Elasticsearch ready and configured in our project, we can move to the mapping of our documents (to be stored in Elasticsearch).
Basic Setup
To demonstrate Spring Data Elasticsearch usage we use open data with the major cities (see https://datahub.io/core/world-cities) in the world. For that purpose, we need to define the class City (a document — an equivalent of JPA entity for Elasticsearch). Please check here (or for Elasticsearch itself, here) to get more information about complete mapping details and its usage.
To demonstrate Spring Data Elasticsearch usage we use open data from major cities across the world. For that purpose, we need to define the class City (representing a document -> an equivalent of JPA entity for Elasticsearch). Please check the Spring Data reference documentation (or the Elasticsearch reference documentation) for more information about complete mapping details and their usage.
Document Mapping
All Spring Data projects are based on a mapping of data into some POJO class in order to provide support for the persistence and data access in the desired technology (here, the Elasticsearch). In our case, we need to create a simple City class with all CSV values. Apart from that, we need to add some annotations to the class in order to define necessary metadata (mainly for Elasticsearch purposes). The City class representing the Elasticsearch document looks like this:
xxxxxxxxxx
(indexName = City.INDEX)
public class City implements Serializable {
private static final long serialVersionUID = 1L;
public static final String INDEX = "city";
private String id;
("name")
(type = FieldType.Text, fielddata = true)
private String name;
("country")
private String country;
("subcountry")
private String subcountry;
("geonameid")
private Long geonameid;
}
The document mapping comments:
Document— the class marker as the Elasticsearch document. It contains an index name to define storage in the Elasticsearch cluster.Id— used to specify the primary key of the document (usually it should beStringfor NoSQL solution).Field— used to specify custom mapping (e.g. data type, data format, for sorting, etc.) when needed. As you can see there's no need to define that by default. We demonstrate that only on thenameattribute.JsonProperty— this annotation is not relevant for Elasticsearch mapping. It's used by thejackson-dataformat-csvlibrary to simplify and support operations with CSV files (to be used later).
Note: the text above presents only the basics and we can do a lot more (e.g. to map the nested class). I mention some other options towards the end of the article. However, the rest exceeds the scope of this tutorial.
Repository
To finish the configuration part, we need to create our repository as an interface. This component (the implementation is generated by Spring Data Elasticsearch) serves as the adapter to the Elasticsearch cluster to access and store data. For that purpose, we define CityRepository class as:
x
public interface CityRepository extends ElasticsearchRepository<City, String> {
Page<City> findByCountry(String country, Pageable pageable);
}
Comments:
- The class extends
ElasticsearchRepositoryin order to inherit all common CRUD methods (e.g., fromCrudRepository). We need to specify the used document type (Cityin our case) and a primary key type (Stringas already mentioned). - This repository class can be empty (without any method) and we would still be able to use it for accessing and storing data (as already mentioned). However, we add the
findByCountrymethod to demonstrate how easy it is to define a specific search method. As you can expect, we use this method later to look for all cities in a given country.
Elasticsearch Usage
Now when we have everything configured and ready, we can add some REST endpoints to manage our data stored in Elasticsearch. We start our journey by adding some data with an upload feature.
Upload data
As we still have an empty Elasticsearch cluster, we need to insert some data in it. We use open data with major cities for the purposes of this tutorial. We use the world-cities.csv file (available here) containing approx. 23k cities (at least at the point of download for me). This CSV file has a very simple structure, defined as:
xxxxxxxxxx
name,country,subcountry,geonameid
les Escaldes,Andorra,Escaldes-Engordany,3040051
Andorra la Vella,Andorra,Andorra la Vella,3041563
...
The key part of our upload feature is implemented in the service layer where we need to parse CSV and store the parsed data (lines from CSV) in chunks into the Elasticsearch cluster. We use the saveAll method (instead of save) in our CityRepository in order to store all items in the chunk at once. The size of the chunk is defined with a value of 500 (BULK_SIZE). The upload is triggered by the uploadFilemethod.
@Service
public class CityService {
private static final int BULK_SIZE = 500;
@Autowired
final CityRepository repository;
final CsvMapper csvMapper = new CsvMapper();
final CsvSchema schema = csvMapper
.typedSchemaFor(City.class)
.withHeader()
.withColumnReordering(true);
public void uploadFile(String csvFileName) {
log.info("loading file {} ...", csvFileName);
List<City> csvData = parseFile(csvFileName);
log.info("{} entries loaded from CSV file", csvData.size());
storeData(csvData);
log.info("data loading finish");
}
private List<City> parseFile(String csvFileName) {
try {
return csvMapper
.readerFor(City.class)
.with(schema)
.<City>readValues(new File(csvFileName))
.readAll();
} catch (IOException e) {
throw new ElkException(e);
}
}
private void storeData(List<City> cities) {
final var counter = new AtomicInteger();
final Collection<List<City>> chunks = cities.stream()
.collect(Collectors.groupingBy(it -> counter.getAndIncrement() / BULK_SIZE))
.values();
counter.set(0);
chunks.forEach(ch -> {
repository.saveAll(ch);
log.info("bulk of cities stored [{}/{}] ...", counter.getAndIncrement(), chunks.size());
});
}
}Next, we need to add an endpoint to expose the upload feature by adding the CityController class with the uploadFile method. See below:
xxxxxxxxxx
(value = CityController.ROOT_CONTEXT, produces = APPLICATION_JSON_VALUE)
public class CityController {
public static final String ROOT_CONTEXT = "/api/cities";
final CityService service;
("/upload")
(code = NO_CONTENT)
public void uploadFile(String filename) {
service.uploadFile(filename);
}
}
Note: this part (the implementation of controllers and services) is quite straightforward and out of the scope of this article. Therefore, the explanation is skipped.
We can verify our first REST endpoint here by uploading a CSV file via the POST (HTTP) method on /api/cities/upload path. The complete URL looks like http://localhost:8080/api/cities/upload?filename=Z:/world-cities.csv. We can see the processing of the uploaded data by checking log entries. The application logs should look like this:
2021-03-25 09:21:14.374 INFO 6936 --- [nio-8080-exec-1] com.github.aha.sat.elk.city.CityService : loading file Z:/world-cities.csv ...
2021-03-25 09:21:14.439 INFO 6936 --- [nio-8080-exec-1] com.github.aha.sat.elk.city.CityService : 23018 entries loaded from CSV file
2021-03-25 09:21:15.593 INFO 6936 --- [nio-8080-exec-1] com.github.aha.sat.elk.city.CityService : bulk of cities stored [0/47] ...
...
2021-03-25 09:21:21.564 INFO 6936 --- [nio-8080-exec-1] com.github.aha.sat.elk.city.CityService : bulk of cities stored [46/47] ...
2021-03-25 09:21:21.564 INFO 6936 --- [nio-8080-exec-1] com.github.aha.sat.elk.city.CityService : data loading finishWe can also check the ElasticHQ home page to see the changes in our Elasticsearch cluster. As we can see, one new index was added, containing 23k documents.
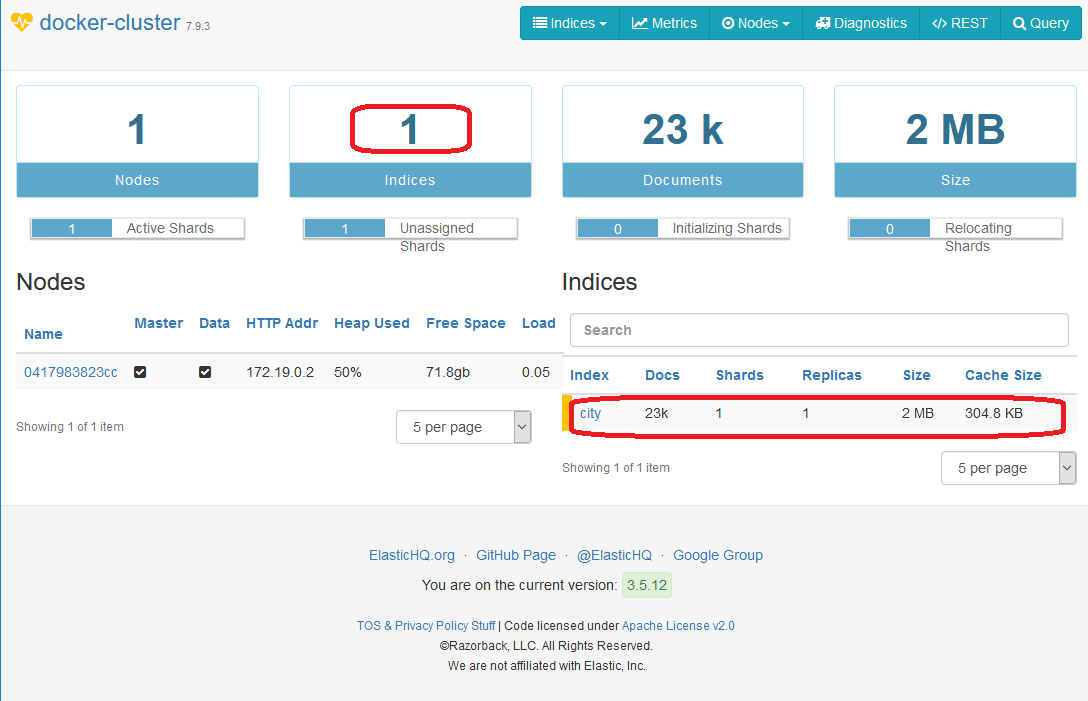
In the next section, we move to the features related to accessing the data in our Elasticsearch cluster that we have stored at this point.
Retrieve Data
Reading data from an Elasticsearch cluster with Spring Data Elasticsearch is very easy, convenient, and straightforward. The usage is very similar to the usage of Spring Data for any other technology (e.g., JPA, Redis, etc.).
Get One City
We don't need to implement anything on the repository level in order to retrieve a single document requested by its ID. The Spring Data provides thefindById method for us in their CrudRepository class (the ancestor for ElasticsearchRepository class) to provide such a feature. However, the findById method returns Optional<City>. Therefore we need to decide how to handle this situation. We can either throw an exception (as in our case) when the city instance is not found by the given ID, returning null, or provide custom logic to handle it.
Our CityService class is straightforward and offers getOne method as:
xxxxxxxxxx
public City getOne(String cityId) {
return repository.findById(cityId)
.orElseThrow(() -> new ElkException("City with ID=" + cityId + " was not found!"));
}
Also, we want to expose the feature via the REST service. We can do that by adding the getOne method in CityController on http://localhost:8080/api/cities/{id} URL. The desired document ID is passed as {id} in the path. The CityController class looks like this:
x
("/{id}")
public City getOne( String id) {
return service.getOne(id);
}
To test our new feature we can call, e.g., http://localhost:8080/api/cities/AxUw83gB-cKzXLTF9fya (the ID was picked up from our data) with this result:
{
"id": "AxUw83gB-cKzXLTF9fya",
"name": "Prague",
"country": "Czech Republic",
"subcountry": "Praha",
"geonameid": 3067696
}
Find Cities by Static Query
When we want to search cities, the simplest approach is to use a "static" query.
The static query means the defined method in our repository interface. Therefore the search is driven and using all the passed arguments (we cannot change them dynamically). It's very efficient as we don't need to write a single line (we only need to define that method correctly). The Spring Data translates the method name into a query implementation automatically for us. More information is available on naming convention page.
In our case, we want to search for all available cities in a country. In order to do that we just need to define the findByCountry method in CityRepository class as:
xxxxxxxxxx
Page<City> findByCountry(String country, Pageable pageable);
The rest of the search (service and controller) is straightforward. We extend our CityService class with searchByCountry method as:
x
public Page<City> searchByCountry(String country, Pageable pageable) {
return repository.findByCountry(country, pageable);
}
And add searchByCountry method in CityController class as:
x
("/country/{country}")
public Page<City> searchByCountry(("country") String country, Pageable pageable) {
return service.searchByCountry(country, pageable);
}
The implemented search feature (to find all cities, e.g., from the Czech Republic) can be verified on http://localhost:8080/api/cities/country/czech republic?sort=name,desc with this output:
{
"content": [
{
"id": "5xUw83gB-cKzXLTF9fua",
"name": "Žďár nad Sázavou Druhy",
"country": "Czech Republic",
"subcountry": "Vysočina",
"geonameid": 3061692
},
...,
{
"id": "8BUw83gB-cKzXLTF9fua",
"name": "Uherský Brod",
"country": "Czech Republic",
"subcountry": "Zlín",
"geonameid": 3063736
}
],
"pageable": {
"sort": {
"sorted": true,
"unsorted": false,
"empty": false
},
"offset": 0,
"pageNumber": 0,
"pageSize": 20,
"paged": true,
"unpaged": false
},
"aggregations": null,
"scrollId": null,
"maxScore": "NaN",
"totalPages": 5,
"totalElements": 100,
"size": 20,
"number": 0,
"sort": {
"sorted": true,
"unsorted": false,
"empty": false
},
"first": true,
"last": false,
"numberOfElements": 20,
"empty": false
}Note: As you can see we are using the pagination here without any particular effort. We just need to define a Pageable argument and Page response type in our repository class. As you can see, the page element content in the output is quite verbose, as it provides a lot of information related to the Elasticsearch cluster.
Find Cities by Dynamic Query
The static query is not sufficient in all cases. Sometimes we require a different combination of arguments or we need to ignore some argument when it contains a null value. The "dynamic" query term is used when we need to adjust our query according to passed argument values (e.g., name or country attribute in our case).
For that, we don't need to modify the code of CityRepository class at all, but just the CityService class as all logic is happening in a service layer. All we need to do is to create a Query instance. We simply pass that instance to the search method in the CityRepository class (provided by the ElasticsearchRepository class).
The buildSearchQuery method (see below) evaluates all passed arguments (e.g. lines 10-12 for the name argument) and adds the relevant expression to the criteria query. Here we can use expressions like is, contains, and, not, expression, etc. All these methods for creating the query are quite straightforward. More detail on constructing them can be found in the reference documentation.
x
public Page<City> searchDeprecated(String name, String country, String subcountry, Pageable pageable) {
CriteriaQuery query = buildSearchQuery(name, country, subcountry);
query.setPageable(pageable);
return repository.search(query);
}
private CriteriaQuery buildSearchQuery(String name, String country, String subcountry) {
Criteria criteria = new Criteria();
if (nonNull(name)) {
criteria.and(new Criteria("name").contains(name));
}
if (nonNull(country)) {
criteria.and(new Criteria("country").expression(country));
}
if (nonNull(subcountry)) {
criteria.and(new Criteria("subcountry").is(subcountry));
}
return new CriteriaQuery(criteria);
}
Note: Of course, we can move the buildSearchQuery logic into CityRepository class. It's just my personal preference for where to place such code.
Exposing REST service for that (in the CityController class) is almost the same as for the static query. You can find such code in the deprecatedSearch method available below.
xxxxxxxxxx
("/deprecated")
public Page<City> deprecatedSearch(("name") String name, ("country") String country,
("subcountry") String subcountry, Pageable pageable) {
return service.searchDeprecated(name, country, subcountry, pageable);
}
We can verify our dynamic query in the very same ways on http://localhost:8080/api/cities/deprecated/?name=be&country=Czech&subcountry=bohemia&size=5&sort=name with this output:
x
{
"content": [
{
"id": "RhUw83gB-cKzXLTF9fya",
"name": "Benešov",
"country": "Czech Republic",
"subcountry": "Central Bohemia",
"geonameid": 3079508
},
],
"pageable": {
}
}
Note: the URL path (and Java methods related to this feature) uses the word deprecated because the search method is marked as deprecated in the ElasticsearchRepository class. There's no other meaning behind that. More information regarding that can be found later in this article.
Final Notes
We now know how to configure and use the Elasticsearch cluster via Spring Data Elasticsearch. However, we have just scratched the surface. There are many things you should do more when using the tool in production rather than just a development environment. Here are a few brief examples.
Docker Image
In the beginning, we created an Elasticsearch cluster from the image with just a single node. In PROD, we want a cluster to support scalability, performance, and data loss protection. For that, we should use different configurations or even Docker images.
Configuration
The code above relies on the configuration in the properties file. That solution might not be enough for several cases (e.g., PROD deployment as we taught that before). To solve that issue, we can use the JavaConfig option to cover those cases. Please check chapter 3.1 in https://www.baeldung.com/spring-data-elasticsearch-tutorial to see tips on how to do that.
Searching
There are several issues related to searching data in an Elasticsearch cluster. Most of them are related to pagination and big result sets, search possibilities, and sorting.
Pagination
The search method in the ElasticsearchRepository interface is marked as deprecated in Spring Data Elasticsearch 4.1 since version 4.0, as was already mentioned. The JavaDoc proposes to use the searchQuery method, but unfortunately, such a method is not available. The Spring Data Elasticsearch 4.2 (released recently) removed that method completely. Besides that, Elasticsearch has a limit for the set size of the results (10,000 in our Docker image).
We can overcome both of these issues with the usage of ElasticsearchOperations bean which behaves in a very similar way to, for example, RestTemplate. The main advantage of this approach is the support for SearchHit API (for providing entity-specific additional information — e.g., scoring) or Scroll for a big result set. We can use several query types (e.g. CriteriaQuery, NativeSearchQuery) for that purpose. However, I won’t go into much detail here, as this is an independent topic to be covered in an upcoming article.
Search Possibilities
The contains method in the Criteria query (as we already used) doesn't support spaces as an input for the attributes defined by String type. Once we try to use a space in the value for a document field searched by contains method then we would get an error like this:
xxxxxxxxxx
org.springframework.dao.InvalidDataAccessApiUsageException: \
Cannot constructQuery '*"Czech republic"*'. Use expression or multiple clauses instead.
at org.springframework.data.elasticsearch.core.query.Criteria.assertNoBlankInWildcardQuery(Criteria.java:793) ~[spring-data-elasticsearch-4.1.8.jar:4.1.8]
at org.springframework.data.elasticsearch.core.query.Criteria.contains(Criteria.java:417) ~[spring-data-elasticsearch-4.1.8.jar:4.1.8]
at com.github.aha.sat.elk.city.CityService.buildSearchQuery(CityService.java:112) ~[classes/:na]
at com.github.aha.sat.elk.city.CityService.searchDeprecated(CityService.java:100) ~[classes/:na]
...
at java.base/java.lang.Thread.run(Thread.java:832) ~[na:na]
We can solve this by replacing the contains method with the expression method. You can find more information on how to do it here: StackOverflow site.
Document Mapping For Sorting
Document mapping is easy and straightforward, as you can see in this article. Nevertheless, it's limited by Elasticsearch constraints. One of them is that we can search any text attribute, but we cannot do any advanced operation (e.g., aggregation or sorting) on them, see here for more details.
When we need to sort by some attribute (e.g., the name attribute in our case) then we need to mark that attribute with @Field annotation and fielddata=true. Note: it's perfectly fine to search by that attribute without such a definition.
If we tried to sort data by an attribute not defined as field data, then we would receive an error like this:
xxxxxxxxxx
org.elasticsearch.ElasticsearchException: Elasticsearch exception [type=illegal_argument_exception, reason=Text fields are not optimised for operations that require per-document field data like aggregations and sorting, so these operations are disabled by default. Please use a keyword field instead. Alternatively, set fielddata=true on [name] in order to load field data by uninverting the inverted index. Note that this can use significant memory.]
at org.elasticsearch.ElasticsearchException.innerFromXContent(ElasticsearchException.java:496) ~[elasticsearch-7.9.3.jar:7.9.3]
at org.elasticsearch.ElasticsearchException.fromXContent(ElasticsearchException.java:407) ~[elasticsearch-7.9.3.jar:7.9.3]
at org.elasticsearch.ElasticsearchException.innerFromXContent(ElasticsearchException.java:437) ~[elasticsearch-7.9.3.jar:7.9.3]
at org.elasticsearch.ElasticsearchException.fromXContent(ElasticsearchException.java:407) ~[elasticsearch-7.9.3.jar:7.9.3]
...
Repository Ancestors
Spring Data offers several possibilities to extend our repository class. It's very easy and useful (as demonstrated in several examples), but we need to be very careful with it. When our Elasticsearch repository class extends QueryByExampleExecutor, then our application would fail to start with the "No property exists found for type City!" error message. The error message looks like this:
xxxxxxxxxx
Caused by: org.springframework.data.mapping.PropertyReferenceException: No property exists found for type City!
at org.springframework.data.mapping.PropertyPath.<init>(PropertyPath.java:90) ~[spring-data-commons-2.4.8.jar:2.4.8]
at org.springframework.data.mapping.PropertyPath.create(PropertyPath.java:437) ~[spring-data-commons-2.4.8.jar:2.4.8]
at org.springframework.data.mapping.PropertyPath.create(PropertyPath.java:413) ~[spring-data-commons-2.4.8.jar:2.4.8]
at org.springframework.data.mapping.PropertyPath.lambda$from$0(PropertyPath.java:366) ~[spring-data-commons-2.4.8.jar:2.4.8]
at java.base/java.util.concurrent.ConcurrentMap.computeIfAbsent(ConcurrentMap.java:330) ~[na:na]
...
Note: That inheritance for querying by example works perfectly fine for Redis. But Elasticsearch doesn't support it.
Elasticsearch Client
Spring Data Elasticsearch provides support for TransportClient (the old one) and RestClient (since version 3.2.0). You can find more details about the difference here in this StackOverflow question.
Conclusion
This article has covered the basics of Spring Cloud Elasticsearch usage. We began with the preparation of an Elasticsearch cluster (in the development mode) and definitions of all Spring Data artifacts. Next, we implemented REST endpoints for uploading and searching city data in our Elasticsearch cluster. In the end, several open points and pitfalls were mentioned and briefly explained. The complete source code demonstrated above is available in my GitHub repository.
In the next article, I will cover more search options using Spring Cloud Elasticsearch.
