Running and Optimizing Sidekiq Workloads With Dragonfly

Scaling Sidekiq is challenging when paired with Redis. The hurdle arises from the complexity of Redis' horizontal scaling model:
- Redis is mostly single-threaded, unable to fully utilize modern multi-core servers.
- On the other hand, it is discouraged to use Redis Cluster for Sidekiq, as detailed here.
This dilemma often leads to throughput bottlenecks when using Sidekiq with Redis. We have optimized Dragonfly, a modern multi-threaded drop-in replacement for Redis that can be used as a backend data store for Sidekiq, to address these scaling challenges. Without further ado, let's dig into how we did this.
Sidekiq Overview
Sidekiq is an efficient background job processing system for Ruby. Application users submit work (jobs), which Sidekiq executes asynchronously. Sidekiq decouples execution and storage nicely by using Redis as the backend data store. Sidekiq clients act as producers of work that push items that describe that work (job type, arguments, etc.) into a Redis List data structure. The Sidekiq server iteratively consumes the items one by one and executes them. When there is no job left, Sidekiq blocks and waits for more job items to become available. This is achieved internally with the BRPOP command.
Scalability and Bottlenecks
On the Sidekiq client side, we normally observe multiple clients sending jobs. This is expected, since one of the main reasons for incorporating a background processing system is to offload work from user-facing services and process it asynchronously.
Let's focus on the Sidekiq server (or execution) side, with the backend data store being Redis. Sidekiq can spawn multiple processes since Ruby's global interpreter lock (GIL) prevents code from running in parallel. Yes, code can run concurrently, but this is not to be confused with parallelism. And note here that the main use of multi-threaded Sidekiq processes is mainly to allow multiplexing of IO. JRuby is an exception, but it's also esoteric, since JRuby is not always available or used by Sidekiq users and a more general approach is preferable. In a nutshell, more processes lead to more requests, and parallel task execution achieves higher throughput. The only reason we opted for multiple processes for benchmarking and optimization is that we assumed that plain Ruby was more relevant to a larger audience. And both approaches (JRuby threads vs. multiple Ruby processes) work equally well.
As for the backend store, we have Redis, which is single-threaded from the perspective of command execution. Scaling Redis can be done by creating a Redis Cluster. Unfortunately, this comes with its own set of limitations such as operational complexity, and not being able to guarantee high-performance transactions. Thus, as mentioned above, it is discouraged to use Redis Cluster for Sidekiq by the Sidekiq maintainers themselves. The key takeaway here is that the more you start scaling Sidekiq, the more pressure you build up on Redis, which at some point inevitably becomes the main bottleneck in the overall throughput (jobs/sec).
Now you might be wondering why bother with all of these details; it's all about integration, right? Nope! Integration is the easy part. Dragonfly is Redis API-compatible, so switching from Redis to Dragonfly is as easy as shutting down the former and starting the latter. The details become essential when performance is desired, and as you will see later, Dragonfly's architecture enables Sidekiq to scale to a new level. This journey is all about a few of the optimizations that unlocked some of the performance bottlenecks along the way.
Benchmark Preparation
We based our work on the benchmark found here. The benchmark spawns a single Sidekiq process, and it pushes N no-op jobs to the work queue. It then starts measuring how much time it took to fetch and process those jobs. Since the job item itself is a no-op operation, we effectively measure IO, that is, how much throughput (jobs/sec) Sidekiq can pull out of the backend data store before it becomes a bottleneck.
Our approach incorporates the following changes:
- Add support to Sidekiq's benchmark to work with multiple Sidekiq processes. This allows us to scale the benchmark and showcase the limiting factors of higher throughput.
- We used an AWS
c5.4xlargeinstance to run the backend data store (Redis or Dragonfly). - We intentionally used a more powerful machine (AWS
c5a.24xlargewith 96 cores) to run the benchmark. This ensures that Sidekiq never becomes the bottleneck, as it can pull as many jobs as Dragonfly can deliver. - We used one queue per Sidekiq process.
- We intentionally don't measure the time clients used to push the data (i.e., adding jobs to the queue), because pushing or popping from the queue boils down to the same modification operations in the data store.
Benchmark Redis
First, we run the benchmark with Sidekiq operating on Redis, with 96 Sidekiq processes and 1 million jobs per queue. The table below summarizes the results:
| Queues | Total Jobs | Redis Throughput (Jobs/Sec) |
|---|---|---|
| 1 | 1M | 137,516 |
| 2 | 2M | 142,873 |
| 8 | 8M | 143,420 |
As you can see, there is a hard limit of roughly 140k jobs/sec. The reason is that, as discussed above, Redis runs mostly on a single thread. So even if we increase the number of queues, we still use 1/Nth of the available processing power, with N as the number of threads defined by --proactor_threads for Dragonfly.
Benchmark Dragonfly Baseline
Ideally, we would like to scale Dragonfly linearly to the number of threads N available. Although impossible in practice due to the inherent abstraction cost of distributing work and other transactional characteristics, the closer we are to that number, the happier we should be. This number is mostly our theoretical maximum, as if one thread can deliver X jobs, then N threads should deliver X * N jobs.
Now let's run the same benchmark with Dragonfly configured in the following different ways. Note that we also match the number of Dragonfly threads to the number of queues.
- With
--proactor_threads=1which limits Dragonfly to running on a single thread, just like Redis. - With
--proactor_threads=2which runs Dragonfly on 2 threads. - With
--proactor_threads=8which runs Dragonfly on 8 threads.
The table below summarizes the results:
| Queues & Dragonfly Threads | Total Jobs | Dragonfly Throughput (Jobs/Sec) |
|---|---|---|
| 1 | 1M | 50,776 (Baseline) |
| 2 | 2M | 11,2647 |
| 8 | 8M | 148,646 |
This is our baseline. Single-threaded Dragonfly delivers almost half of Redis throughput, and the configuration with 8 threads is as fast as Redis, which is way below our expectations. We used the htop command to observe the utilization of each CPU core, and the first thing we noticed was that the load was not equally spread among the available cores. Some of the 8 CPU cores were in fact underutilized, while others were loaded at more than 90% capacity.
To understand why, we first need to dive a little bit into Dragonfly internals. To fully leverage hardware resources, Dragonfly uses a shared-nothing architecture and splits its keyspace into shards. Each shard is owned by a single Dragonfly thread, and access to the data is coordinated via our transactional framework. For our use case, the data are the contents of each of the queues. To decide which thread owns a queue, Dragonfly hashes the name of the queue and modulo it by the number of threads.
The main observation above in the benchmark is that the multiple queues were not evenly spread among the available shards, effectively reducing the degree of parallelism in the system. Simply put, some Dragonfly threads were much busier than others.
Optimization With Round-Robin Load Balancing
To reconcile with this, we slightly configure Dragonfly differently with the server flag --shard_round_robin_prefix. With this flag, keys (i.e., names of the queues) with a certain prefix are distributed in a round-robin fashion. This effectively acts as a load balancer, spreading the queues fairly among the available shard threads. Running the same benchmarks with the above setup got us:
| Queues & Dragonfly Threads | Total Jobs | Dragonfly Throughput (Jobs/Sec) |
|---|---|---|
| 1 | 1M | 50,776 |
| 2 | 2M | 113,788 |
| 8 | 8M | 320,377 (Round-Robin) |
The first benchmark with --proactor_threads=1 for Dragonfly is not really affected since it's single-threaded. The same applies to the second benchmark because both queues end up on two different shards anyway. However, for the third benchmark with --proactor_threads=8 and --shard_round_robin_prefix for Dragonfly, the throughput was increased by 2x from the previous benchmark. Here is the htop output with round-robin load balancing:

The per-core saturation is a little bit more balanced, but what drives the performance boost is the greater degree of parallelism. This becomes even more apparent when you scale on larger machines with--proactor_threads set to 16, 32, 64, 128, etc., as more and more queues end up on the same shard thread, severely halting parallelization.
This is definitely an improvement from the previous run, but we are not quite there yet because both the single and two-threaded variants are still significantly slower. What are the other low-hanging fruits?
Optimization With Hops and Transactions
One of the key insights in figuring out the bottlenecks was in the implementation of multi-key blocking commands like BRPOP. Remember when I talked briefly above about shard threads and the transactional framework in Dragonfly? Well, a multi-key command may access data on different shard threads, and this action is performed by executing callbacks on them. A single dispatch set of those callbacks is called a hop, and a transaction can be either multi-hop or single-hop. Multi-hop transactions are generally more involved because they require submitting work to different shard threads iteratively, and there is latency when distributing work over and holding locks associated with keys longer. In the meantime, single-hop transactions have certain optimizations built-in.
Circling back to the blocking commands, BRPOP is implemented as a multi-hop transaction. The general case (without blocking) is that we do a single hop to the shard threads that contain the requested queues (i.e., BRPOP queue_01 queue_02) and check if they are non-empty. And this is how the first hop looks:
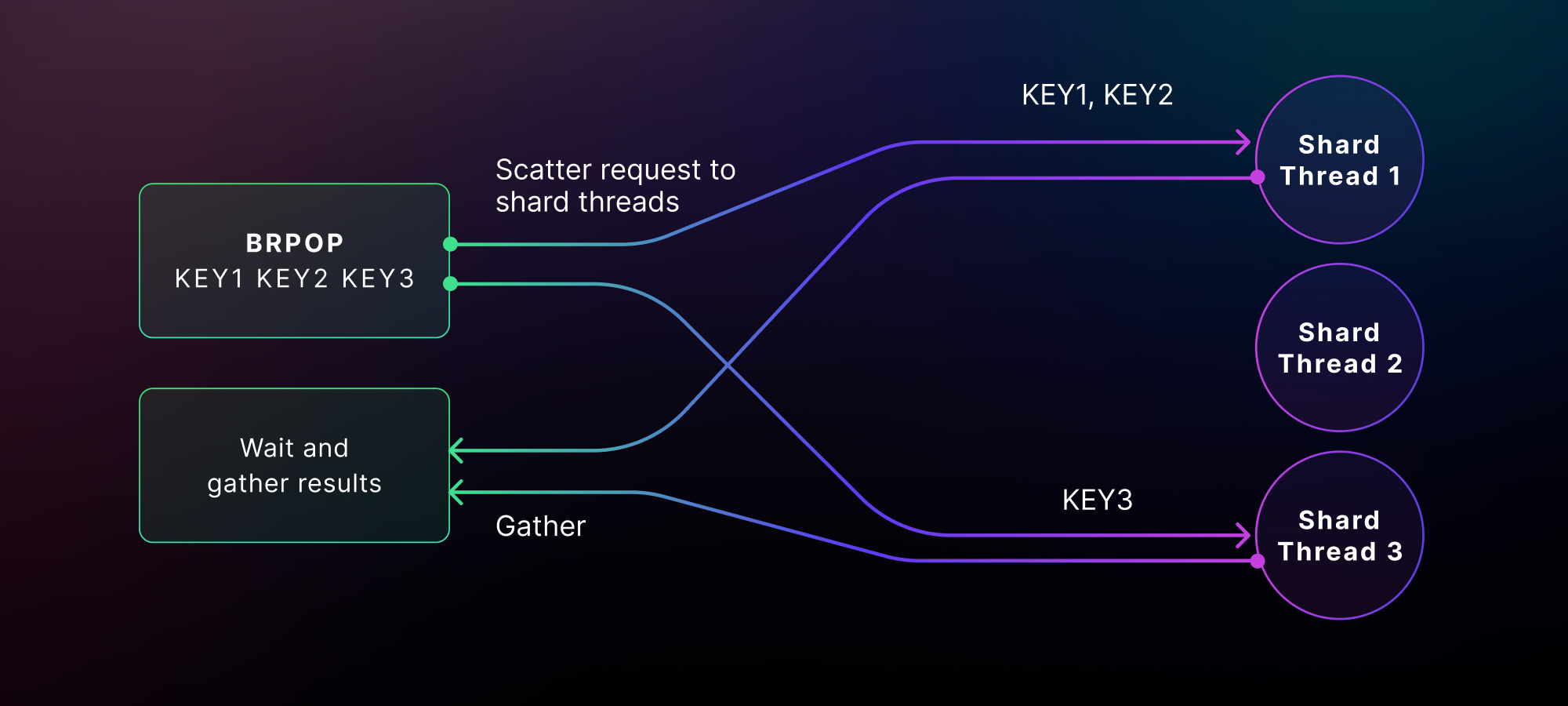
Since BRPOP takes multiple queue names as input, it checks all of them but only pops one element at a time from these queues. Dragonfly then filters and reduces the results to only one by finding the first queue that is non-empty. Lastly, Dragonfly performs an extra hop to fetch the item from the queue we picked. The full dance is thus a multi-hop transaction, which looks like below:
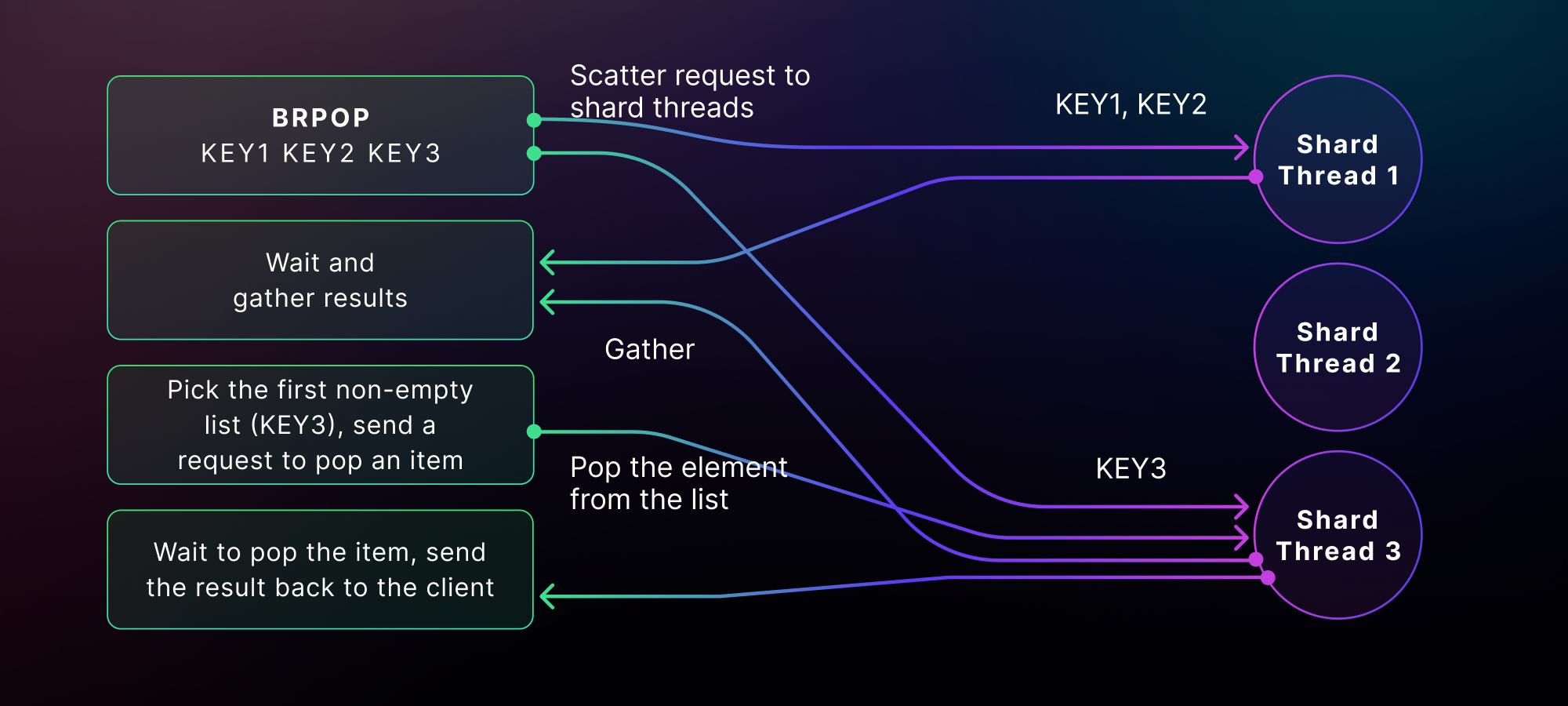
So, can we do better for the Sidekiq-specific use case with the BRPOP command?
Notice the access pattern of Sidekiq processes. They always consume from the same single queue. First, there is always a single queue that is used to call BRPOP. Second, the queue is always non-empty, and we could run opportunistically, meaning that we can squash "polling for the queue to be non-empty" and "fetching the item from the queue" into a single hop. And when this doesn't happen (i.e., the queue is empty and blocking is needed), we fall back to the previous two-hop dance.
We introduced this single-hop, single-shard optimization for blocking commands and added a new configuration flag --singlehop_blocking which defaults to true. The biggest benefit of this optimization, besides the reduction of hops, is that now blocking transactions can both be inline and quick. The former is when the transaction runs on the same shard thread as the one the command would hop to. The latter is when there are no conflicting transactions; that is, no other transaction holds locks to the same keys. When this is true, we have an optimization in place that pretty much bypasses the transactional framework altogether (we don't submit work or acquire any locks) and executes the command eagerly, improving latency and performance significantly. This works because only one fiber at a time can be active on a single shard thread, and this is important:
- Assuming there are no other active transactions that hold locks to the same keys
- For those of you who don't know, a fiber is a lightweight thread, and it only exists in user space. Fibers must decide when to preempt, and when they do, they suspend themselves and pass control to the scheduler. The scheduler switches and activates the next fiber with the highest priority. Therefore, there can be lots of fibers per shard thread, but only one can be active at any time. This mechanism guarantees that the fiber won't get interrupted by any other transaction, and this allows us to bypass the transactional framework altogether without violating any of our transactional guarantees.
The great news is that this applies automatically to the access patterns of our use case, and therefore a lot of the BRPOP commands end up as quick transactions. This boosts our results nicely, with 488k jobs/sec for 8 queues and 8 Dragonfly threads.
| Queues & Dragonfly Threads | Total Jobs | Throughput (Jobs/Sec) |
|---|---|---|
| 1 | 1M | 115,528 |
| 2 | 2M | 241,259 |
| 8 | 8M | 487,781 (Round-Robin & Single-Hop) |
Note that transactional statistics from the server side can be accessed via the INFO ALL command. If you run the different steps with INFO ALL, you will notice a huge change in the underline transaction types.
Conclusion
In this article, we discussed the integration of Sidekiq with Dragonfly and the optimizations we introduced to increase the overall throughput. To run Sidekiq with Dragonfly in just a few minutes, you can follow the instructions in this new Sidekiq integration guide.
I believe that it's really rewarding to work on a system that is capable of saturating the hardware. What's even more rewarding is the process of optimizing the different use cases that arise along the way. You know you had a good day when you spot and cut out those low-hanging fruits, and you observe in real-time your system revving like a 90's Shelby. We saw a nice ~9.6x increase from our Dragonfly baseline (scaled from 51k to 488k) and a ~3.5x boost compared to Redis (140k vs. 488k). Can we do better? Maybe, but that would be a subject for a future blog post.
Appendix: Benchmark Setup and Details
For those who want to reproduce the benchmark results, here are the details:
- We used an AWS
c5.4xlargeinstance for running Dragonfly or Redis. - We used an AWS
c5a.24xlargeinstance for running Sidekiq. - Each queue was filled with 1 million no-op jobs. So for 8 queues, we had 8 million jobs in total.
- The operating system was Ubuntu v22.04 with Kernel version
6.2.0-1017-aws. - To run Dragonfly, we used the following command:
$> ./dragonfly --proactor_threads=8 \ # 1, 2, 8
--shard_round_robin_prefix="queue" \ # with the round-robin load balancing- To run the benchmark, we used the command below. Note that we matched the number queues with the number of Dragonfly threads.
$> RUBY_YJIT_ENABLE=1 PROCESSES=96 QUEUES=1 THREADS=10 ./multi_queue_bench