CockroachDB Multi-Region Abstractions for MongoDB Developers With FerretDB

What started as an experiment turned into a series of articles on FerretDB and CockroachDB. There are a lot of untapped opportunities realized by FerretDB backed by CockroachDB; some of those capabilities are computed columns with secondary indexes, partial indexes, constraints, spatial capabilities, JSONB operators, multi-region abstractions and of course correctness and consistency. Today, we're going to discuss CockroachDB multi-region capabilities and how they can help the MongoDB converts.
High-Level Steps
- Start a 9-node multi-region cluster (CockroachDB Dedicated)
- Start FerretDB (Docker)
- Multi-Region
- REGIONAL BY TABLE
- GLOBAL
- Follower Reads
- REGIONAL BY ROW
- Considerations
- Conclusion
Step-by-Step Instructions
Start a 9-Node Multi-Region Cluster (Cockroachdb Dedicated)
I am going to use the same CockroachDB Dedicated cluster from the previous article. Please refer to the previous article for the detailed steps. You can get a 30-day trial of CockroachDB Dedicated following this link.
Start FerretDB (Docker)
I'll be using the same compose file from the previous article, however, as we will be discussing multi-region, I will make changes to the compose file and highlight them.
Multi-Region
Our experiment is based on the sample_mflix dataset available on the MongoDB website. I'm going to use the users collection from the previous article for one part of the tutorial and the theaters collection for another part.
If you haven't done so already, restore the collections:
mongorestore --archive=sampledata.archive --nsInclude=sample_mflix.users --numInsertionWorkersPerCollection=100
mongorestore --archive=sampledata.archive --nsInclude=sample_mflix.theaters --numInsertionWorkersPerCollection=100Each document in the users collection contains a single user and their name, email, and password.
{
"_id": {
"$oid": "59b99db4cfa9a34dcd7885b6"
},
"name": "Ned Stark",
"email": "sean_bean@gameofthron.es",
"password": "$2b$12$UREFwsRUoyF0CRqGNK0LzO0HM/jLhgUCNNIJ9RJAqMUQ74crlJ1Vu"
}The theaters contains a single movie theatre and its location in both string and GeoJSON formats.
{
"_id": {
"$oid": "59a47286cfa9a3a73e51e72c"
},
"theaterId": {
"$numberInt": "1000"
},
"location": {
"address": {
"street1": "340 W Market",
"city": "Bloomington",
"state": "MN",
"zipcode": "55425"
},
"geo": {
"type": "Point",
"coordinates": [
{
"$numberDouble": "-93.24565"
},
{
"$numberDouble": "44.85466"
}
]
}
}
}We are going to focus on the text data today, we will revisit GeoJSON at some later time.
Making a database multi-region-ready consists of four steps:
- Define Cluster region
- Define Database region
- Define Survival goal
- Define Table locality
The first step is covered as soon as CockroachDB is deployed across several regions. Setting up database regions is as simple as running the following commands:
ALTER DATABASE ferretdb PRIMARY REGION "aws-us-east-1";
ALTER DATABASE ferretdb ADD REGION "aws-us-east-2";
ALTER DATABASE ferretdb ADD REGION "aws-us-west-2";The database regions should match the cluster regions. However, there can be many more cluster regions than database regions in a single cluster. That allows CockroachDB to support GDPR use cases if a workload demands it.
The survival goals default to zone survivability. After you run the commands above, you should have a database ferretdb with the following behaviour:
- A database with a replica in each region
- Ability to survive zone failures
- Low latency reads and writes from the primary region
Looking at the database configuration:
SHOW ZONE CONFIGURATION FOR DATABASE ferretdb; DATABASE ferretdb | ALTER DATABASE ferretdb CONFIGURE ZONE USING
| range_min_bytes = 134217728,
| range_max_bytes = 536870912,
| gc.ttlseconds = 90000,
| num_replicas = 5,
| num_voters = 3,
| constraints = '{+region=aws-us-east-1: 1, +region=aws-us-east-2: 1, +region=aws-us-west-2: 1}',
| voter_constraints = '[+region=aws-us-east-1]',
| lease_preferences = '[[+region=aws-us-east-1]]'We have everything we need to look at the multi-region abstractions.
Regional by Table
The schema for sample_mflix.users_5e7cc513 table is:
CREATE TABLE sample_mflix.users_5e7cc513 (
_jsonb JSONB NULL,
rowid INT8 NOT VISIBLE NOT NULL DEFAULT unique_rowid(),
CONSTRAINT users_5e7cc513_pkey PRIMARY KEY (rowid ASC)
) LOCALITY REGIONAL BY TABLE IN PRIMARY REGIONNotice the LOCALITY REGIONAL BY TABLE IN PRIMARY REGION clause. REGIONAL BY TABLE are good candidates when your application requires low-latency reads and writes for an entire table from a single region. It is also a default property.
Let's see the impact on latency:
SELECT gateway_region(), "_jsonb"->'email' AS email_addr FROM sample_mflix.users_5e7cc513 LIMIT 1;US East
Plain Text
gateway_region | email_addr
-----------------+-----------------------------
aws-us-east-1 | "sean_bean@gameofthron.es"
Time: 20ms total (execution 1ms / network 19ms)
gateway_region | email_addr
-----------------+-----------------------------
aws-us-east-1 | "sean_bean@gameofthron.es"
Time: 20ms total (execution 1ms / network 19ms)This is acceptable, what's the impact if we access from a different region?
US West
Plain Text
gateway_region | email_addr
-----------------+-----------------------------
aws-us-west-2 | "sean_bean@gameofthron.es"
Time: 144ms total (execution 66ms / network 79ms)
gateway_region | email_addr
-----------------+-----------------------------
aws-us-west-2 | "sean_bean@gameofthron.es"
Time: 144ms total (execution 66ms / network 79ms)That's not optimal and this is where the next feature can help:
Global
Our users table has 185 records. It will be primarily used for accessing user records. Since this table is rarely updated, it makes a good candidate for the GLOBAL locality.
Global tables have the following characteristics:
- fast strongly consistent reads from every region
- slower writes in every region
Use global tables when your application has a "read-mostly" table of reference data that is rarely updated, and needs to be available to all regions.
We're going to change the table locality of the user's table using the following syntax
ALTER TABLE sample_mflix.users_5e7cc513 SET locality GLOBAL;We do not have a foreign key relationship on any other collection, that may come later. Referencing a foreign key relationship on a global table can speed up lookup queries.
After we change the locality we can execute the queries again:
SELECT gateway_region(), "_jsonb"->'email' AS email_addr FROM sample_mflix.users_5e7cc513 LIMIT 1;
US East
Plain Text
gateway_region | email_addr
----------------+-----------------------------
aws-us-east-1 | "sean_bean@gameofthron.es"
Time: 20ms total (execution 1ms / network 19ms)
gateway_region | email_addr
----------------+-----------------------------
aws-us-east-1 | "sean_bean@gameofthron.es"
Time: 20ms total (execution 1ms / network 19ms)The latency is acceptable as I'm in close proximity to the AWS-us-east-1 region.
US West
Plain Text
gateway_region | email_addr
-----------------+-----------------------------
aws-us-west-2 | "sean_bean@gameofthron.es"
Time: 80ms total (execution 1ms / network 79ms)
gateway_region | email_addr
-----------------+-----------------------------
aws-us-west-2 | "sean_bean@gameofthron.es"
Time: 80ms total (execution 1ms / network 79ms)The network latency can be explained as that's the round trip time from the client to the gateway. The execution time, however, decreased significantly.
db.collection.latencyStats() method is not implemented in FerretDB and I cannot demonstrate the performance benefits using the mongosh client:
sample_mflix> db.users.latencyStats()
MongoServerError: `aggregate` command is not implemented yetFollower Reads
The following capability in CockroachDB allows querying data at an earlier timestamp, akin to time travel queries. The trade-off to cross-region latency is slightly stale data. The Follower Reads read from the local replicas instead of the quorum leader, which can be physically located in another region. It can be accessed by appending AS OF SYSTEM TIME syntax to the end of your SELECT queries.
SELECT gateway_region() AS region, "_jsonb"->'email' AS email_addr FROM sample_mflix.users_5e7cc513 AS OF SYSTEM TIME follower_read_timestamp() LIMIT 1;US East
Plain Text
region | email_addr
----------------+-----------------------------
aws-us-east-1 | "sean_bean@gameofthron.es"
Time: 20ms total (execution 1ms / network 19ms)
region | email_addr
----------------+-----------------------------
aws-us-east-1 | "sean_bean@gameofthron.es"
Time: 20ms total (execution 1ms / network 19ms)US West
Plain Text
region | email_addr
----------------+-----------------------------
aws-us-west-2 | "sean_bean@gameofthron.es"
Time: 71ms total (execution 1ms / network 70ms)
region | email_addr
----------------+-----------------------------
aws-us-west-2 | "sean_bean@gameofthron.es"
Time: 71ms total (execution 1ms / network 70ms)Along with predictable query latency across all regions, the are no schema changes necessary and there's no impact on writes compared to the GLOBAL tables. There are however drawbacks. Where GLOBAL tables serve strongly consistent reads, follower reads serve bounded staleness reads. CockroachDB operates in serializable isolation but AOST is akin to read committed isolation. The follower reads have many applications in CockroachDB, such as backup and restore, as they do not impact foreground traffic, which leads to minimal retrying in errors and timeouts. The function follower_read_timestamp() is not the only TIME interval you can pass to AS OF SYSTEM TIME. It will accept any time interval between now and the gc.ttl window, by default 25 hours.
SELECT gateway_region() AS region, "_jsonb"->'email' AS email_addr FROM sample_mflix.users_5e7cc513 AS OF SYSTEM TIME '-10m' LIMIT 1;The query will return the value as of 10 minutes ago.
Regional by Row
REGIONAL BY ROW tables have the following characteristics:
- The tables are optimized for fast access from a single region
- The region is specified at a row level
Use regional by row tables when your application requires low-latency reads and writes at a row level where individual rows are primarily accessed from a single region. For example, a user's table in a global application may need to keep some users' data in specific regions for better performance.
We can continue using the users collection but considering the theaters collection has locations associated with it, we're going to focus on that instead. For example, we'd like to update or return information about a nearby theatre.
SELECT DISTINCT("_jsonb"->'location'->'address'->>'state') FROM sample_mflix.theaters_cf846063
ORDER BY "_jsonb"->'location'->'address'->>'state'; AK
AL
AR
AZ
CA
CO
CT
DC
DE
FL
GA
(52 rows)We are going to partition our dataset by the state into three AWS regions. I sorted the states in alphabetical order and blindly placed them into three buckets, one for each region.
ALTER TABLE sample_mflix.theaters_cf846063 ADD COLUMN region crdb_internal_region NOT NULL AS (
CASE WHEN ("_jsonb"->'location'->'address'->>'state') IN ('AK','AL','AR','AZ','CA','CO','CT','DC','DE','FL','GA','HI','IA','ID','IL','IN','KS','KY','LA') THEN 'aws-us-west-2'
WHEN ("_jsonb"->'location'->'address'->>'state') IN ('MA','MD','ME','MI','MN','MO','MS','MT','NC','ND','NE','NH','NJ','NM','NV','NY') THEN 'aws-us-east-1'
WHEN ("_jsonb"->'location'->'address'->>'state') IN ('OH','OK','OR','PA','PR','RI','SC','SD','TN','TX','UT','VA','VT','WA','WI','WV','WY') THEN 'aws-us-east-2'
END
) STORED;If you get the following error
ERROR: null value in column "region" violates not-null constraint
SQLSTATE: 23502It means there are rows in the table with a state field that are not reflected in the partition logic.
We can inspect the schema again
CREATE TABLE sample_mflix.theaters_cf846063 (
_jsonb JSONB NULL,
rowid INT8 NOT VISIBLE NOT NULL DEFAULT unique_rowid(),
region public.crdb_internal_region NOT NULL AS (CASE WHEN (((_jsonb->'location':::STRING)->'address':::STRING)->>'state':::STRING) IN ('AK':::STRING, 'AL':::STRING, 'AR':::STRING, 'AZ':::STRING, 'CA':::STRING, 'CO':::STRING, 'CT':::STRING, 'DC':::STRING, 'DE':::STRING, 'FL':::STRING, 'GA':::STRING, 'HI':::STRING, 'IA':::STRING, 'ID':::STRING, 'IL':::STRING, 'IN':::STRING, 'KS':::STRING, 'KY':::STRING, 'LA':::STRING) THEN 'aws-us-west-2':::public.crdb_internal_region WHEN (((_jsonb->'location':::STRING)->'address':::STRING)->>'state':::STRING) IN ('MA':::STRING, 'MD':::STRING, 'ME':::STRING, 'MI':::STRING, 'MN':::STRING, 'MO':::STRING, 'MS':::STRING, 'MT':::STRING, 'NC':::STRING, 'ND':::STRING, 'NE':::STRING, 'NH':::STRING, 'NJ':::STRING, 'NM':::STRING, 'NV':::STRING, 'NY':::STRING) THEN 'aws-us-east-1':::public.crdb_internal_region WHEN (((_jsonb->'location':::STRING)->'address':::STRING)->>'state':::STRING) IN ('OH':::STRING, 'OK':::STRING, 'OR':::STRING, 'PA':::STRING, 'PR':::STRING, 'RI':::STRING, 'SC':::STRING, 'SD':::STRING, 'TN':::STRING, 'TX':::STRING, 'UT':::STRING, 'VA':::STRING, 'VT':::STRING, 'WA':::STRING, 'WI':::STRING, 'WV':::STRING, 'WY':::STRING) THEN 'aws-us-east-2':::public.crdb_internal_region END) STORED,
CONSTRAINT theaters_cf846063_pkey PRIMARY KEY (rowid ASC)
) LOCALITY REGIONAL BY TABLE IN PRIMARY REGIONLooking at the data:
SELECT DISTINCT("_jsonb"->'location'->'address'->>'state') AS state, region FROM sample_mflix.theaters_cf846063; state | region
--------+----------------
MI | aws-us-east-1
MN | aws-us-east-1
MD | aws-us-east-1
CA | aws-us-west-2
AL | aws-us-west-2
AZ | aws-us-west-2
WI | aws-us-east-2
IN | aws-us-west-2
NV | aws-us-east-1We have one more step to complete, we've not defined RBR locality:
ALTER TABLE sample_mflix.theaters_cf846063 SET LOCALITY REGIONAL BY ROW AS "region";
Let's fetch records from NJ in aws-us-east-1
SELECT gateway_region(), "_jsonb" FROM sample_mflix.theaters_cf846063
WHERE "_jsonb"->'location'->'address' @> '{"state":"NJ"}' LIMIT 1;US East
gateway_region | _jsonb
aws-us-east-1 | {"$k": ["_id", "theaterId", "location"], "_id": {"$o": "59a47287cfa9a3a73e51ed21"}, "location": {"$k": ["address", "geo"], "address": {"$k": ["street1", "city", "state", "zipcode"], "city": "Paramus", "state": "NJ", "street1": "1 Garden State Plaza", "zipcode": "07652"}, "geo": {"$k": ["type", "coordinates"], "coordinates": [{"$f": -74.074898}, {"$f": 40.915257}], "type": "Point"}}, "theaterId": 887}
Time: 26ms total (execution 6ms / network 20ms)Let's query from the US West region for a California theatre
aws-us-west-2 | {"$k": ["_id", "theaterId", "location"], "_id": {"$o": "59a47287cfa9a3a73e51ed27"}, "location": {"$k": ["address", "geo"], "address": {"$k": ["street1", "city", "state", "zipcode"], "city": "Gilroy", "state": "CA", "street1": "7011 Camino Arroyo", "zipcode": "95020"}, "geo": {"$k": ["type", "coordinates"], "coordinates": [{"$f": -121.55201}, {"$f": 37.006283}], "type": "Point"}}, "theaterId": 884}
Time: 554ms total (execution 476ms / network 78ms)Let's look at the execution plan
info
----------------------------------------------------------------------------------------------------
distribution: local
vectorized: true
• render
│ estimated row count: 1
│
└── • limit
│ estimated row count: 1
│ count: 1
│
└── • filter
│ estimated row count: 174
│ filter: ((_jsonb->'location')->'address') @> '{"state": "NY"}'
│
└── • scan
estimated row count: 9 - 1,564 (100% of the table; stats collected 41 minutes ago)
table: theaters_cf846063@theaters_cf846063_pkey
spans: [/'aws-us-east-1' - /'aws-us-east-1'] [/'aws-us-east-2' - /'aws-us-west-2']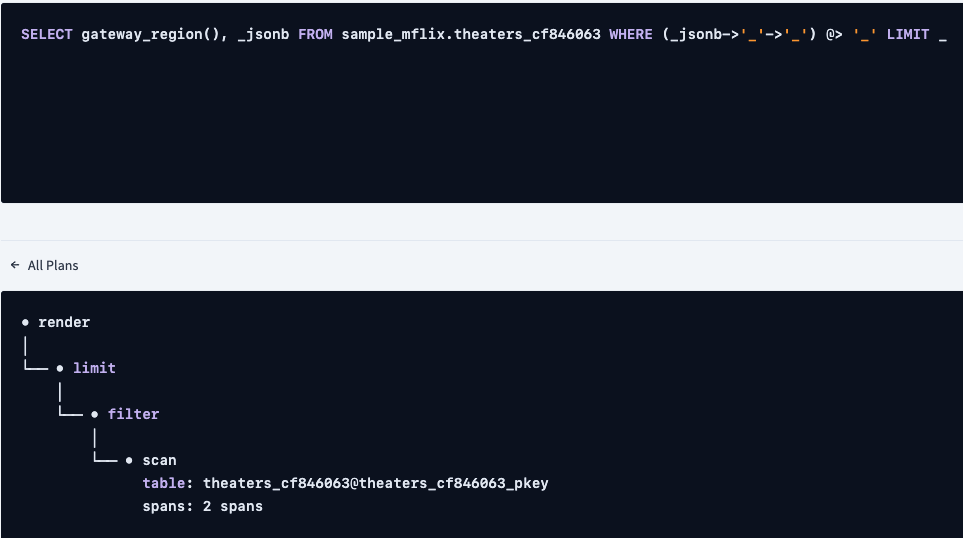
We see a scan on the table with a large number of rows. CockroachDB has the ability to index JSONB columns with inverted indexes, let's add one and see if anything changes
CREATE INDEX ON sample_mflix.theaters_cf846063 USING GIN(_jsonb);After the index, the plan looks like so:
info
----------------------------------------------------------------------------------------------------
distribution: local
vectorized: true
• render
│ estimated row count: 1
│
└── • index join
│ estimated row count: 1
│ table: theaters_cf846063@theaters_cf846063_pkey
│
└── • union all
│ estimated row count: 1
│ limit: 1
│
├── • scan
│ estimated row count: 1 (0.06% of the table; stats collected 45 minutes ago)
│ table: theaters_cf846063@theaters_cf846063__jsonb_idx
│ spans: [/'aws-us-east-1' - /'aws-us-east-1']
│ limit: 1
│
└── • scan
estimated row count: 1 (0.06% of the table; stats collected 45 minutes ago)
table: theaters_cf846063@theaters_cf846063__jsonb_idx
spans: [/'aws-us-east-2' - /'aws-us-east-2'] [/'aws-us-west-2' - /'aws-us-west-2']
limit: 1Unfortunately, there is a bug in the locality optimized search impacting queries with inverted indexes. The fix is already merged but it didn't make it into the version I'm using in my cluster. The latency will be improved but I can't demonstrate that until the fix is released. We do however have another option.
Before we proceed with the next step, I'm going to drop the inverted index from the previous step.
DROP INDEX sample_mflix.theaters_cf846063@theaters_cf846063__jsonb_idx;What will a query plan look like if we were to run the following query
db.theaters.find({"location.address.state": { $in: ['AZ']}})Surprisingly, it still shows the full table scan

The query uses an in the clause, we need an equivalent query in SQL. We also need to create a computed column on the state element and avoid using JSONB operators like "_jsonb"->'location'->'address', then we do not need to rely on inverted indexes.
ALTER TABLE sample_mflix.theaters_cf846063 ADD COLUMN state STRING NOT NULL AS (_jsonb->'location'->'address'->>'state') VIRTUAL;The select query syntax can be simplified:
SELECT gateway_region(), state FROM sample_mflix.theaters_cf846063 WHERE state IN ('NY') LIMIT 1;US East
Plain Text
gateway_region | state
-----------------+--------
aws-us-east-1 | NY
Time: 254ms total (execution 234ms / network 20ms)
gateway_region | state
-----------------+--------
aws-us-east-1 | NY
Time: 254ms total (execution 234ms / network 20ms)US West
gateway_region | state
-----------------+--------
aws-us-west-2 | CA
Time: 557ms total (execution 478ms / network 79ms)That's a big drop in performance, fortunately, we can improve performance by adding a regular index on the computed column
CREATE INDEX ON sample_mflix.theaters_cf846063 (state);
US East
Plain Text
gateway_region | state
-----------------+--------
aws-us-east-1 | NY
Time: 29ms total (execution 4ms / network 20ms)
gateway_region | state
-----------------+--------
aws-us-east-1 | NY
Time: 29ms total (execution 4ms / network 20ms)US West
gateway_region | state
-----------------+--------
aws-us-west-2 | CA
Time: 71ms total (execution 2ms / network 69ms)The explained plan looks better
distribution: local
vectorized: true
• render
│ estimated row count: 1
│
└── • index join
│ estimated row count: 1
│ table: theaters_cf846063@theaters_cf846063_pkey
│
└── • union all
│ estimated row count: 1
│ limit: 1
│
├── • scan
│ estimated row count: 1 (0.06% of the table; stats collected 36 seconds ago)
│ table: theaters_cf846063@theaters_cf846063_state_idx
│ spans: [/'aws-us-east-1'/'NY' - /'aws-us-east-1'/'NY']
│ limit: 1
│
└── • scan
estimated row count: 1 (0.06% of the table; stats collected 36 seconds ago)
table: theaters_cf846063@theaters_cf846063_state_idx
spans: [/'aws-us-east-2'/'NY' - /'aws-us-east-2'/'NY'] [/'aws-us-west-2'/'NY' - /'aws-us-west-2'/'NY']
limit: 1We're using the new index on the computed column but there is still an index join which we should remove. We need to change the computed column from VIRTUAL to STORED first.
SET sql_safe_updates = false;
ALTER TABLE sample_mflix.theaters_cf846063 DROP COLUMN state;
SET sql_safe_updates = true;This command will also drop the associated index as well, let's add the column back as STORED
ALTER TABLE sample_mflix.theaters_cf846063 ADD COLUMN state STRING NOT NULL AS (_jsonb->'location'->'address'->>'state') STORED;Let's also add the index back
CREATE INDEX ON sample_mflix.theaters_cf846063 (state);
The explained plan no longer has an index join
distribution: local
vectorized: true
• render
│ estimated row count: 1
│
└── • union all
│ estimated row count: 1
│ limit: 1
│
├── • scan
│ estimated row count: 1 (0.06% of the table; stats collected 2 minutes ago)
│ table: theaters_cf846063@theaters_cf846063_state_idx
│ spans: [/'aws-us-east-1'/'NY' - /'aws-us-east-1'/'NY']
│ limit: 1
│
└── • scan
estimated row count: 1 (0.06% of the table; stats collected 2 minutes ago)
table: theaters_cf846063@theaters_cf846063_state_idx
spans: [/'aws-us-east-2'/'NY' - /'aws-us-east-2'/'NY'] [/'aws-us-west-2'/'NY' - /'aws-us-west-2'/'NY']
limit: 1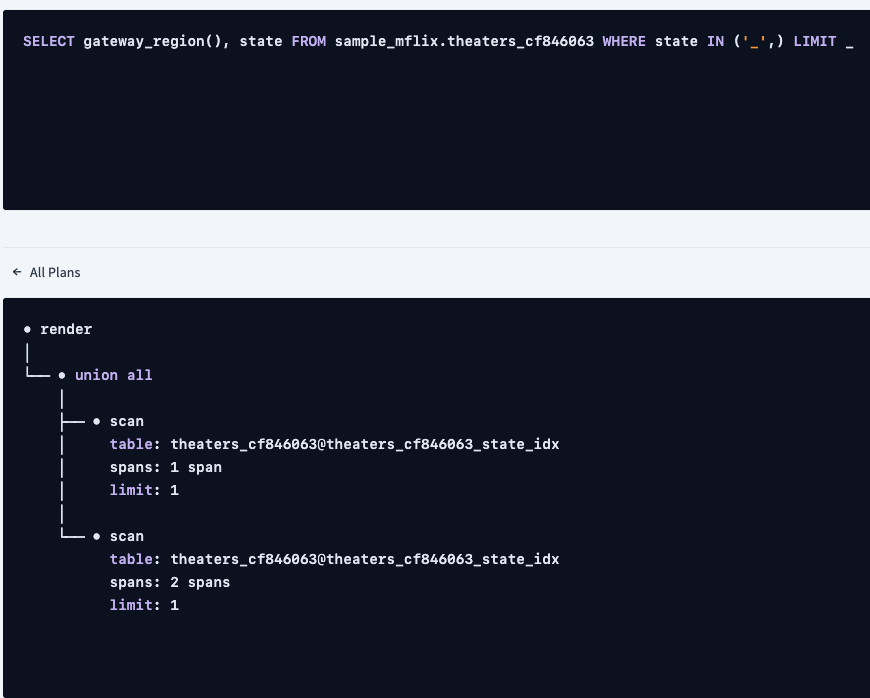
US East
Plain Text
gateway_region | state
-----------------+--------
aws-us-east-1 | NY
Time: 23ms total (execution 3ms / network 19ms)
gateway_region | state
-----------------+--------
aws-us-east-1 | NY
Time: 23ms total (execution 3ms / network 19ms)US West
gateway_region | state
-----------------+--------
aws-us-west-2 | CA
Time: 71ms total (execution 2ms / network 69ms)Notice the query execution time is equivalent to the query execution in the East region. Remote users benefit from local latencies wherever they are!
Sadly, FerretDB does not select the index when I run the following command
db.theaters.find({"location.address.state": { $in: ['AZ']}})

We will have to wait for when FerretDB addresses the long tail of their open issues.
We have one more optimization we can make that will avoid locality-optimized search entirely. We need to convert the computed column to a regular column.
As a first step, we need to reset the table by changing its locality to anything other than RBR.
ALTER TABLE sample_mflix.theaters_cf846063 SET LOCALITY REGIONAL BY TABLE;
SET sql_safe_updates = false;
ALTER TABLE sample_mflix.theaters_cf846063 DROP COLUMN region;
SET sql_safe_updates = true;Convert a computed column to a standard column, otherwise, if you attempt to partition the table you will get the following error
ERROR: computed column expression cannot reference computed columns
SQLSTATE: 42P16ALTER TABLE sample_mflix.theaters_cf846063 ALTER COLUMN state DROP STORED;Finally, partition the table by a regular column
ALTER TABLE sample_mflix.theaters_cf846063 ADD COLUMN region crdb_internal_region NOT NULL AS (
CASE WHEN state IN ('AK','AL','AR','AZ','CA','CO','CT','DC','DE','FL','GA','HI','IA','ID','IL','IN','KS','KY','LA') THEN 'aws-us-west-2'
WHEN state IN ('MA','MD','ME','MI','MN','MO','MS','MT','NC','ND','NE','NH','NJ','NM','NV','NY') THEN 'aws-us-east-1'
WHEN state IN ('OH','OK','OR','PA','PR','RI','SC','SD','TN','TX','UT','VA','VT','WA','WI','WV','WY') THEN 'aws-us-east-2'
END
) STORED;Change the table to RBR
ALTER TABLE sample_mflix.theaters_cf846063 SET LOCALITY REGIONAL BY ROW AS "region";
US East
Plain Text
gateway_region | state
-----------------+--------
aws-us-east-1 | NY
Time: 22ms total (execution 3ms / network 20ms)
gateway_region | state
-----------------+--------
aws-us-east-1 | NY
Time: 22ms total (execution 3ms / network 20ms)The explained plan for the query now looks like so
distribution: local
vectorized: true
• render
│ estimated row count: 1
│
└── • scan
estimated row count: 1 (0.06% of the table; stats collected 3 minutes ago)
table: theaters_cf846063@theaters_cf846063_state_idx
spans: [/'aws-us-east-1'/'NY' - /'aws-us-east-1'/'NY']
limit: 1We no longer need to leverage locality-based search because the filter on state, i.e. state = 'NY' specifies which partition to look in.
US West
Plain Text
gateway_region | state
-----------------+--------
aws-us-west-2 | CA
Time: 70ms total (execution 2ms / network 69ms)
gateway_region | state
-----------------+--------
aws-us-west-2 | CA
Time: 70ms total (execution 2ms / network 69ms)
Considerations
REGIONAL BY ROW tables have a lot of potentials and it took me a lot of effort to get to the end goal but we did cover a lot of corner cases. To summarize our effort, our steps were:
- Create a computed column on the state element in the JSONB payload
- Convert the computed column to a regular column
- Index the state column
- Partition the table by the state column
- Create an RBR table
Prior to this article, I was unaware of the ability to convert a computed column to a regular column with a single command.
Conclusion
This concludes our tour of multi-region abstractions in CockroachDB. There are additional capabilities we've not discussed in this article but I hope I was able to demonstrate how users in remote regions can get the same user experience as local database users.
Previous Articles on CockroachDB and FerretDB
- Using CockroachDB for FerretDB Backend
- Migrating MongoDB Collections to CockroachDB With FerretDB
- Experimenting With Unique Constraints in CockroachDB, MongoDB, and FerretDB
