RabbitMQ vs. Memphis.dev

What Is RabbitMQ?
RabbitMQ is a lightweight and easy-to-deploy messaging queue for on-premises and cloud environments. It supports multiple messaging protocols. RabbitMQ can be deployed in distributed and federated configurations to meet high-scale, high-availability requirements.
What Is Memphis.dev?
Memphis is a next-generation message broker.
A simple, robust, and durable cloud-native message broker wrapped with an entire ecosystem that enables fast and reliable development of next-generation event-driven use cases.
Memphis.dev enables building next-generation applications that require large volumes of streamed and enriched data, modern protocols, zero ops, rapid development, extreme cost reduction, and a significantly lower amount of dev time for data-oriented developers and data engineers.
General
|
Parameter
|
Memphis.dev
|
RabbitMQ
|
|---|---|---|
|
License
|
Apache 2.0
|
Mozilla Public
|
|
Components
|
Memphis + MongoDB (MDB is being removed)
|
RabbitMQ
|
|
Message consumption model
|
Pull
|
Push
|
|
Storage architecture
|
Log
|
Index
|
License
Both technologies are available under fully open-source licenses. Memphis also has a commercial-based distribution with added security, tiered storage, and more.
Components
Memphis uses MongoDB for GUI state management only and will be removed soon, making Memphis without any external dependency. Both Memphis and RabbitMQ achieve consensus by using RAFT.
Message Consumption Model
RabbitMQ uses a push-based approach synonymous with traditional messaging systems.
Memphis uses a pull-based architecture where consumers pull messages from the server, and long-polling ensures new messages are made available instantaneously.
Pull-based architectures are often preferable for high throughput workloads as they allow consumers to manage their flow control, fetching only what they need.
Storage Architecture
RabbitMQ uses index-based storage systems. These keep data in a tree structure to provide the fast access necessary for acknowledging individual messages.
Memphis uses a distributed commit log called streams (made by NATS Jetstream) as its storage layer, which can be written entirely on the broker’s (server) memory or disk. In addition, Memphis abstracts the offsets by default, so saving a record of the used offsets resides on Memphis and not on the client.
Messaging
|
Parameter
|
Memphis.dev
|
RabbitMQ
|
|---|---|---|
|
Performance
|
300K messages per second per station (queue).
|
4K-10K messages per second
|
|
Message Retention
|
Policy-based (e.g., 30 days)
|
Acknowledgment based
|
|
Data Type
|
Transactional, Operational
|
Transactional
|
|
Consumer Mode
|
Smart broker/Smart consumer
|
Smart broker/dumb consumer
|
|
Topology
|
Publish/subscribe based
|
Exchange type: Direct, Fan out, Topic, Header-based
|
|
Payload Size
|
Up to 15M
|
No constraints
|
|
Use Cases
|
Massive data/high throughput cases | Simple use cases
|
Simple use cases
|
|
Delivery Guarantee
|
At least once, Exactly once
|
Especially in relation to transactions utilizing a single queue, it does not guarantee atomicity.
|
|
Message ordering
|
Message ordering is provided via consumer groups. By message key, messages are sent to stations.
|
Unsupported.
|
|
Message priorities
|
Unavailable
|
You can set message priorities in RabbitMQ and consume messages in the order of highest priority.
|
|
Message lifetime
|
Since station messages are kept on file/memory. This can be controlled by defining a retention policy.
|
Because RabbitMQ is a queue, messages are discarded after being read, and an acknowledgment is given.
|
|
Clustering
|
Active-Active
|
Active-Passive
|
|
Multi-region
|
Supported*
|
No
|
|
Multi-tenancy
|
Namespaces including node selection *
|
vHosts
|
|
Read-replicas
|
Supported*
|
No
|
|
Data striping across nodes
|
Supported
|
No
|
*Available for Memphis cloud users.
Data Flow
RabbitMQ uses a distinct, bounded data flow. Messages are created and sent by the producer and received by the consumer. Memphis uses an unbounded data flow, with the key-value pairs continuously streaming to the assigned station.
Data Usage
RabbitMQ is best for transactional data, such as order formation, placement, and user requests. Memphis works great for transactional and operational data like process operations, auditing and logging statistics, and system activity.
Message Retention
RabbitMQ pushes messages to consumers. These messages are removed from the queue once they are processed and acknowledged. Memphis is a log. It uses continuous messages, which stay in the station (queue) until the retention period expires.
Topology
RabbitMQ uses the exchange queue topology — sending messages to an exchange where they are, in turn, routed to various queue bindings for the consumer’s use. Memphis employs the publish/subscribe topology, sending messages across the streams to the correct stations and then consumed by users in the different authorized groups.
Architecture Differences
When choosing between Memphis and RabbitMQ, the internal operations and fundamental design can be essential considerations.
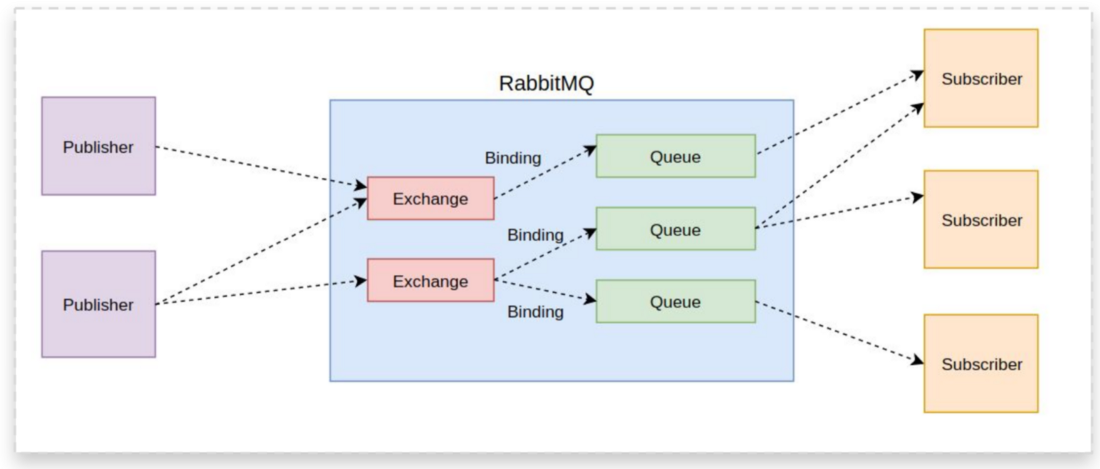
The components of RabbitMQ’s Architecture consist of the following:
- Queue: It is in charge of keeping track of messages that have been received and may have configuration data that specifies what it can do with a message.
- Exchange: An exchange receives messages sent to RabbitMQ and determines where they should be forwarded. Exchanges define the routing strategies used for messages, most frequently by examining the data characteristics transmitted with the message or included inside its attributes.
- Producer: Produces messages and sends them to a broker server (publishes). A payload and a label are the two components of a message. The user’s desired data to convey is the payload. The label specifies who should receive a copy of the message and describes the payload.
- Consumer: It subscribes to a queue and is connected to a broker server.
- Broker: Applications can exchange information and communicate with one another through a broker.
- Binding: It tells an exchange which queues to distribute messages. Additionally, the binding will instruct the exchange to filter which messages it is permitted to add to a queue for specific exchange types.
Memphis architecture is designed using the following components:
- Replicas: One of the most crucial elements of Memphis is replication, which ensures that messages are published and consumed even when the broker encounters a problem.
- RAFT: It maintains data coordination between brokers, such as configuration, location, data, and status details.
- Producer: Producers push or publish messages to a Memphis station created on a Memphis broker. Producers can also send messages to a broker synchronously or asynchronously.
- Consumers: Individuals who subscribe to a Memphis station and pull messages from it. Memphis allows data to be stored in additional storage platforms used by programs for online transaction processing (OLTP) besides internal disks and memory.
- Broker: Acts as a Memphis server or broker. The number of streams for each message is defined in accordance with the order in which the broker stores the messages.
Scalability and Redundancy
RabbitMQ uses a round-robin queue to repeat messages. The messages are divided among the queues to boost throughput and balance the load. Additionally, it enables numerous consumers to read messages from various queues simultaneously.
In Memphis, scalability and redundancy are provided by stream objects. The stream is duplicated across numerous brokers. In the event that one of the brokers fails, the data can still be served by another broker.
If data is stored in only one broker, the dependence on that broker will grow, which is hazardous and increases the likelihood that it will fail. Additionally, distributing the streams will vastly improve throughput.
Multi-Region/Multi-Cloud
The highest availability capability in RabbitMQ is cluster and quorum queues, which enable cross-node replication.
Besides mirroring and striping stations across multiple brokers, that can ultimately span across AZs. Partners and Memphis cloud users can establish a Memphis super-cluster across regions in an active/passive topology.
Multi-Tenancy
RabbitMQ is a multi-tenant system: connections, exchanges, queues, bindings, user permissions, policies, and some other things belong to virtual hosts and logical groups of entities.
Memphis supports multi-tenancy using namespaces which offers a complete separation from connections, producers, consumers, security, dedicated dashboard, including node selection.
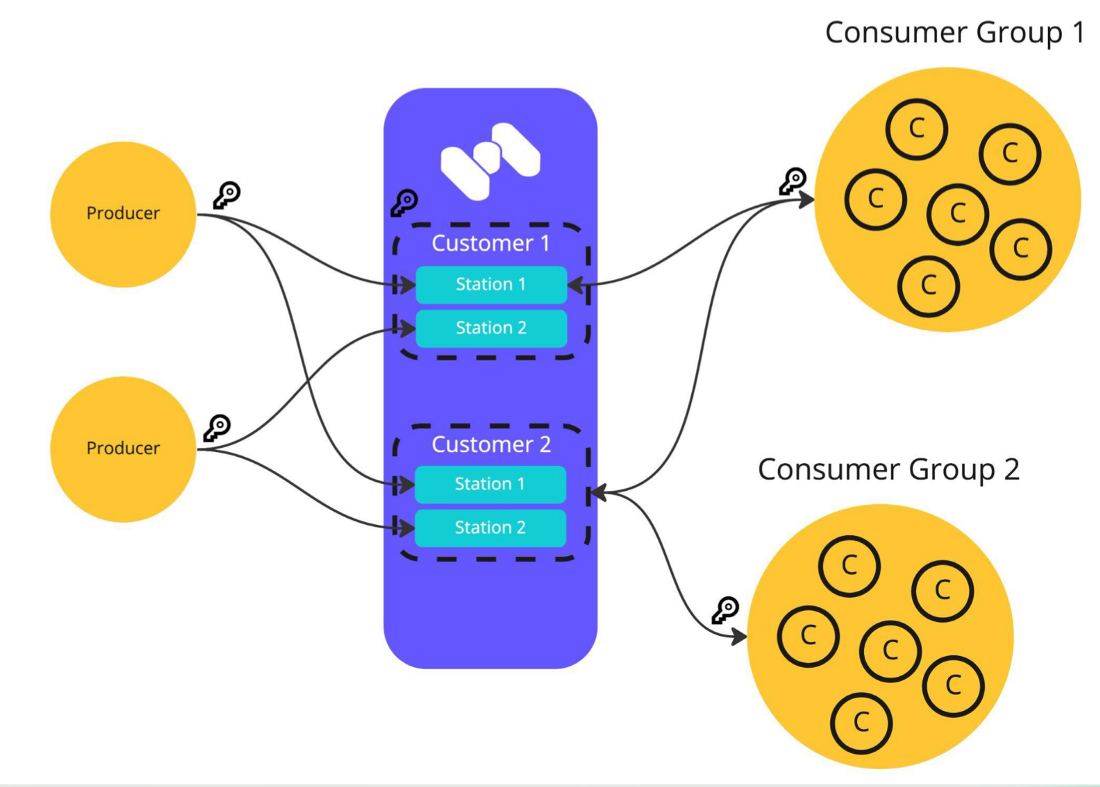
All data/state required for operating a RabbitMQ broker is replicated across all nodes. An exception is message queues, which by default reside on one node, though they are visible and reachable from all nodes. To replicate queues across nodes in a cluster, use a queue type that supports replication. This topic is covered in the Quorum Queues guide.
Memphis replicates data across brokers based on defined policy (Replicas). Memphis station can also span and stripe data across brokers to achieve higher throughput and availability.
Features
|
Parameter
|
Memphis.dev
|
RabbitMQ
|
|---|---|---|
|
GUI
|
Yes
|
Yes
|
|
Schema Management
|
Yes
|
No
|
|
Wildcard consume
|
No
|
Yes
|
|
Stream Enrichment
|
Yes
|
No
|
|
Ready-to-use source/sinks connectors
|
Yes
|
No
|
|
Stream lineage
|
Yes
|
No
|
|
Data-Level Observability
|
Yes
|
Yes
|
|
Self-healing
|
Yes
|
No
|
|
Deduplication
|
Yes. Modified bloom filter
|
Yes
|
|
Dead-letter
|
Yes
|
Yes
|
|
REST Gateway
|
Yes
|
No
|
|
Consumer internal communication
|
Experimental
|
No
|
|
Production deployment environment
|
Kubernetes
|
Kubernetes, Bare-metal
|
|
Storage tiering
|
Disk, Memory, and S3 for Archiving
|
Disk, Memory
|
|
Notifications
|
Slack, Email, and More
|
Using an external project called Alertmanager
|
|
SDK support
|
Node js, Python, Go, .NET, Java, NestJS, and Typescript
|
Python, Ruby, Elixir, PHP, Swift, Go, Java, C, Spring, .Net, and JavaScript
|
GUI
RabbitMQ offers a native GUI that can act as a management layer as well.
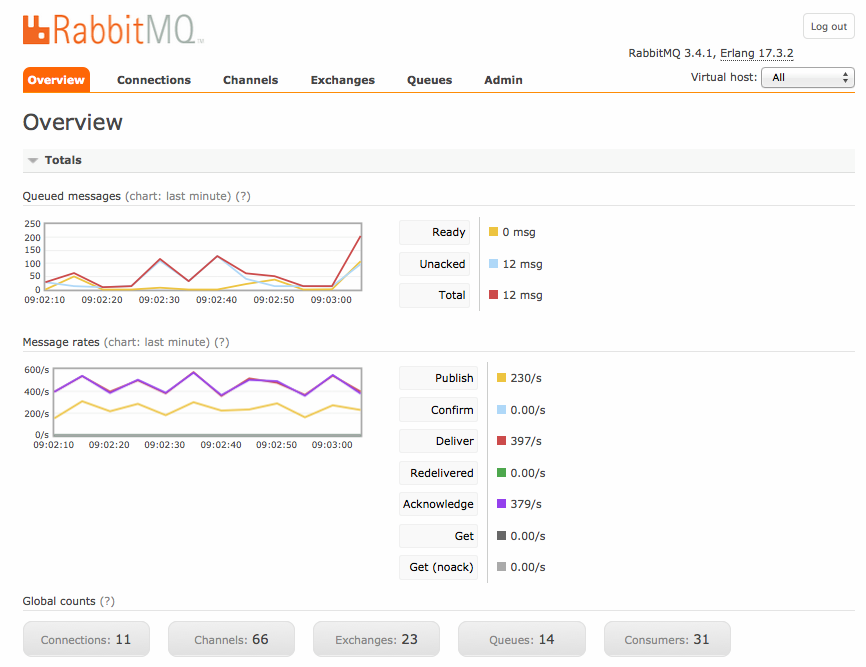
Memphis provides a native state-of-the-art GUI hosted inside the broker, built to act as a management layer of all Memphis aspects, including cluster config, resources, data observability, notifications, processing, and more.
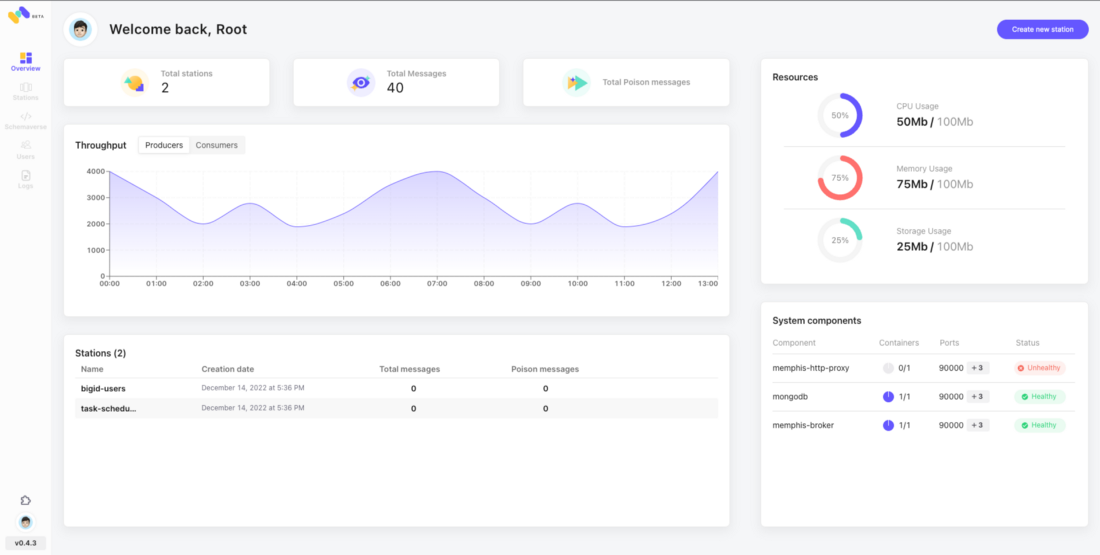
The very basic building block to control and ensure the quality of data that flows through your organization between the different owners is by defining well-written schemas and data models. The benefit of schema management is for allowing compatibility between decoupled clients.
As part of its open-source version, Memphis presents Schemaverse, which is also embedded within the broker. Schemaverse provides a robust schema store and schema management layer on top of Memphis broker without a standalone compute or dedicated resources. With a unique and modern UI and programmatic approach, technical and non-technical users can create and define different schemas, attach the schema to multiple stations and choose if the schema should be enforced or not. Furthermore, in counter to Schema Registry, the client does not need to implement serialization functions, and every schema update takes place during the producers’ runtime.
Wildcard Consume
The ability to consume messages from multiple queues using a single connection.
In RabbitMQ, Messages are not published directly to a queue. Instead, the producer sends messages to an exchange. Exchanges are message-routing agents defined by the virtual host within RabbitMQ. An exchange is responsible for routing the messages to different queues with the help of header attributes, bindings, and routing keys.
Memphis currently does not support it.
Stream Enrichment
The ability to decorate produced messages using serverless functions or SQL statements.
RabbitMQ does not support it.
Memphis provides a similar behavior to Kafka streams and more. Embedded inside the broker, Memphis users can create serverless-type functions or complete containerized applications that aggregate several stations and streams, decorate and enrich messages from different sources, write complex functions that cannot be achieved via SQL, and manipulate the schema. In addition, Memphis embedded connectors frameworks will help to push the results directly to a defined sink.
Ready-to-Use Source/Sinks Connectors
Memphis offers integrations compatible with NATS protocol, Memphis-based integrations, and ready-to-use connectors that can replace producers and consumers to and from different applications and databases made by the community, Memphis team, and third-party apps.
RabbitMQ does not support it.
Stream Lineage
Tracking stream lineage is the ability to understand the full path of a message from the very first producer through the final consumer, including the trail and evolvement of a message between topics. This ability is extremely handy in a troubleshooting process.
RabbitMQ does not offer stream lineage, but it can be achieved using OpenTelemetry or OpenLineage frameworks or integrating 3rd party applications such as Datadog and Epsagon.
Memphis provides stream lineage per message with out-of-the-box visualization for each stamped message using a generated header by the Memphis SDK.
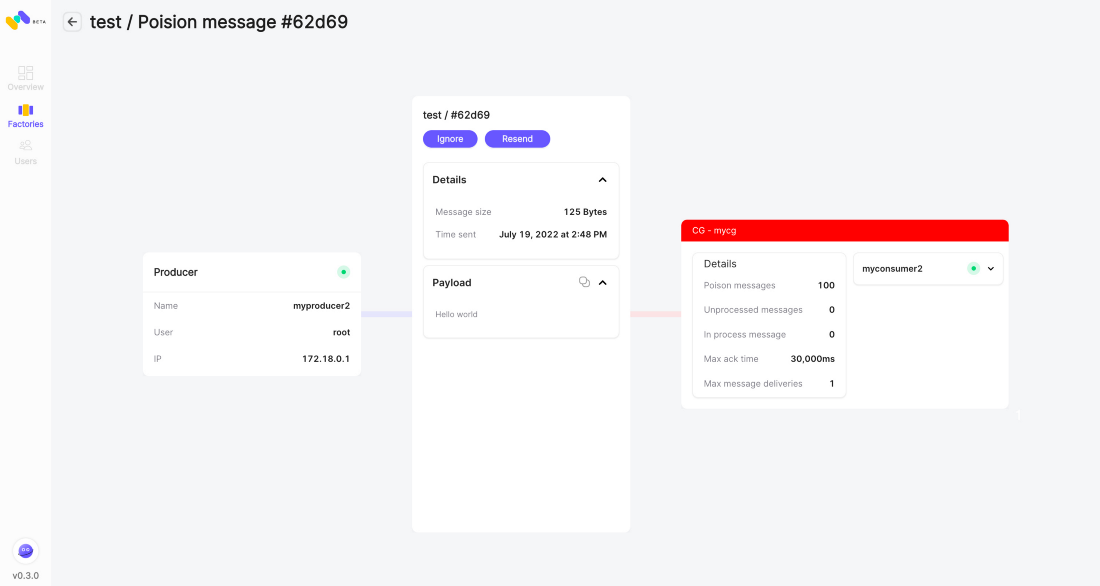
Self-Healing
RabbitMQ requires tune-ups, client-made wrappers, management, and tight monitoring. The user or operator is responsible for ensuring it’s alive and works as required. This approach has pros and cons, as the user can tune almost every parameter, which is often revealed as a significant burden.
One of Memphis’ core features is to remove frictions of management and autonomously make sure it’s alive and performing well using periodic self-checks and proactive rebalancing tasks, as well as fencing the users from misusing the system. In parallel, every aspect of the system can be configured on-the-fly without downtime.
Dead-Letter Queue
Dead-letter queue is both a concept and a solution that is useful for debugging clients because it lets you isolate and “recycle” instead of dropping unconsumed messages to determine why their processing doesn’t succeed.
In RabbitMQ, messages from a queue can be “dead-lettered”; that is, republished to exchange when any of the following events occur:
- The message is negatively acknowledged by a consumer using basic.reject or basic.nack with the requeue parameter set to false.
- The message expires due to per-message TTL.
- The message is dropped because its queue exceeded a length limit.
One of Memphis’ core building blocks is avoiding unexpected data loss, enabling rapid development, and shortening troubleshooting cycles. Therefore, Memphis provides a native solution for a dead letter that acts as the station recycle bin for various failures, such as unacknowledged messages, schema violations, and custom exceptions.
REST Gateway
To enable message production via HTTP calls for various use cases and ease of use, Memphis added an HTTP gateway to receive REST-based requests (=messages) and produce those messages to the required station.
RabbitMQ does not support it.
Consumer Internal Communication
In some use cases, especially around microservices and streaming pipelines, it is crucial for the different microservices to be able to communicate with each other to sync changes, the arrival of data, match data flow, etc.
Memphis is currently experimenting with creating that ability for consumers to be able to communicate with each other using gRPC or shared channels.
RabbitMQ does not support it.
Storage Tiering
Memphis offers a multi-tier storage strategy in its open-source version. Memphis will write messages that reached their end of 1st retention policy to a 2nd retention policy on object storage like S3 for longer retention time, potentially infinite, and post-streaming analysis. This feature can significantly help with cost reduction and stream auditing.
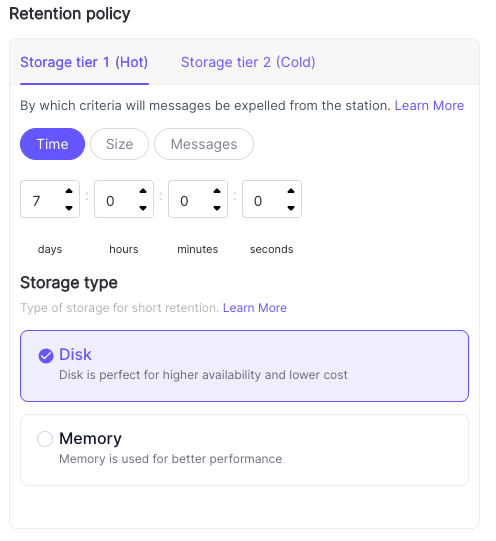
RabbitMQ does not support it.
Notifications
In RabbitMQ, notifications are made possible using AlertManager and Cluster operator, including slack notifications of different metrics like undelivered messages, resource issues, lags, performance, connection issues, and more.
Memphis has a built-in notification center that can push real-time alerts based on defined triggers like client disconnections, resource depletion, schema violation, etc.