How To Avoid AI Hallucinations With ChatGPT

Tage wrote about how to prevent ChatGPT from hallucinating a couple of months ago. However, I wanted to dive deeply into one specific thing you can do to completely avoid AI hallucinations. Before I explain how to avoid hallucinations, I need to explain a little bit about what we do when we create a custom ChatGPT chatbot.
What we do is prompt engineering based on an SQL database with VSS capabilities. It could be argued that we jailbreak ChatGPT, but instead of allowing ChatGPT to go completely berserk, we significantly restrict its capabilities to only be able to answer questions related to the data found in our SQL database. To understand the process, it helps to create your custom chatbot, something you can do below.
Our Website Scraper
If you look carefully at the process of creating a chatbot, you will see that it starts by crawling and scraping your website. Below is a screenshot that was created as we crawled HubSpot.
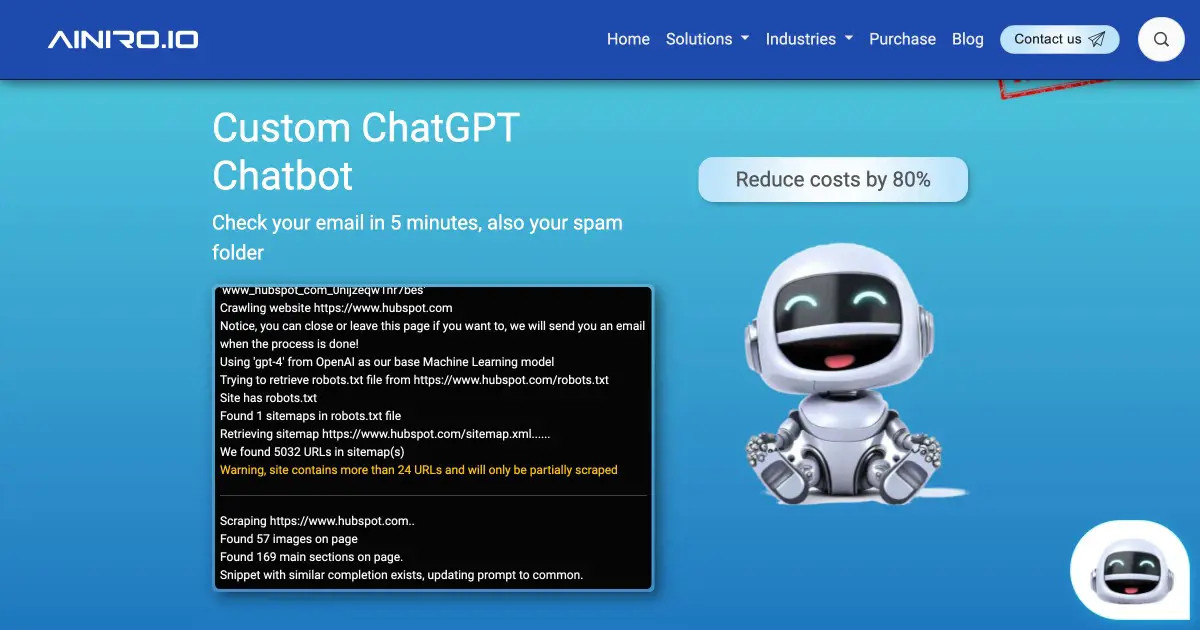
As it crawls your URL it chops up your website into "training snippets". This implies creating one training snippet for each image found on your pages, and one training snippet for each "section" it finds on your pages. One section is typically an Hx element, coupled with all paragraphs below it. Each of these snippets is then inserted into an SQL database. Read more about our scraper below.
- ChatGPT website scraper internals
Below is a screenshot from our Magic Dashboard showing one such training snippet. Notice, that the training snippet below is shown in "preview mode", but we also have raw mode where you can edit the content of each training snippet. Since training snippets are Markdown, this allows you to reference images, hyperlinks, and create lists, and such that becomes an integrated part of the chatbot experience.
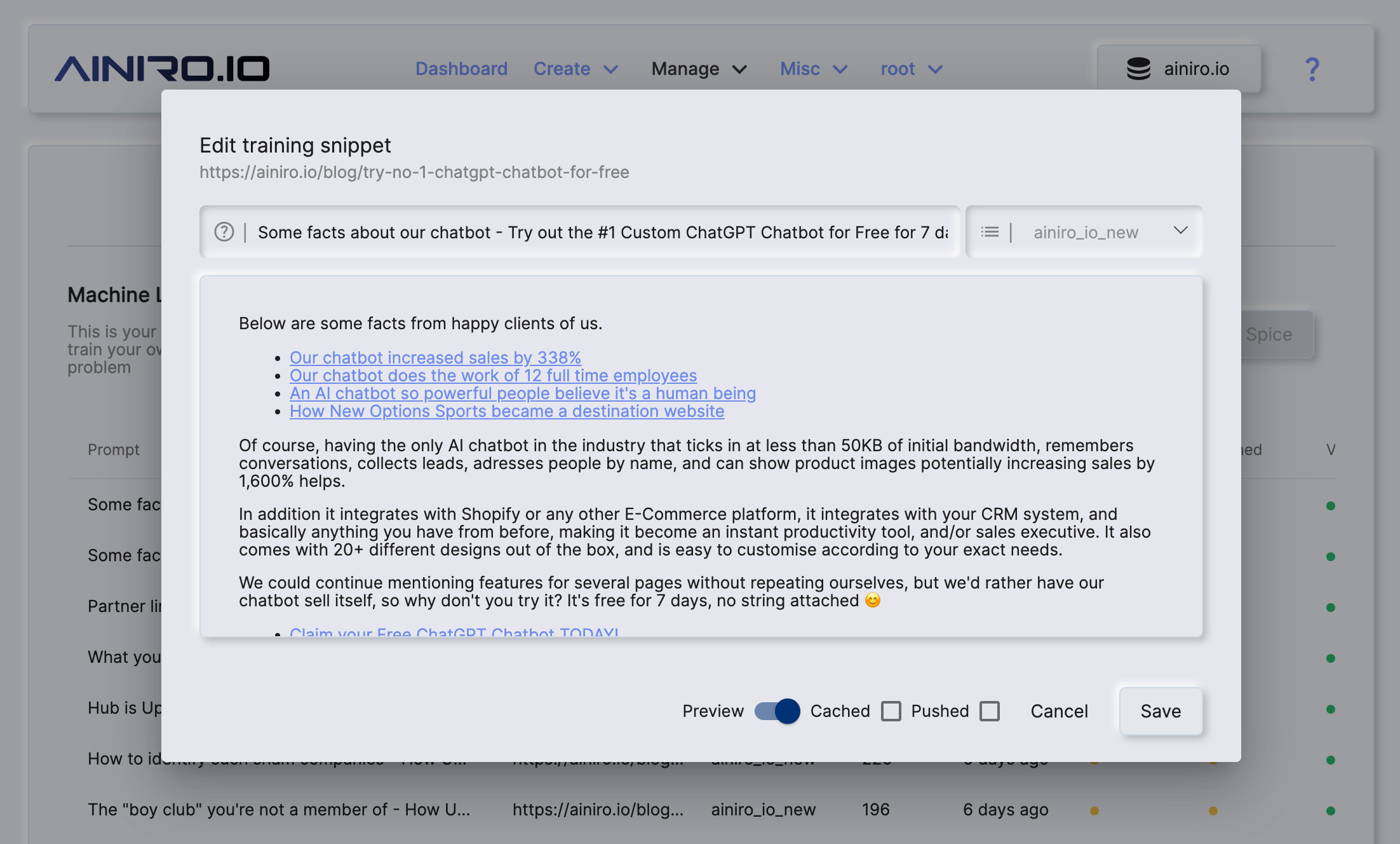
Notice, that when you create a free demo chatbot our crawler will only scrape a maximum of 25 pages. If you've got more pages it will simply ignore these and only scrape the 25 first pages ordered by the length of the URL. The latter tends to result in more important pages being prioritized since important pages typically have URLs such as "/about" while less important pages typically have much longer URLs.
VSS Database
When our crawler has scraped everything it will "vectorize" each of the training snippets it created during crawling and scraping. Vectorizing training snippets again is using OpenAI's embeddings API, creating a 1,520-dimensional vector describing the "trajectory" of each of these training snippets, which again can be used as we do an AI search through your VSS/SQL database later.
Later when the user phrases a question, we create a similar "vector" of the question, which allows us to calculate the "distance" between the question and each training snippet found in the SQL database as the backend tries to match questions towards your training data. Once we've got a vector for the question and one vector for each training snippet, the rest is just simple linear algebra, typically taught in high school or university. Most of the math behind this has been known since the days of Pythagoras...
This allows us to match your training snippets to questions asked, resulting in that we know that the training data we end up with is somehow related to the question the user asks. The matched training snippets again are concatenated into a single string, and sent to OpenAI, together with the question - While "instructing" ChatGPT to answer the specified question using nothing but the training snippets we provided. We refer to one such bulk of training snippets as "context", because it provides ChatGPT with the context required to answer the question it is being asked.
In fact, we don't ask ChatGPT to answer questions, we already know the answer. We simply ask ChatGPT to "transpile" the answer we already have into sentences and phrases that makes sense according to the question the user asks
I am 100% confident that there are multiple 42 jokes in the above section
How To Avoid AI Hallucinations
At this point, the experienced reader probably already knows how to avoid AI hallucinations without me even having to tell you, but it's as easy as adding an instruction to ChatGPT that says something resembling the following:
If you cannot find the answer to my question in the specified context, answer me; "I am sorry, but I don't know the answer, can you provide some keywords please?"
It's that easy. We simply politely tell ChatGPT to not answer unless the context which is created from our training data contains the answer. Something you can see from the screenshot below, where I ask our chatbot how to cook spaghetti. As you can see it refuses to answer me because our training data does not contain information related to cooking spaghetti.
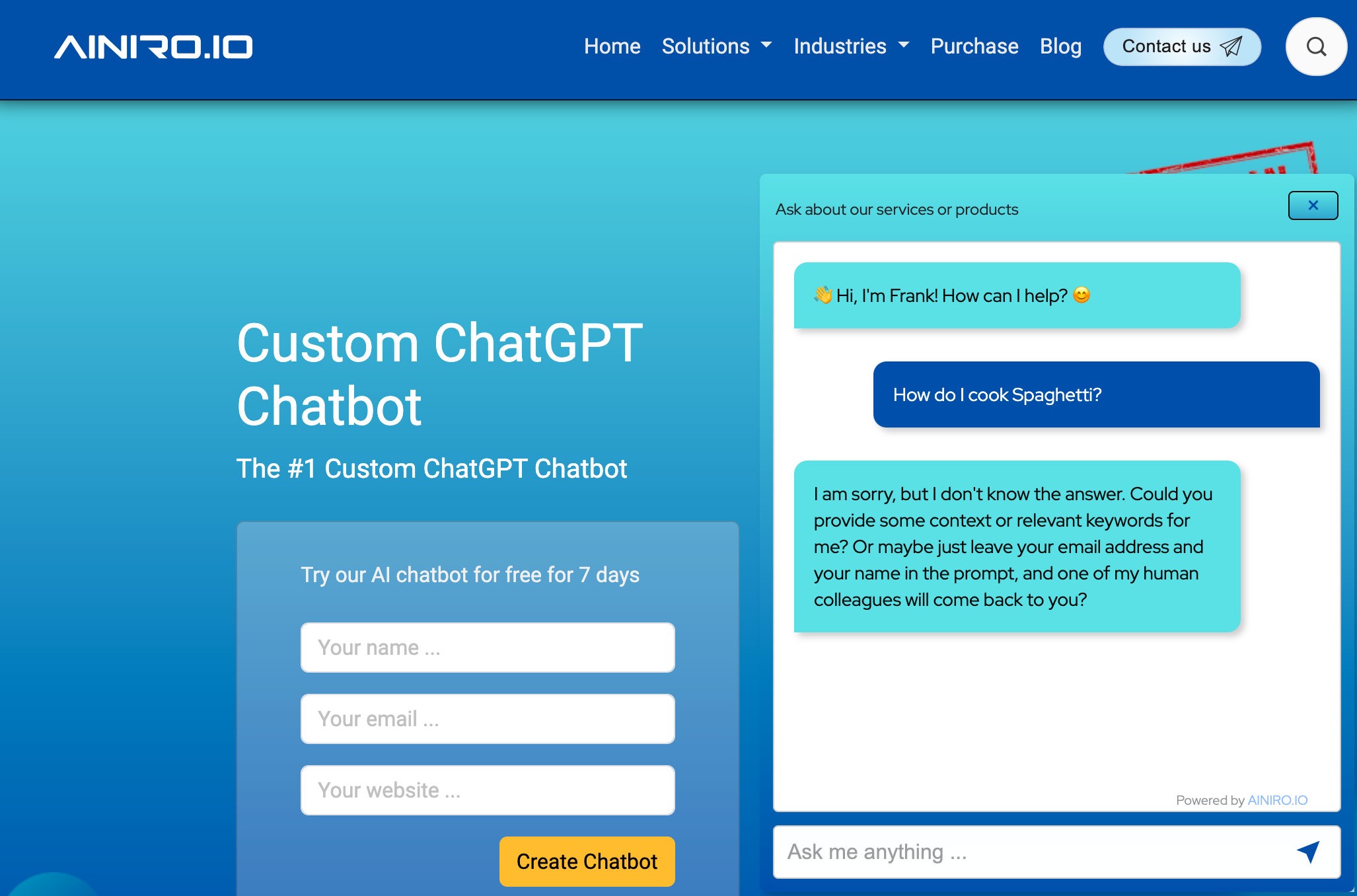
The point of the above is that if you asked ChatGPT about how to cook Spaghetti it would happily provide you with hundreds of different recipes. So basically it could be argued that our job is as follows.
We dumb down ChatGPT and teach it additional things, resulting in that it knows nothing outside of the scope of what we teach it.
This of course has the benefit of making ChatGPT know everything about whatever subject you want it to know something about, while knowing nothing about anything else. This eliminates AI hallucinations 100% perfectly, resulting in ChatGPT not hallucinating, not even in theory, regardless of what you ask it ...
Conclusion
To eliminate AI hallucinations you need the following:
- A VSS database with "training data"
- The ability to match questions towards your training snippets using OpenAI's embedding API
- Prompt engineer ChatGPT using instructions such that it refuses to answer unless the context provides the answer
And that's it. So when others tell me that "AI hallucinations are probably impossible to solve", I tend to laugh, regardless of who that person is. I've seen several interviews with Sam Altman for instance where he claims AI hallucinations cannot be fixed. Well, we fixed them, 6 months ago Sam ...
Sorry Sam, no hallucinations here
