Microservices and Traditional Middleware Platforms

Abstract
How is microservices different from traditional services deployed on middleware platforms (ESBs, application servers)? What is the microservices architecture pattern and what problems does it solve? This article will talk about all these important topics and describe how to administer, manage, and scale microservices.
Microservices Overview
Microservices is an architecture pattern that structures the application as a composition of loosely-coupled services that are not just logically separated, but are also physically separated at runtime. Microservices are lightweight autonomous components that are fine grained. It enables parallel development, testing and independent deployment. It enables continuous integration, delivery, and deployment. Each microservice can be scaled individually which brings efficient usage of compute and enables efficient and easy elastic scalability. It breaks the runtime monolithic architecture and prevents a single point of failure.
Microservices and SOA Architecture Styles
Most of the architecture principles of Service Oriented Architecture apply to MSA (Microservices Architecture). Microservices are still services but are not very coarse-grained and don't necessarily implement a broad business function. They are more fine-grained, lightweight, and perform a small unit of work. The principle of SOA is to expose coarse-grained business functions and aggregate entity attributes to form enterprise business objects. Microservices work on small entities and expose a service to operate that entity. No wonder most microservices are aligned to HTTP REST methods which allow entities to be created (POST), fetched (GET), modified (PUT) and deleted (DELETE).
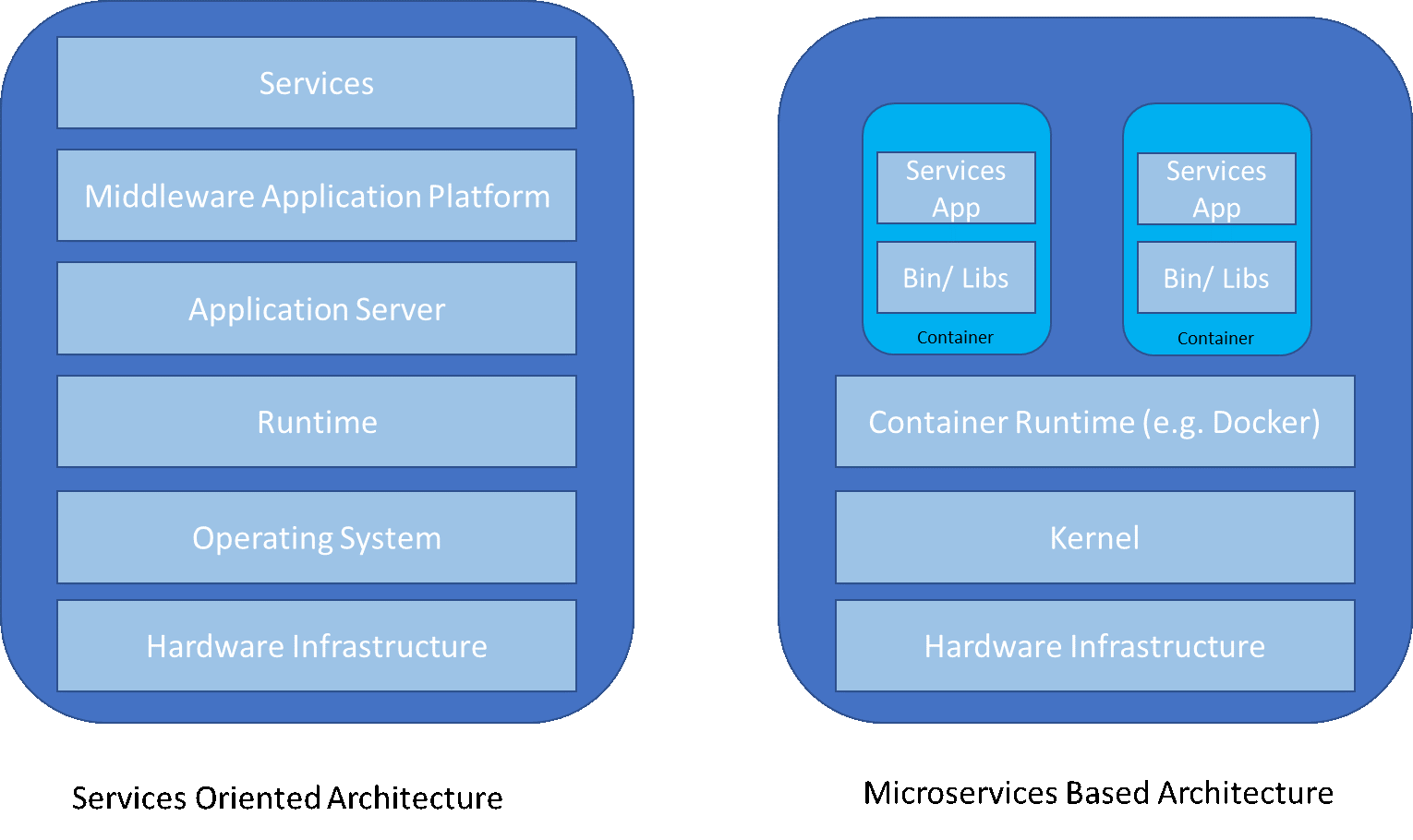
| Microservices Architecture (MSA) | SOA Architecture |
| Lightweight fine-grained services | Coarse-grained services |
| Doesn’t require an application server or centralized middleware platform for deployment | Services deployed on heavy centralized application servers/ middleware platforms. |
| Based on the principle that every microservice performs small units of work and hence doesn’t require complex middleware infrastructure. | Based on the principle that every service publishes a large business function and may require middleware services. |
| Ideal for request/ response services required to build web apps and mobile apps | Suitable for enterprise system integrations which require messaging based infrastructure |
| Services are autonomous at runtime. Every service has it’s own compute and storage and is not shared between services | All services are deployed on the central middleware platform and hence they all share the same compute and storage |
| Every service can be auto-scaled independent of the other by wrapping them into containers and scale them on demand. | Auto-scaling is not easy since the whole middleware platform will have to be replicated |
| Continuous delivery and deployment are at its core | Continuous delivery and deployment are not mainstream |
Can MSA and ESB Live Together?
ESBs are still here to stay along with microservices. Microservices are certainly going to get build more since they are easy to develop, cheaper to operate, and quick to deploy. Microservices are best suited when building an application that requires a set of APIs. It is also used to expose capabilities of modern enterprise applications that expose REST APIs and perform system-to-system synchronous communications. It is an important architecture pattern for cloud-based integrations, for example, mashing up APIs exposed by SAS platforms and provide more meaningful and easy to use services by encapsulating all the authentication and authorization handshakes within the microservice.
ESBs will continue to stay for traditional architectures and are still relevant for enterprise system integrations. Various reusable adapters for different enterprise systems accelerate development. It is still useful to use SOA implementations, long-running processes that require state machines and human workflow.
Operational View of Microservices
Deployment
Every microservice is deployed in a distributed fashion. A microservice can be wrapped into a container with all dependencies and can be deployed anywhere (on-prem, cloud and any operating system). Since the microservices contain all the runtime dependencies packaged together it eliminates runtime environment factors that cause deployment failures when deploying in different environments. It guarantees successful app deployment and hence decreases operational cost and brings confidence to the stakeholders due to stable applications. Deployments are truly repeatable and this is the reason why it can be replicated and auto-scaled to infinity.
What happens when a plethora of microservices are deployed? How do you manage and operate them? How do you allocate resources to them? How do you track them? How do you discover them? These are the questions that need to be answered when deploying a large number of microservices in production in a large enterprise. This is where you need software to orchestrate and manage the containers. The following sections will answer these questions.
Enter Kubernetes
Kubernetes is a leading container management open-source platform (Google open sourced it in 2014) that manages the deployment of containers, resource allocation of the containers, health check and monitoring, replication and auto-scaling of containers, abstraction of containers to expose it as a service and load balancing, service discovery, and much more.
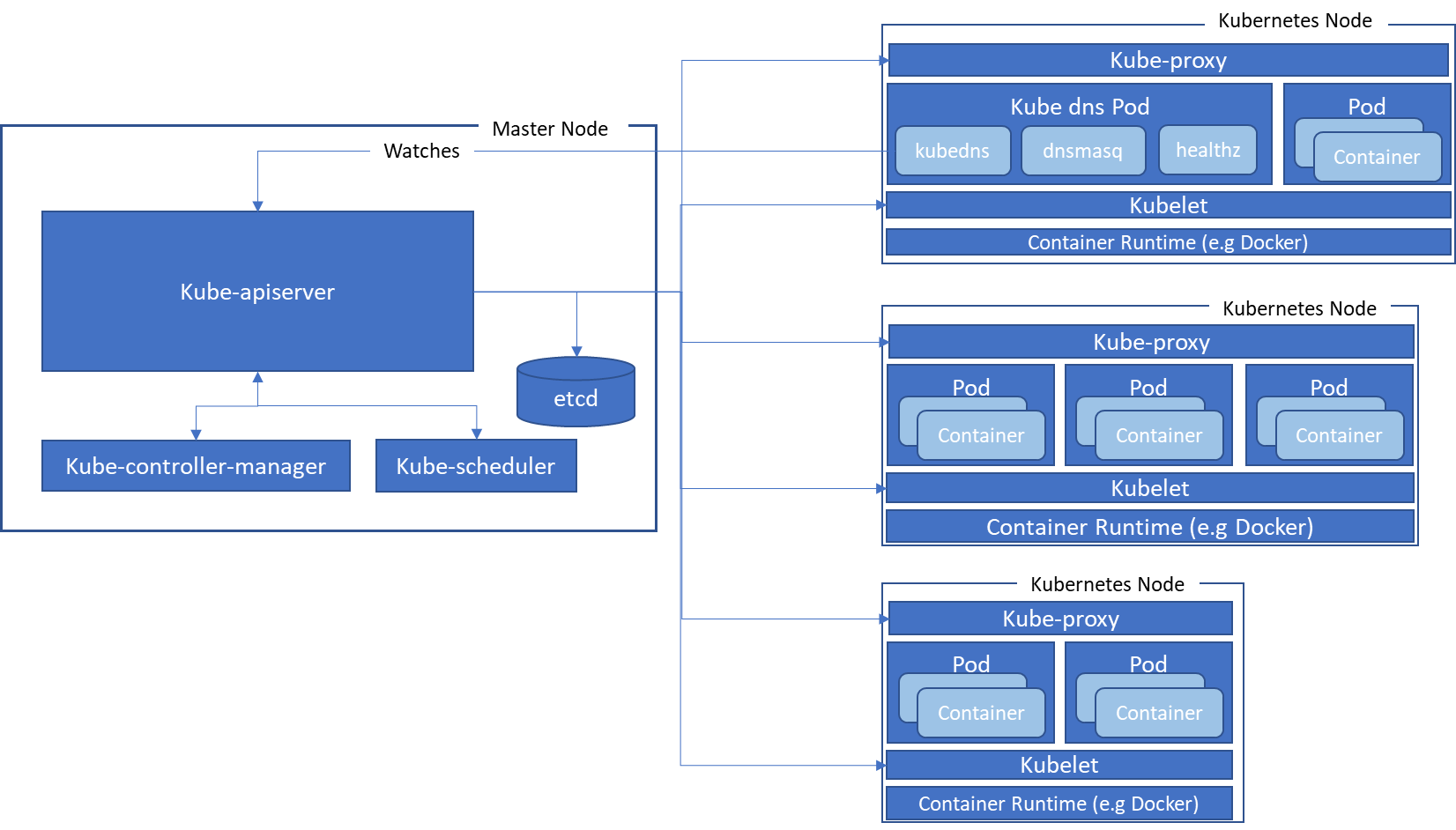
The master node is responsible for managing the Kubernetes cluster. It has several components that allow administration, monitoring, and controlling of the cluster state.
kube-apiserver
The API server exposes APIs to perform CRUD operations on cluster resources. It validates the requests, executes business logic residing in different components and persists the resulting state in etcd.
The API server is accessible outside of the cluster for clients to perform administrative tasks.
etcd
etcd is a distributed key value persistent store where all cluster states are persisted.
Kube-scheduler
The scheduler is responsible for watching unscheduled pods and binds them to run on specific nodes. It automatically schedules containers to run on specific nodes depending on resource and replication requirements. Scheduler knows the resources available on nodes and selects a node to run pods depending on the resource availability and resources required by the pod.
Kube-controller-manager
The controller manager is responsible for running various types of controllers. Controllers watch the current state of the cluster and take corrective action to bring the cluster to the desired state. Some examples of controllers are a Node Controller and Replication Controller. A Node Controller is responsible for monitoring the node and takes corrective action if a node goes down. Similarly, a replication controller monitors the number of pods running and schedules new pods to be created if some of them go down to achieve the defined replication state.
Kubelet
Kubelet is the agent running on every node of the cluster and implements the Pod and Node APIs for execution of containers. It is responsible for monitoring the containers and makes sure that they are running. It takes the Pod specs and executes containers as per the specs.
Kube-proxy
Kube-proxy is a component that enables service abstraction. It proxies the client requests and routes it to pods within the node to load balance the requests.
Pod
A pod is a basic unit of Kubernetes which is created and deployed. It wraps the application containers and runs them on a node. Pods are mutable objects which are created and destroyed. One Pod represents the single instance of an application. It can be replicated across nodes to provide high availability and elastic scalability.
When defining a pod, the allocation of compute resources can be specified for the containers.
Services
As pods can be created and destroyed, there needs to be a mechanism to access the application through one endpoint. Service is an abstraction that defines a logical set of Pods and routes client traffic to them. Pods can be created, destroyed, replicated to multiple nodes but clients can still access the backend Pods through services.
Kube DNS Pod
Kube DNS is a built-in service that is scheduled to run as a Pod in the cluster. Every service in the cluster is a given a DNS name. Services can be discovered by their DNS names.
Kube DNS Pod runs three containers within it – kubedns, dnsmasdq, and healthz. Kubedns keeps watching the Kubernetes master for changes to services and maintains the in-memory lookup to service DNS requests. Dnsmasdq adds caching to improve performance while healthz monitors the health of kubedns and dnsmasdq.
Auto Scaling
The Pods can be auto-scaled by the Horizontal Pod Autoscaler. The Horizontal Pod Autoscaler continuously monitors the average resource utilization against the metrics defined in the autoscaler and either replicates more Pods or removes Pods, depending on the situation.
Kubernetes as Managed Services
Kubernetes is available as a managed service on AWS, Azure, and Google Cloud if you don’t want to set up and manage your own Kubernetes cluster.
Other Deployment Options
Docker Swarm
Kubernetes has a lot of distributed components and it takes time to set it up and get going, but is open-source and has a large community for support. Kubernetes is feature-rich and a good solution to manage a medium to large cluster. Docker Swarm is another option which is easier to set up with limited features. It integrates well with Docker and has lightweight installation.
No Containers
There are other simpler options to realize microservices architecture if you don’t want to go down the path of containerization and its orchestration. If the scalability requirements are not internet scale and there are limited entities to be managed per app, then you could build one microservice per resource or one microservice for logically grouped resources (e.g. OrderManagement API, Product API, Login API) and deploy them as separate Spring Boot apps (or Node.js apps). Replicate these stateless apps for scalability and availability onto couple of nodes and monitor these individual processes separately. The drawback of this approach is that there is no way to confine compute resources (except memory) per app but you could club APIs with similar NFRs and deploy them on the same node. By doing this you could still achieve elastic scalability by replicating the VMs if the demand increases or decreases. Remember this is not truly microservices since all app dependencies are not packaged and replicated together. This approach does provide the benefits of having a leaner stack to deploy and manage the services layer.
No Container Orchestration Platform
The other variation of the above option is to containerize the apps but not use container orchestration platforms. The only drawback of this option is that you will have to manage the containers manually. You can still auto-scale and replicate with confidence. Docker containers can be monitored by system management tools like New Relic, Logic Controller, etc.
Security
As you might have already observed, with MSA, you will have to open a network port for every microservice that needs to be accessed outside of the organization’s network. This means too many opened ports, which increases the attack surface. You should proxy your microservices via a reverse proxy or use an API Gateway layer. This way, you can shield you microservices from being exposed to the public network and they can safely stay behind the enterprise firewall.
Conclusion
Microservices certainly have a lot of advantages over traditional middleware platforms. The ecosystem to deploy and manage microservices is robust. Traditional middleware platforms are being marginalized to support existing and limited use cases. It is an exciting time to develop and deploy these little microservices and see them auto-scale to meet challenging scalability requirements.
