The Secret to High-Availability System for the Cloud

What Is a Highly-Available System?
You call a system highly available when it can remain operational and accessible even when there are hardware and software failures. The idea is to ensure continuous service. We all want our system to be highly-available. It seems like a good thing to have and makes for a nice bullet point in our application description. But designing a high-availability system is not an easy task.
So, how can you go about it?
The most reliable approach is to leverage the concept of static stability. But before we get to the meaning of this term, it’s important to understand the concept of availability zones.
What Are Availability Zones?
You must have heard about availability zones in AWS or other cloud platforms. If not, here’s a quick definition of the term from the context of AWS:
Availability Zones are isolated sections of an AWS region. They are physically separated from each other by a meaningful distance so that a single event cannot impair them all at once.
For perspective, this single event could be a lightning strike, tornado, or even an earthquake.
The Godzilla attack makes it really clear that building an availability zone is not trivial engineering. To achieve this incredible level of separation, availability zones don’t share power or other infrastructure.
However, they are connected with fast and encrypted fiber-optic networking so that application failover can be smooth as butter. This means that in the case of a catastrophic hardware or software failure, the workloads can be quickly and seamlessly transferred to another server without loss of data or interruption of service.
Moreover, the use of encryption ensures that sensitive data transmitted across the network status secure from any type of unauthorized access. Here’s a picture showing the AWS Global Infrastructure from a few years ago.
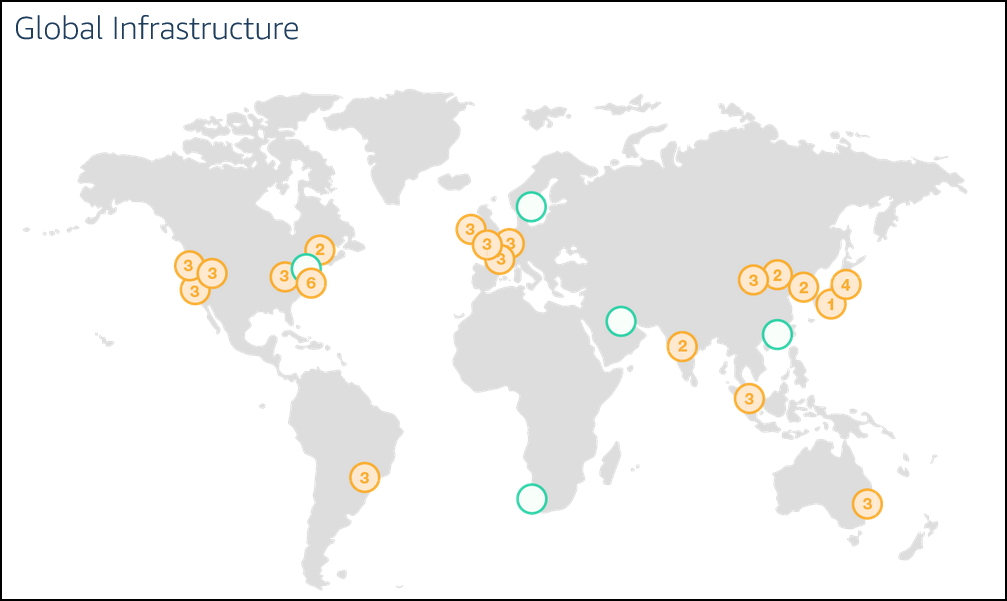
AWS Global Infra (source: AWS Website)
The orange circles denote a region and the number within those circles is the number of availability zones within that region.
What's Static Stability?
Let's get back to our key term: static stability.
Availability zones let you build systems with high availability. But, you can go about it in two ways:
- Reactive
- Proactive
In a reactive approach, you let the service scale up in another availability zone after there is some sort of disruption in one of the zones. You might use something like AWS Autoscaling Group to manage the scale-up automatically. But the idea is that you react to the impairments when they happen rather than being prepared in advance.
In a proactive approach, you over-provision the infrastructure in a way that your system continues to operate satisfactorily even in the case of disruption within a particular Availability Zone. The proactive approach ensures that your service is statically stable.
A lot of AWS services use static stability as a guiding principle. Some of the most popular ones are:
- AWS EC2
- AWS RDS
- AWS S3
- AWS DynamoDB
- AWS ElastiCache
If your system is statically stable, it keeps working even when a dependency becomes impaired.
For example, the AWS EC2 service supports static stability by targeting high availability for its data plane (the one that manages existing EC2 instances). This means that once launched, an EC2 instance has local access to all the information it needs to route packets.
The main benefit of this approach is that instances can operate independently and maintain their own local state even in the case of a network or service disruption. However, leveraging static stability is not just for the cloud provider. You can also use static stability while designing your own applications for the cloud.
Let’s look at a couple of patterns that use the concept of static stability.
Pattern 1: Active-Active High-Availability Using AZs
Here’s an example of how you can implement a load-balanced HTTP service.
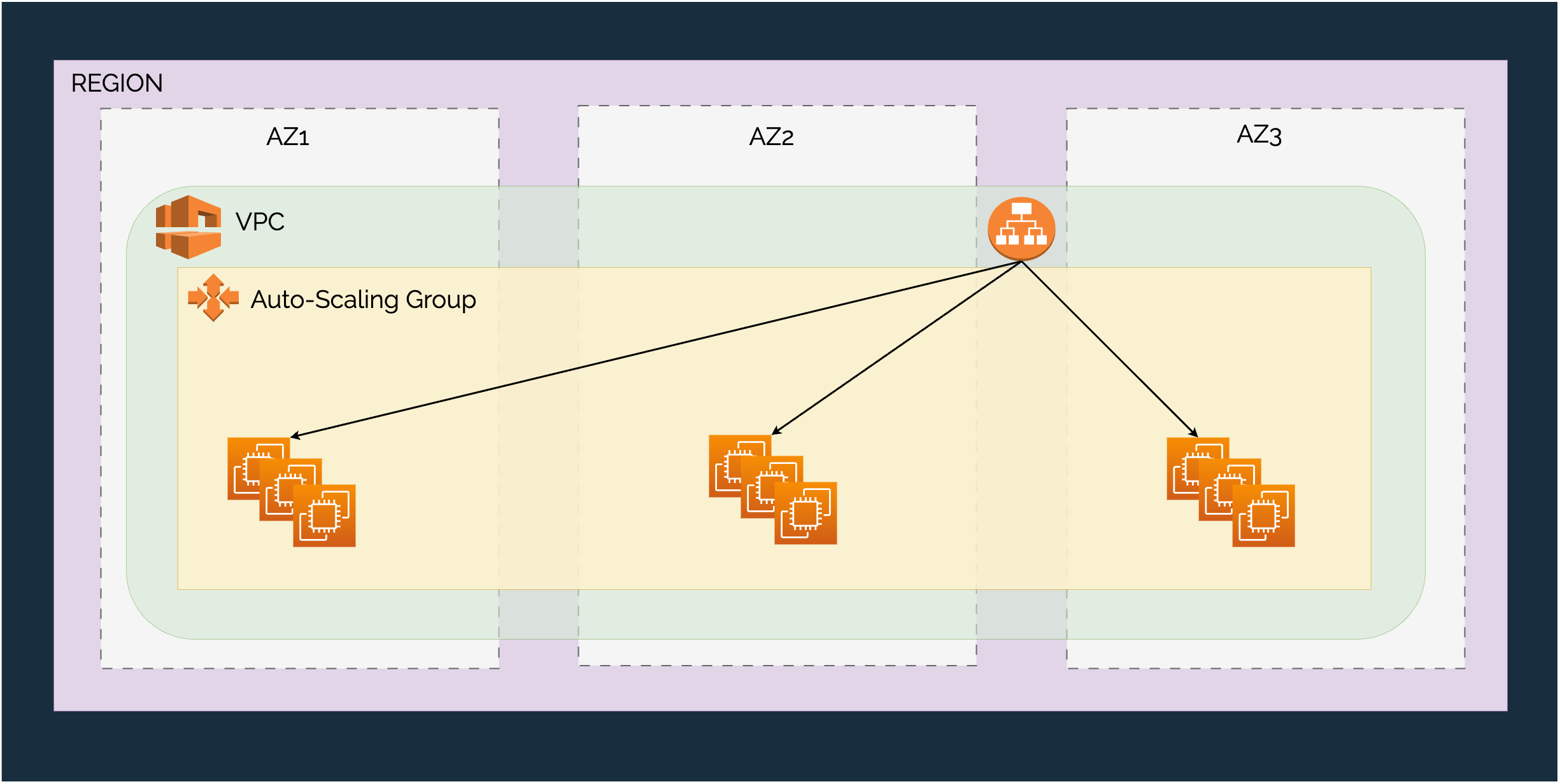
Active-Active High-Availability with AZs
You have a public-facing load balancer targeting an auto scaling group that spans three availability zones in a particular Region. Also, you make sure to over-provision capacity by 50%. If an AZ goes down for whatever reason, you don’t need to do much to support the system. The EC2 instances within the problematic AZ will start failing health checks and the load balancer will shift traffic away from them.
This is an important mechanism since constant monitoring helps the load balancer quickly identify any instances that are experiencing issues and work on the appropriate fallback without human intervention. Since the setup is statically stable, it will continue to remain operational without hiccups.
Pattern 2: Active-Standby on Availability Zones
The previous pattern dealt with stateless services. However, you might also need to implement high availability for a stateful service. A prime example is a database system such as Amazon RDS.
A typical high-availability setup for this requirement needs a primary instance that takes all the writes and a standby instance. The standby instance will be kept in a different availability zone. Here’s what it looks like:
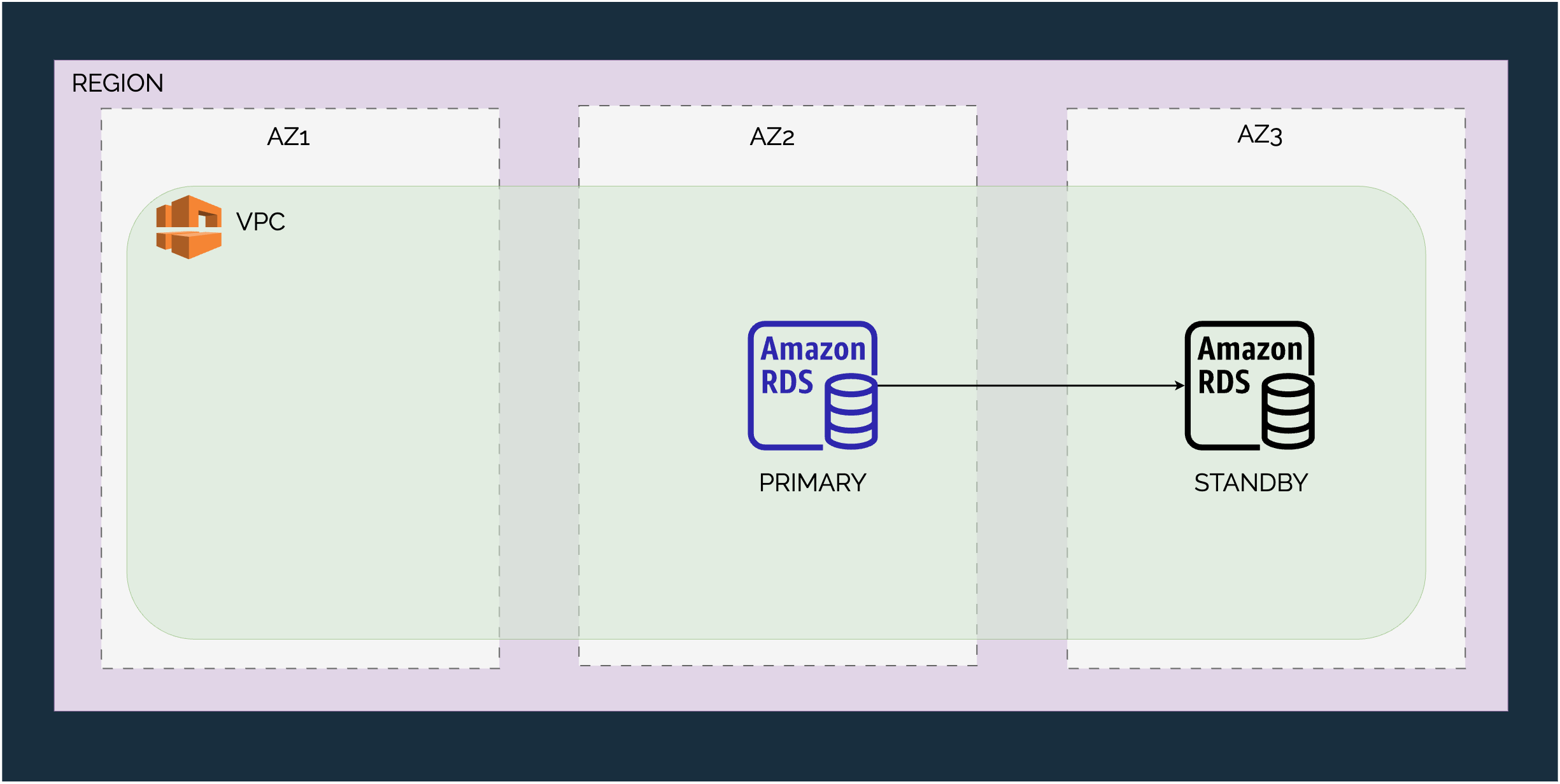
Active-Standby High Availability with AZs
When the primary AZ goes down for whatever reason, RDS manages the failover to the new primary (the standby instance). Again, since we have already over-provisioned, there is no need to create new instances. The switchover can happen seamlessly without impacting the availability.
In essence, the service is statically stable.
So, What’s the Takeaway?
In both patterns, you already provisioned the capacity needed in case of an availability zone goes down. In either case, you are not trying to create new instances on the fly since you have already over-provisioned the infrastructure across AZs. This means your systems are statically stable and can easily survive outages or disruptions. In other words, your system is highly-available in a proactive manner which is an extremely good characteristic to have.
Over to You
- Does high availability matter to you?
- If yes, how do you handle it within your applications? What techniques do you use?
Write your replies in the comments section.
The inspiration for this post came from this wonderful paper released as part of the Amazon Builders Library. You can check it out in case you are interested in going deeper into the theoretical foundations of static stability.
If you found today’s post useful, consider sharing it with friends and colleagues.
