Convert Your Code From Jupyter Notebooks To Automated Data and ML Pipelines Using AWS

A typical machine learning (ML) workflow involves processes such as data extraction, data preprocessing, feature engineering, model training and evaluation, and model deployment. As data changes over time, when you deploy models to production, you want your model to learn continually from the stream of data. This means supporting the model’s ability to autonomously learn and adapt in production as new data is added.
In practice, data scientists often work with Jupyter Notebooks for development work and find it hard to translate from notebooks to automated pipelines. To achieve the two main functions of an ML service in production, namely retraining (retrain the model on newer labeled data) and inference (use the trained model to get predictions), you might primarily use the following:
- Amazon SageMaker: A fully managed service that provides developers and data scientists the ability to build, train, and deploy ML models quickly
- AWS Glue: A fully managed extract, transform, and load (ETL) service that makes it easy to prepare and load data
In this post, we demonstrate how to orchestrate an ML training pipeline using AWS Glue workflows and train and deploy the models using Amazon SageMaker. For this use case, you use AWS Glue workflows to build an end-to-end ML training pipeline that covers data extraction, data processing, training, and deploying models to Amazon SageMaker endpoints.
Use Case
For this use case, we use the DBpedia Ontology classification dataset to build a model that performs multi-class classification. We trained the model using the BlazingText algorithm, which is a built-in Amazon SageMaker algorithm that can classify unstructured text data into multiple classes.
This post doesn’t go into the details of the model but demonstrates a way to build an ML pipeline that builds and deploys any ML model.
Solution Overview
The following diagram summarizes the approach for the retraining pipeline. 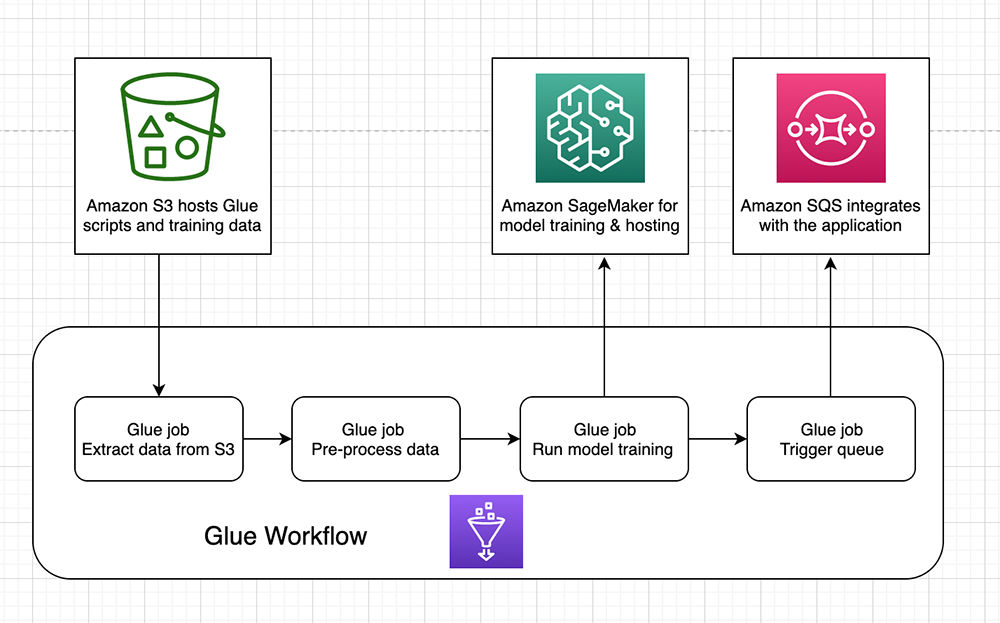
The workflow contains the following elements:
- AWS Glue crawler: You can use a crawler to populate the Data Catalog with tables. This is the primary method used by most AWS Glue users. A crawler can crawl multiple data stores in a single run. Upon completion, the crawler creates or updates one or more tables in your Data Catalog. ETL jobs that you define in AWS Glue use these Data Catalog tables as sources and targets.
- AWS Glue triggers: Triggers are Data Catalog objects that you can use to either manually or automatically start one or more crawlers or ETL jobs. You can design a chain of dependent jobs and crawlers by using triggers.
- AWS Glue job: An AWS Glue job encapsulates a script that connects source data, processes it, and writes it to a target location.
- AWS Glue workflow: An AWS Glue workflow can chain together AWS Glue jobs, data crawlers, and triggers, and build dependencies between the components. When the workflow is triggered, it follows the chain of operations as described in the preceding image.
The workflow begins by downloading the training data from Amazon Simple Storage Service (Amazon S3), followed by running data preprocessing steps and dividing the data into train, test, and validate sets in AWS Glue jobs. The training job runs on a Python shell running in AWS Glue jobs, which starts a training job in Amazon SageMaker based on a set of hyperparameters.
When the training job is complete, an endpoint is created, which is hosted on Amazon SageMaker. This job in AWS Glue takes a few minutes to complete because it makes sure that the endpoint is in InService status.
At the end of the workflow, a message is sent to an Amazon Simple Queue Service (Amazon SQS) queue, which you can use to integrate with the rest of the application. You can also use the queue to trigger an action to send emails to data scientists that signal the completion of training, add records to management or log tables, and more.
Setting up the Environment
To set up the environment, complete the following steps:
- Configure the AWS Command Line Interface (AWS CLI) and a profile to use to run the code. For instructions, see Configuring the AWS CLI.
- Make sure you have the Unix utility wget installed on your machine to download the
DBpediadataset from the internet. - Download the following code into your local directory.
Organization of Code
The code to build the pipeline has the following directory structure:
--Glue workflow orchestration
--glue_scripts
--DataExtractionJob.py
--DataProcessingJob.py
--MessagingQueueJob,py
--TrainingJob.py
--base_resources.template
--deploy.sh
--glue_resources.templateThe code directory is divided into three parts:
- AWS CloudFormation templates: The directory has two AWS CloudFormation templates:
glue_resources.templateandbase_resources.template. Theglue_resources.templatetemplate creates the AWS Glue workflow-related resources, andbase_resources.templatecreates the Amazon S3, AWS Identity and Access Management (IAM), and SQS queue resources. The CloudFormation templates create the resources and write their names and ARNs to AWS Systems Manager Parameter Store, which allows easy and secure access to ARNs further in the workflow. - AWS Glue scripts: The folder
glue_scriptsholds the scripts that correspond to each AWS Glue job. This includes the ETL as well as model training and deploying scripts. The scripts are copied to the correct S3 bucket when the bash script runs. - Bash script: A wrapper script
deploy.shis the entry point to running the pipeline. It runs the CloudFormation templates and creates resources in the dev, test, and prod environments. You use the environment name, also referred to asstagein the script, as a prefix to the resource names. The bash script performs other tasks, such as downloading the training data and copying the scripts to their respective S3 buckets. However, in a real-world use case, you can extract the training data from databases as a part of the workflow using crawlers.
Implementing the Solution
Complete the following steps:
- Go to the
deploy.shfile and replacealgorithm_imagename with <ecr_path> based on your Region.
The following code example is a path for Region us-west-2:
algorithm_image="433757028032.dkr.ecr.us-west-2.amazonaws.com/blazingtext:latest"
For more information about BlazingText parameters, see Common parameters for built-in algorithms.
- Enter the following code in your terminal:
Shell
sh deploy.sh -s dev AWS_PROFILE=your_profile_nameThis step sets up the infrastructure of the pipeline.
- On the AWS CloudFormation console, check that the templates have the status
CREATE_COMPLETE. - On the AWS Glue console, manually start the pipeline.
In a production scenario, you can trigger this manually through a UI or automate it by scheduling the workflow to run at the prescribed time. The workflow provides a visual of the chain of operations and the dependencies between the jobs.
- To begin the workflow, in the Workflow section, select DevMLWorkflow.
- From the Actions drop-down menu, choose Run.
- View the progress of your workflow on the History tab and select the latest RUN ID.
The workflow takes approximately 30 minutes to complete. The following screenshot shows the view of the workflow post-completion.
- After the workflow is successful, open the Amazon SageMaker console.
- Under Inference, choose Endpoint.
The following screenshot shows that the endpoint of the workflow deployed is ready.
Amazon SageMaker also provides details about the model metrics calculated on the validation set in the training job window. You can further enhance model evaluation by invoking the endpoint using a test set and calculating the metrics as necessary for the application.
Cleaning Up
Make sure to delete the Amazon SageMaker hosting services—endpoints, endpoint configurations, and model artifacts. Delete both CloudFormation stacks to roll back all other resources. See the following code:
def delete_resources(self):
endpoint_name = self.endpoint
try:
sagemaker.delete_endpoint(EndpointName=endpoint_name)
print("Deleted Test Endpoint ", endpoint_name)
except Exception as e:
print('Model endpoint deletion failed')
try:
sagemaker.delete_endpoint_config(EndpointConfigName=endpoint_name)
print("Deleted Test Endpoint Configuration ", endpoint_name)
except Exception as e:
print(' Endpoint config deletion failed')
try:
sagemaker.delete_model(ModelName=endpoint_name)
print("Deleted Test Endpoint Model ", endpoint_name)
except Exception as e:
print('Model deletion failed')This post describes a way to build an automated ML pipeline that not only trains and deploys ML models using a managed service such as Amazon SageMaker, but also performs ETL within a managed service such as AWS Glue. A managed service unburdens you from allocating and managing resources, such as Spark clusters, and makes it easy to move from notebook setups to production pipelines.
