Optimizing Container Synchronization for Frequent Writes

Efficient data synchronization is crucial in high-performance computing and multi-threaded applications. This article explores an optimization technique for scenarios where frequent writes to a container occur in a multi-threaded environment. We’ll examine the challenges of traditional synchronization methods and present an advanced approach that significantly improves performance for write-heavy environments. The method in question is beneficial because it is easy to implement and versatile, unlike pre-optimized containers that may be platform-specific, require special data types, or bring additional library dependencies.
Traditional Approaches and Their Limitations
Imagine a scenario where we have a cache of user transactions:
struct TransactionData
{
long transactionId;
long userId;
unsigned long date;
double amount;
int type;
std::string description;
};
std::map<long, std::vector<TransactionData>> transactionCache; // key - userId
In a multi-threaded environment, we need to synchronize access to this cache. The traditional approach might involve using a mutex:
class SimpleSynchronizedCache
{
public:
void write(const TransactionData&& transaction)
{
std::lock_guard<std::mutex> lock(cacheMutex);
transactionCache[transaction.userId].push_back(transaction);
}
std::vector<TransactionData> read(const long&& userId)
{
std::lock_guard<std::mutex> lock(cacheMutex);
try
{
return transactionCache.at(userId);
}
catch (const std::out_of_range& ex)
{
return std::vector<TransactionData>();
}
}
std::vector<TransactionData> pop(const long& userId)
{
std::lock_guard<std::mutex> lock(_cacheMutex);
auto userNode = _transactionCache.extract(userId);
return userNode.empty() ? std::vector<TransactionData>() : std::move(userNode.mapped());
}
private:
std::map<int, std::vector<TransactionData>> transactionCache;
std::mutex cacheMutex;
};
As system load increases, especially with frequent reads, we might consider using a shared_mutex:
class CacheWithSharedMutex
{
public:
void write(const TransactionData&& transaction)
{
std::lock_guard<std::shared_mutex> lock(cacheMutex);
transactionCache[transaction.userId].push_back(transaction);
}
std::vector<TransactionData> read(const long&& userId)
{
std::shared_lock<std::shared_mutex> lock(cacheMutex);
try
{
return transactionCache.at(userId);
}
catch (const std::out_of_range& ex)
{
return std::vector<TransactionData>();
}
}
std::vector<TransactionData> pop(const long& userId)
{
std::lock_guard<std::shared_mutex> lock(_cacheMutex);
auto userNode = _transactionCache.extract(userId);
return userNode.empty() ? std::vector<TransactionData>() : std::move(userNode.mapped());
}
private:
std::map<int, std::vector<TransactionData>> transactionCache;
std::shared_mutex cacheMutex;
};
However, when the load is primarily generated by writes rather than reads, the advantage of a shared_mutex over a regular mutex becomes minimal. The lock will often be acquired exclusively, negating the benefits of shared access.
Moreover, let’s imagine that we don’t use read() at all — instead, we frequently write incoming transactions and periodically flush the accumulated transaction vectors using pop(). As pop() involves reading with extraction, both write() and pop() operations would modify the cache, necessitating exclusive access rather than shared access. Thus, the shared_lock becomes entirely useless in terms of optimization over a regular mutex, and maybe even performs worse — its more intricate implementation is now used for the same exclusive locks that a faster regular mutex provides. Clearly, we need something else.
Optimizing Synchronization With the Sharding Approach
Given the following conditions:
- A multi-threaded environment with a shared container
- Frequent modification of the container from different threads
- Objects in the container can be divided for parallel processing by some member variable.
Regarding point 3, in our cache, transactions from different users can be processed independently. While creating a mutex for each user might seem ideal, it would lead to excessive overhead in maintaining so many locks. Instead, we can divide our cache into a fixed number of chunks based on the user ID, in a process known as sharding. This approach reduces the overhead and yet allows the parallel processing, thereby optimizing performance in a multi-threaded environment.
class ShardedCache
{
public:
ShardedCache(size_t shardSize):
_shardSize(shardSize),
_transactionCaches(shardSize)
{
std::generate(
_transactionCaches.begin(),
_transactionCaches.end(),
[]() { return std::make_unique<SimpleSynchronizedCache>(); });
}
void write(const TransactionData& transaction)
{
_transactionCaches[transaction.userId % _shardSize]->write(transaction);
}
std::vector<TransactionData> read(const long& userId)
{
_transactionCaches[userId % _shardSize]->read(userId);
}
std::vector<TransactionData> pop(const long& userId)
{
return std::move(_transactionCaches[userId % _shardSize]->pop(userId));
}
private:
const size_t _shardSize;
std::vector<std::unique_ptr<SimpleSynchronizedCache>> _transactionCaches;
};
This approach allows for finer-grained locking without the overhead of maintaining an excessive number of mutexes. The division can be adjusted based on system architecture specifics, such as size of a thread pool that works with the cache, or hardware concurrency.
Let’s run tests where we check how sharding accelerates cache performance by testing different partition sizes.
Performance Comparison
In these tests, we aim to do more than just measure the maximum number of operations the processor can handle. We want to observe how the cache behaves under conditions that closely resemble real-world scenarios, where transactions occur randomly. Our optimization goal is to minimize the processing time for these transactions, which enhances system responsiveness in practical applications.
The implementation and tests are available in the GitHub repository.
#include <thread>
#include <functional>
#include <condition_variable>
#include <random>
#include <chrono>
#include <iostream>
#include <fstream>
#include <array>
#include "SynchronizedContainers.h"
const auto hardware_concurrency = (size_t)std::thread::hardware_concurrency();
class TaskPool
{
public:
template <typename Callable>
TaskPool(size_t poolSize, Callable task)
{
for (auto i = 0; i < poolSize; ++i)
{
_workers.emplace_back(task);
}
}
~TaskPool()
{
for (auto& worker : _workers)
{
if (worker.joinable())
worker.join();
}
}
private:
std::vector<std::thread> _workers;
};
template <typename CacheImpl>
class Test
{
public:
template <typename CacheImpl = ShardedCache, typename ... CacheArgs>
Test(const int testrunsNum, const size_t writeWorkersNum, const size_t popWorkersNum,
const std::string& resultsFile, CacheArgs&& ... cacheArgs) :
_cache(std::forward<CacheArgs>(cacheArgs)...),
_writeWorkersNum(writeWorkersNum), _popWorkersNum(popWorkersNum),
_resultsFile(resultsFile),
_testrunsNum(testrunsNum), _testStarted (false)
{
std::random_device rd;
_randomGenerator = std::mt19937(rd());
}
void run()
{
for (auto i = 0; i < _testrunsNum; ++i)
{
runSingleTest();
logResults();
}
}
private:
void runSingleTest()
{
{
std::lock_guard<std::mutex> lock(_testStartSync);
_testStarted = false;
}
// these pools won’t just fire as many operations as they can,
// but will emulate real-time occuring requests to the cache in multithreaded environment
auto writeTestPool = TaskPool(_writeWorkersNum, std::bind(&Test::writeTransactions, this));
auto popTestPool = TaskPool(_popWorkersNum, std::bind(&Test::popTransactions, this));
_writeTime = 0;
_writeOpNum = 0;
_popTime = 0;
_popOpNum = 0;
{
std::lock_guard<std::mutex> lock(_testStartSync);
_testStarted = true;
_testStartCv.notify_all();
}
}
void logResults()
{
std::cout << "===============================================" << std::endl;
std::cout << "Writing operations number per sec:\t" << _writeOpNum / 60. << std::endl;
std::cout << "Writing operations avg time (mcsec):\t" << (double)_writeTime / _writeOpNum << std::endl;
std::cout << "Pop operations number per sec: \t" << _popOpNum / 60. << std::endl;
std::cout << "Pop operations avg time (mcsec): \t" << (double)_popTime / _popOpNum << std::endl;
std::ofstream resultsFilestream;
resultsFilestream.open(_resultsFile, std::ios_base::app);
resultsFilestream << _writeOpNum / 60. << "," << (double)_writeTime / _writeOpNum << ","
<< _popOpNum / 60. << "," << (double)_popTime / _popOpNum << std::endl;
std::cout << "Results saved to file " << _resultsFile << std::endl;
}
void writeTransactions()
{
{
std::unique_lock<std::mutex> lock(_testStartSync);
_testStartCv.wait(lock, [this] { return _testStarted; });
}
std::chrono::steady_clock::time_point start = std::chrono::steady_clock::now();
// hypothetical system has around 100k currently active users
std::uniform_int_distribution<> userDistribution(1, 100000);
// delay up to 5 ms for every thread not to start simultaneously
std::uniform_int_distribution<> waitTimeDistribution(0, 5000);
std::this_thread::sleep_for(std::chrono::microseconds(waitTimeDistribution(_randomGenerator)));
for (
auto iterationStart = std::chrono::steady_clock::now();
iterationStart - start < std::chrono::minutes(1);
iterationStart = std::chrono::steady_clock::now())
{
auto generatedUser = userDistribution(_randomGenerator);
TransactionData dummyTransaction = {
5477311,
generatedUser,
1824507435,
8055.05,
0,
"regular transaction by " + std::to_string(generatedUser)};
std::chrono::steady_clock::time_point operationStart = std::chrono::steady_clock::now();
_cache.write(dummyTransaction);
std::chrono::steady_clock::time_point operationEnd = std::chrono::steady_clock::now();
++_writeOpNum;
_writeTime += std::chrono::duration_cast<std::chrono::microseconds>(operationEnd - operationStart).count();
// make span between iterations at least 5ms
std::this_thread::sleep_for(iterationStart + std::chrono::milliseconds(5) - std::chrono::steady_clock::now());
}
}
void popTransactions()
{
{
std::unique_lock<std::mutex> lock(_testStartSync);
_testStartCv.wait(lock, [this] { return _testStarted; });
}
std::chrono::steady_clock::time_point start = std::chrono::steady_clock::now();
// hypothetical system has around 100k currently active users
std::uniform_int_distribution<> userDistribution(1, 100000);
// delay up to 100 ms for every thread not to start simultaneously
std::uniform_int_distribution<> waitTimeDistribution(0, 100000);
std::this_thread::sleep_for(std::chrono::microseconds(waitTimeDistribution(_randomGenerator)));
for (
auto iterationStart = std::chrono::steady_clock::now();
iterationStart - start < std::chrono::minutes(1);
iterationStart = std::chrono::steady_clock::now())
{
auto requestedUser = userDistribution(_randomGenerator);
std::chrono::steady_clock::time_point operationStart = std::chrono::steady_clock::now();
auto userTransactions = _cache.pop(requestedUser);
std::chrono::steady_clock::time_point operationEnd = std::chrono::steady_clock::now();
++_popOpNum;
_popTime += std::chrono::duration_cast<std::chrono::microseconds>(operationEnd - operationStart).count();
// make span between iterations at least 100ms
std::this_thread::sleep_for(iterationStart + std::chrono::milliseconds(100) - std::chrono::steady_clock::now());
}
}
CacheImpl _cache;
std::atomic<long> _writeTime;
std::atomic<long> _writeOpNum;
std::atomic<long> _popTime;
std::atomic<long> _popOpNum;
size_t _writeWorkersNum;
size_t _popWorkersNum;
std::string _resultsFile;
int _testrunsNum;
bool _testStarted;
std::mutex _testStartSync;
std::condition_variable _testStartCv;
std::mt19937 _randomGenerator;
};
void testCaches(const size_t testedShardSize, const size_t workersNum)
{
if (testedShardSize == 1)
{
auto simpleImplTest = Test<SimpleSynchronizedCache>(
10, workersNum, workersNum, "simple_cache_tests(" + std::to_string(workersNum) + "_workers).csv");
simpleImplTest.run();
}
else
{
auto shardedImpl4Test = Test<ShardedCache>(
10, workersNum, workersNum, "sharded_cache_" + std::to_string(testedShardSize) + "_tests(" + std::to_string(workersNum) + "_workers).csv", 4);
shardedImpl4Test.run();
}
}
int main()
{
std::cout << "Hardware concurrency: " << hardware_concurrency << std::endl;
std::array<size_t, 7> testPlan = { 1, 4, 8, 32, 128, 4096, 100000 };
for (auto i = 0; i < testPlan.size(); ++i)
{
testCaches(testPlan[i], 4 * hardware_concurrency);
}
// additional tests with diminished load to show limits of optimization advantage
std::array<size_t, 4> additionalTestPlan = { 1, 8, 128, 100000 };
for (auto i = 0; i < additionalTestPlan.size(); ++i)
{
testCaches(additionalTestPlan[i], hardware_concurrency);
}
}
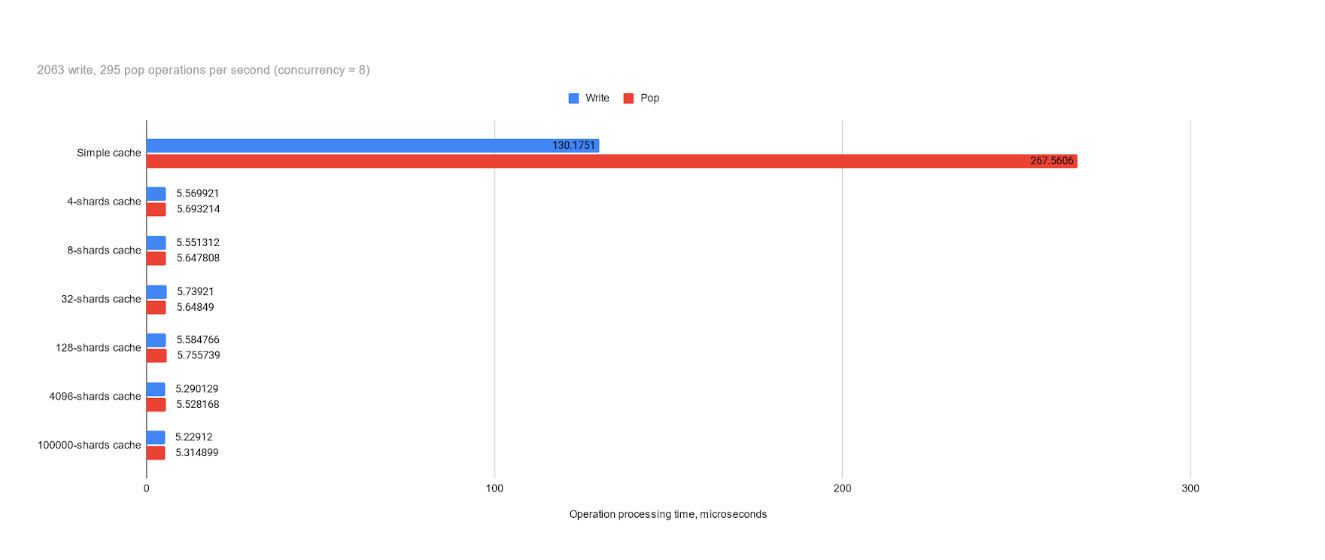
We observe that with 2,000 writes and 300 pops per second (with a concurrency of 8) — which are not very high numbers for a high-load system — optimization using sharding significantly accelerates cache performance, by orders of magnitude. However, evaluating the significance of this difference is left to the reader, as, in both scenarios, operations took less than a millisecond. It’s important to note that the tests used a relatively lightweight data structure for transactions, and synchronization was applied only to the container itself. In real-world scenarios, data is often more complex and larger, and synchronized processing may require additional computations and access to other data, which can significantly increase the time of operation itself. Therefore, we aim to spend as little time on synchronization as possible.
The tests do not show the significant difference in processing time when increasing the shard size. The greater the size the bigger is the maintaining overhead, so how low should we go? I suspect that the minimal effective value is tied to the system's concurrency, so for modern server machines with much greater concurrency than my home PC, a shard size that is too small won’t yield the most optimal results. I would love to see the results on other machines with different concurrency that may confirm or disprove this hypothesis, but for now I assume it is optimal to use a shard size that is several times larger than the concurrency. You can also note that the largest size tested — 100,000 — effectively matches the mentioned earlier approach of assigning a mutex to each user (in the tests, user IDs were generated within the range of 100,000). As can be seen, this did not provide any advantage in processing speed, and this approach is obviously more demanding in terms of memory.
Limitations and Considerations
So, we determined an optimal shard size, but this is not the only thing that should be considered for the best results.
It’s important to remember that such a difference compared to a simple implementation exists only because we are attempting to perform a sufficiently large number of transactions at the same time, causing a “queue” to build up. If the system’s concurrency and the speed of each operation (within the mutex lock) allow operations to be processed without bottlenecks, the effectiveness of sharding optimization decreases. To demonstrate this, let’s look at the test results with reduced load — at 500 writes and 75 pops (with a concurrency of 8) — the difference is still present, but it is no longer as significant. This is yet another reminder that premature optimizations can complicate code without significantly impacting results. It’s crucial to understand the application requirements and expected load.
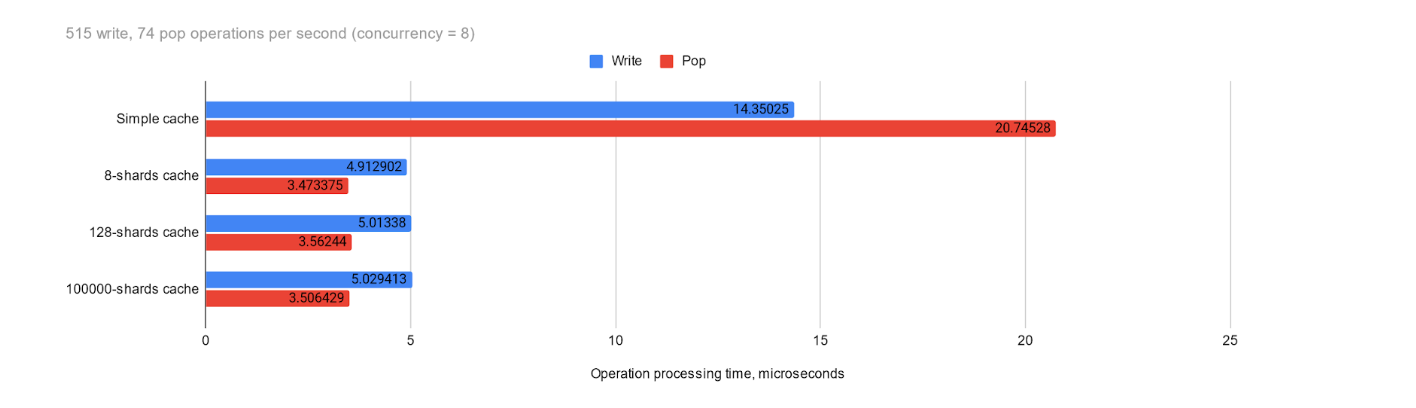
Also, it’s important to note that the effectiveness of sharding heavily depends on the distribution of values of the chosen key (in this case, user ID). If the distribution becomes heavily skewed, we may revert to performance more similar to that of a single mutex — imagine all of the transactions coming from a single user.
Conclusion
In scenarios with frequent writes to a container in a multi-threaded environment, traditional synchronization methods can become a bottleneck. By leveraging the ability of parallel processing of data and predictable distribution by some specific key and implementing a sharded synchronization approach, we can significantly improve performance without sacrificing thread safety. This technique can prove itself effective for systems dealing with user-specific data, such as transaction processing systems, user session caches, or any scenario where data can be logically partitioned based on a key attribute.
As with any optimization, it’s crucial to profile your specific use case and adjust the implementation accordingly. The approach presented here provides a starting point for tackling synchronization challenges in write-heavy, multi-threaded applications.
Remember, the goal of optimization is not just to make things faster, but to make them more efficient and scalable. By thinking critically about your data access patterns and leveraging the inherent structure of your data, you can often find innovative solutions to performance bottlenecks.
