OpenStack Savanna: Fast Hadoop Cluster Provisioning on OpenStack

introduction
openstack is one of the most popular open source cloud computing projects to provide infrastructure as a service solution. its key components are compute (nova), networking (neutron, formerly known as quantum), storage (object and block storage, swift and cinder, respectively), openstack dashboard (horizon), identity service (keystone) and image service (glance).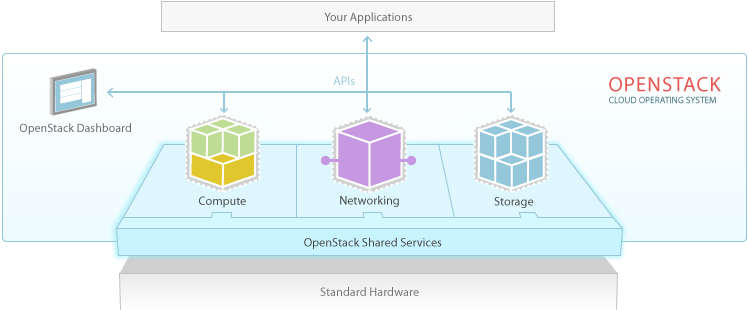
there are other official incubated projects like metering (celiometer) and orchestration and service definition (heat). savanna is a hadoop as a service for openstack introduced by mirantis . it is still in an early phase (version .02 was released in summer 2013) and according to its roadmap version 1.0 is targeted for official openstack incubation. in principle, heat also could be used for hadoop cluster provisioning but savanna is especially tuned for providing hadoop-specific api functionality while heat is meant to be used for generic purposes.
savanna architecture
savanna is integrated with the core openstack components such as keystone, nova, glance, swift and horizon. it has a rest api that supports the hadoop cluster provisioning steps.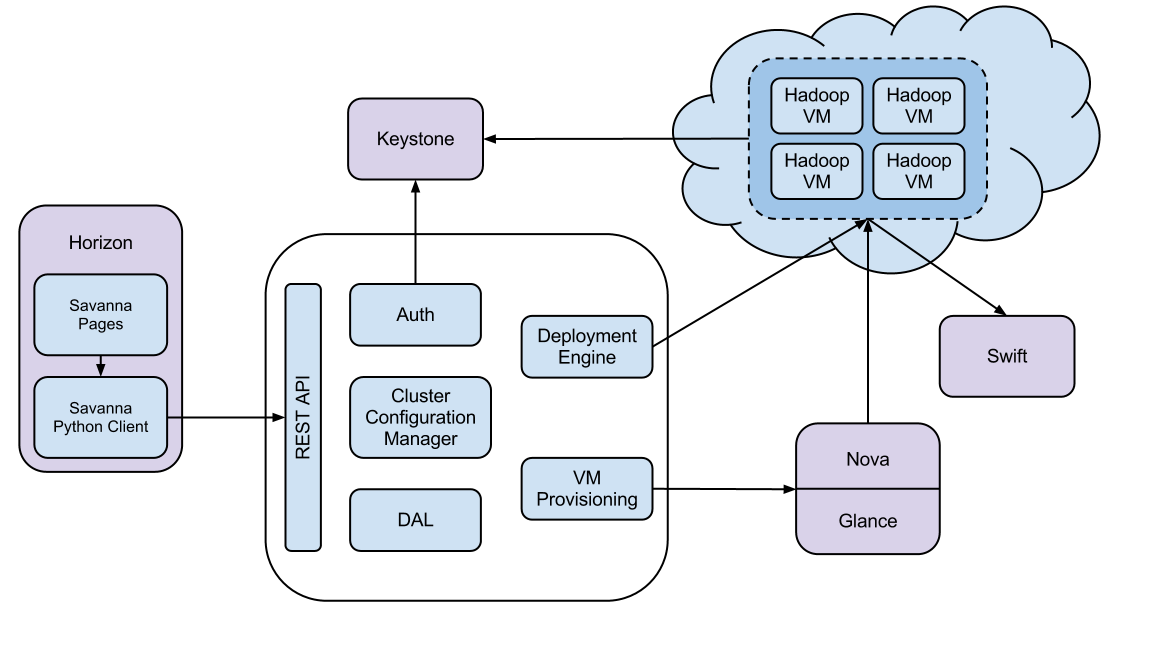
savanna api is implemented as a wsgi server that, by default, listens to port 8386. in addition, savanna can also be integrated with horizon, the openstack dashboard to create a hadoop cluster from the management console. savanna also comes with a vanilla plugin that deploys a hadoop cluster image. the standard out-of-the-box vanilla plugin supports hadoop 1.1.2 version.
installing savanna
the simplest option to try out savanna is to use devstack in a virtual machine. i was using an ubuntu 12.04 virtual instance in my tests. in that environment we need to execute the following commands to install devstack and savanna api:$ sudo apt-get install git-core $ git clone https://github.com/openstack-dev/devstack.git $ vi localrc # edit localrc admin_password=nova mysql_password=nova rabbit_password=nova service_password=$admin_password service_token=nova # enable swift enabled_services+=,swift swift_hash=66a3d6b56c1f479c8b4e70ab5c2000f5 swift_replicas=1 swift_data_dir=$dest/data # force checkout prerequsites # force_prereq=1 # keystone is now configured by default to use pki as the token format which produces huge tokens. # set uuid as keystone token format which is much shorter and easier to work with. keystone_token_format=uuid # change the floating_range to whatever ips vm is working in. # in nat mode it is subnet vmware fusion provides, in bridged mode it is your local network. floating_range=192.168.55.224/27 # enable auto assignment of floating ips. by default savanna expects this setting to be enabled extra_opts=(auto_assign_floating_ip=true) # enable logging screen_logdir=$dest/logs/screen $ ./stack.sh # this will take a while to execute $ sudo apt-get install python-setuptools python-virtualenv python-dev $ virtualenv savanna-venv $ savanna-venv/bin/pip install savanna $ mkdir savanna-venv/etc $ cp savanna-venv/share/savanna/savanna.conf.sample savanna-venv/etc/savanna.conf # to start savanna api: $ savanna-venv/bin/python savanna-venv/bin/savanna-api --config-file savanna-venv/etc/savanna.confto install savanna ui integrated with horizon, we need to run the following commands:
$ sudo pip install savanna-dashboard
$ cd /opt/stack/horizon/openstack-dashboard
$ vi settings.py
horizon_config = {
'dashboards': ('nova', 'syspanel', 'settings', 'savanna'),
installed_apps = (
'savannadashboard',
....
$ cd /opt/stack/horizon/openstack-dashboard/local
$ vi local_settings.py
savanna_url = 'http://localhost:8386/v1.0'
$ sudo service apache2 restart
provisioning a hadoop cluster
as a first step, we need to configure keystone-related environment variables to get the authentication token:ubuntu@ip-10-59-33-68:~$ vi .bashrc $ export os_auth_url=http://127.0.0.1:5000/v2.0/ $ export os_tenant_name=admin $ export os_username=admin $ export os_password=nova ubuntu@ip-10-59-33-68:~$ source .bashrc ubuntu@ip-10-59-33-68:~$ ubuntu@ip-10-59-33-68:~$ env | grep os os_password=nova os_auth_url=http://127.0.0.1:5000/v2.0/ os_username=admin os_tenant_name=admin ubuntu@ip-10-59-33-68:~$ keystone token-get +-----------+----------------------------------+ | property | value | +-----------+----------------------------------+ | expires | 2013-08-09t20:31:12z | | id | bdb582c836e3474f979c5aa8f844c000 | | tenant_id | 2f46e214984f4990b9c39d9c6222f572 | | user_id | 077311b0a8304c8e86dc0dc168a67091 | +-----------+----------------------------------+ $ export auth_token="bdb582c836e3474f979c5aa8f844c000" $ export tenant_id="2f46e214984f4990b9c39d9c6222f572"then we need to create the glance image that we want to use for our hadoop cluster. in our example we have used mirantis's vanilla image but we can also build our own image:
$ wget http://savanna-files.mirantis.com/savanna-0.2-vanilla-1.1.2-ubuntu-12.10.qcow2 $ glance image-create --name=savanna-0.2-vanilla-hadoop-ubuntu.qcow2 --disk-format=qcow2 --container-format=bare < ./savanna-0.2-vanilla-1.1.2-ubuntu-12.10.qcow2 ubuntu@ip-10-59-33-68:~/devstack$ glance image-list +--------------------------------------+-----------------------------------------+-------------+------------------+-----------+--------+ | id | name | disk format | container format | size | status | +--------------------------------------+-----------------------------------------+-------------+------------------+-----------+--------+ | d0d64f5c-9c15-4e7b-ad4c-13859eafa7b8 | cirros-0.3.1-x86_64-uec | ami | ami | 25165824 | active | | fee679ee-e0c0-447e-8ebd-028050b54af9 | cirros-0.3.1-x86_64-uec-kernel | aki | aki | 4955792 | active | | 1e52089b-930a-4dfc-b707-89b568d92e7e | cirros-0.3.1-x86_64-uec-ramdisk | ari | ari | 3714968 | active | | d28051e2-9ddd-45f0-9edc-8923db46fdf9 | savanna-0.2-vanilla-hadoop-ubuntu.qcow2 | qcow2 | bare | 551699456 | active | +--------------------------------------+-----------------------------------------+-------------+------------------+-----------+--------+ $ export image_id=d28051e2-9ddd-45f0-9edc-8923db46fdf9then we have installed httpie , an open source http client that can be used to send rest requests to savanna api:
$ sudo pip install httpiefrom now on we will use httpie to send savanna commands. we need to register the image with savanna:
$ export savanna_url="http://localhost:8386/v1.0/$tenant_id"
$ http post $savanna_url/images/$image_id x-auth-token:$auth_token username=ubuntu
http/1.1 202 accepted
content-length: 411
content-type: application/json
date: thu, 08 aug 2013 21:28:07 gmt
{
"image": {
"os-ext-img-size:size": 551699456,
"created": "2013-08-08t21:05:55z",
"description": "none",
"id": "d28051e2-9ddd-45f0-9edc-8923db46fdf9",
"metadata": {
"_savanna_description": "none",
"_savanna_username": "ubuntu"
},
"mindisk": 0,
"minram": 0,
"name": "savanna-0.2-vanilla-hadoop-ubuntu.qcow2",
"progress": 100,
"status": "active",
"tags": [],
"updated": "2013-08-08t21:28:07z",
"username": "ubuntu"
}
}
$ http $savanna_url/images/$image_id/tag x-auth-token:$auth_token tags:='["vanilla", "1.1.2", "ubuntu"]'
http/1.1 202 accepted
content-length: 532
content-type: application/json
date: thu, 08 aug 2013 21:29:25 gmt
{
"image": {
"os-ext-img-size:size": 551699456,
"created": "2013-08-08t21:05:55z",
"description": "none",
"id": "d28051e2-9ddd-45f0-9edc-8923db46fdf9",
"metadata": {
"_savanna_description": "none",
"_savanna_tag_1.1.2": "true",
"_savanna_tag_ubuntu": "true",
"_savanna_tag_vanilla": "true",
"_savanna_username": "ubuntu"
},
"mindisk": 0,
"minram": 0,
"name": "savanna-0.2-vanilla-hadoop-ubuntu.qcow2",
"progress": 100,
"status": "active",
"tags": [
"vanilla",
"ubuntu",
"1.1.2"
],
"updated": "2013-08-08t21:29:25z",
"username": "ubuntu"
}
} then we need to create a
nodegroup templates (json files) that will be sent to savanna. there is one template for the master nodes (
namenode ,
jobtracker ) and another template for the worker nodes such as
datanode and
tasktracker . the hadoop version is 1.1.2.
$ vi ng_master_template_create.json
{
"name": "test-master-tmpl",
"flavor_id": "2",
"plugin_name": "vanilla",
"hadoop_version": "1.1.2",
"node_processes": ["jobtracker", "namenode"]
}
$ vi ng_worker_template_create.json
{
"name": "test-worker-tmpl",
"flavor_id": "2",
"plugin_name": "vanilla",
"hadoop_version": "1.1.2",
"node_processes": ["tasktracker", "datanode"]
}
$ http $savanna_url/node-group-templates x-auth-token:$auth_token < ng_master_template_create.json
http/1.1 202 accepted
content-length: 387
content-type: application/json
date: thu, 08 aug 2013 21:58:00 gmt
{
"node_group_template": {
"created": "2013-08-08t21:58:00",
"flavor_id": "2",
"hadoop_version": "1.1.2",
"id": "b3a79c88-b6fb-43d2-9a56-310218c66f7c",
"name": "test-master-tmpl",
"node_configs": {},
"node_processes": [
"jobtracker",
"namenode"
],
"plugin_name": "vanilla",
"updated": "2013-08-08t21:58:00",
"volume_mount_prefix": "/volumes/disk",
"volumes_per_node": 0,
"volumes_size": 10
}
}
$ http $savanna_url/node-group-templates x-auth-token:$auth_token < ng_worker_template_create.json
http/1.1 202 accepted
content-length: 388
content-type: application/json
date: thu, 08 aug 2013 21:59:41 gmt
{
"node_group_template": {
"created": "2013-08-08t21:59:41",
"flavor_id": "2",
"hadoop_version": "1.1.2",
"id": "773b2cfb-1e05-46f4-923f-13edc7d6aac6",
"name": "test-worker-tmpl",
"node_configs": {},
"node_processes": [
"tasktracker",
"datanode"
],
"plugin_name": "vanilla",
"updated": "2013-08-08t21:59:41",
"volume_mount_prefix": "/volumes/disk",
"volumes_per_node": 0,
"volumes_size": 10
}
} the next step is to define the cluster template:
$ vi cluster_template_create.json
{
"name": "demo-cluster-template",
"plugin_name": "vanilla",
"hadoop_version": "1.1.2",
"node_groups": [
{
"name": "master",
"node_group_template_id": "b3a79c88-b6fb-43d2-9a56-310218c66f7c",
"count": 1
},
{
"name": "workers",
"node_group_template_id": "773b2cfb-1e05-46f4-923f-13edc7d6aac6",
"count": 2
}
]
}
$ http $savanna_url/cluster-templates x-auth-token:$auth_token < cluster_template_create.json
http/1.1 202 accepted
content-length: 815
content-type: application/json
date: fri, 09 aug 2013 07:04:24 gmt
{
"cluster_template": {
"anti_affinity": [],
"cluster_configs": {},
"created": "2013-08-09t07:04:24",
"hadoop_version": "1.1.2",
"id": "{
"name": "cluster-1",
"plugin_name": "vanilla",
"hadoop_version": "1.1.2",
"cluster_template_id" : "64c4117b-acee-4da7-937b-cb964f0471a9",
"user_keypair_id": "stack",
"default_image_id": "3f9fc974-b484-4756-82a4-bff9e116919b"
}",
"name": "demo-cluster-template",
"node_groups": [
{
"count": 1,
"flavor_id": "2",
"name": "master",
"node_configs": {},
"node_group_template_id": "b3a79c88-b6fb-43d2-9a56-310218c66f7c",
"node_processes": [
"jobtracker",
"namenode"
],
"volume_mount_prefix": "/volumes/disk",
"volumes_per_node": 0,
"volumes_size": 10
},
{
"count": 2,
"flavor_id": "2",
"name": "workers",
"node_configs": {},
"node_group_template_id": "773b2cfb-1e05-46f4-923f-13edc7d6aac6",
"node_processes": [
"tasktracker",
"datanode"
],
"volume_mount_prefix": "/volumes/disk",
"volumes_per_node": 0,
"volumes_size": 10
}
],
"plugin_name": "vanilla",
"updated": "2013-08-09t07:04:24"
}
} now we are ready to create the hadoop cluster:
$ vi cluster_create.json
{
"name": "cluster-1",
"plugin_name": "vanilla",
"hadoop_version": "1.1.2",
"cluster_template_id" : "64c4117b-acee-4da7-937b-cb964f0471a9",
"user_keypair_id": "savanna",
"default_image_id": "d28051e2-9ddd-45f0-9edc-8923db46fdf9"
}
$ http $savanna_url/clusters x-auth-token:$auth_token < cluster_create.json
http/1.1 202 accepted
content-length: 1153
content-type: application/json
date: fri, 09 aug 2013 07:28:14 gmt
{
"cluster": {
"anti_affinity": [],
"cluster_configs": {},
"cluster_template_id": "64c4117b-acee-4da7-937b-cb964f0471a9",
"created": "2013-08-09t07:28:14",
"default_image_id": "d28051e2-9ddd-45f0-9edc-8923db46fdf9",
"hadoop_version": "1.1.2",
"id": "d919f1db-522f-45ab-aadd-c078ba3bb4e3",
"info": {},
"name": "cluster-1",
"node_groups": [
{
"count": 1,
"created": "2013-08-09t07:28:14",
"flavor_id": "2",
"instances": [],
"name": "master",
"node_configs": {},
"node_group_template_id": "b3a79c88-b6fb-43d2-9a56-310218c66f7c",
"node_processes": [
"jobtracker",
"namenode"
],
"updated": "2013-08-09t07:28:14",
"volume_mount_prefix": "/volumes/disk",
"volumes_per_node": 0,
"volumes_size": 10
},
{
"count": 2,
"created": "2013-08-09t07:28:14",
"flavor_id": "2",
"instances": [],
"name": "workers",
"node_configs": {},
"node_group_template_id": "773b2cfb-1e05-46f4-923f-13edc7d6aac6",
"node_processes": [
"tasktracker",
"datanode"
],
"updated": "2013-08-09t07:28:14",
"volume_mount_prefix": "/volumes/disk",
"volumes_per_node": 0,
"volumes_size": 10
}
],
"plugin_name": "vanilla",
"status": "validating",
"updated": "2013-08-09t07:28:14",
"user_keypair_id": "savanna"
}
} after a while we can run the
nova command to check if the instances are created and running:
$ nova list +--------------------------------------+-----------------------+--------+------------+-------------+----------------------------------+ | id | name | status | task state | power state | networks | +--------------------------------------+-----------------------+--------+------------+-------------+----------------------------------+ | 1a9f43bf-cddb-4556-877b-cc993730da88 | cluster-1-master-001 | active | none | running | private=10.0.0.2, 192.168.55.227 | | bb55f881-1f96-4669-a94a-58cbf4d88f39 | cluster-1-workers-001 | active | none | running | private=10.0.0.3, 192.168.55.226 | | 012a24e2-fa33-49f3-b051-9ee2690864df | cluster-1-workers-002 | active | none | running | private=10.0.0.4, 192.168.55.225 | +--------------------------------------+-----------------------+--------+------------+-------------+----------------------------------+now we can log in to the hadoop master instance and run the required hadoop commands:
$ ssh -i savanna.pem ubuntu@10.0.0.2 $ sudo chmod 777 /usr/share/hadoop $ sudo su hadoop $ cd /usr/share/hadoop $ hadoop jar hadoop-example-1.1.2.jar pi 10 100
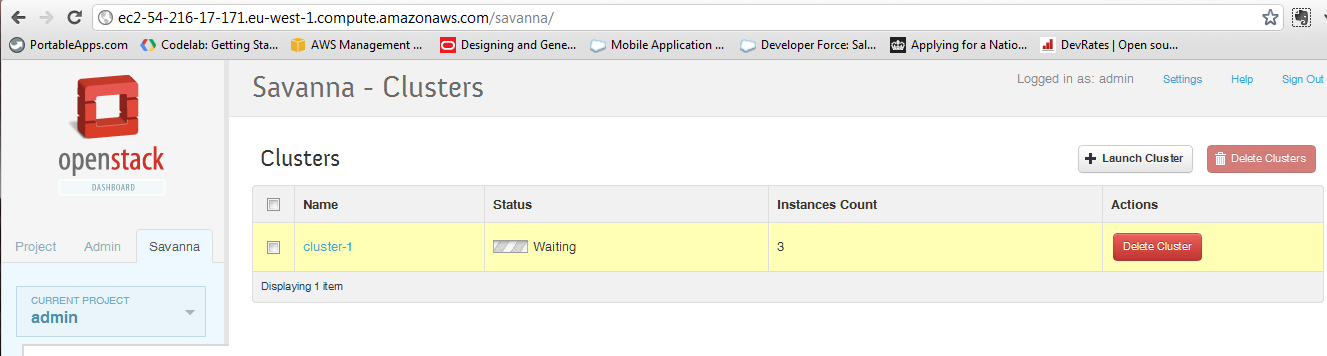
savanna ui via horizon
in order to create nodegroup templates, cluster templates and the cluster itself we used a command line tool -- httpie -- to send rest api calls. the same functionality is also available via horizon, the standard openstack dashboard. first we need to register the image with savanna: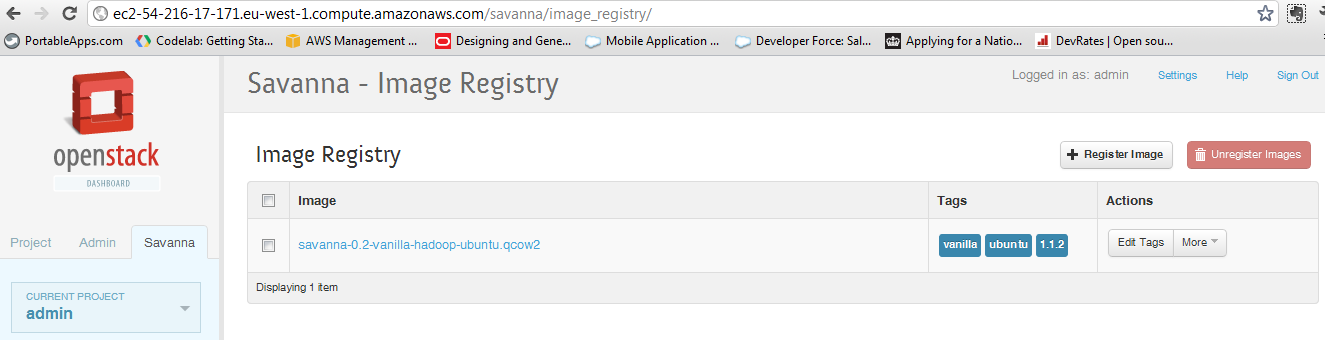
then we need to create the nodegroup templates:
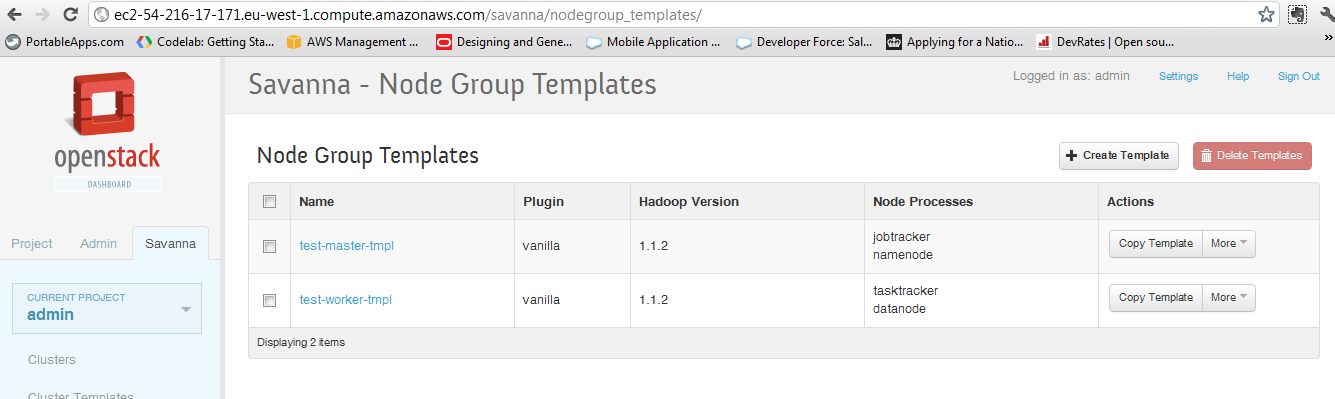
after that we have to create the cluster template:
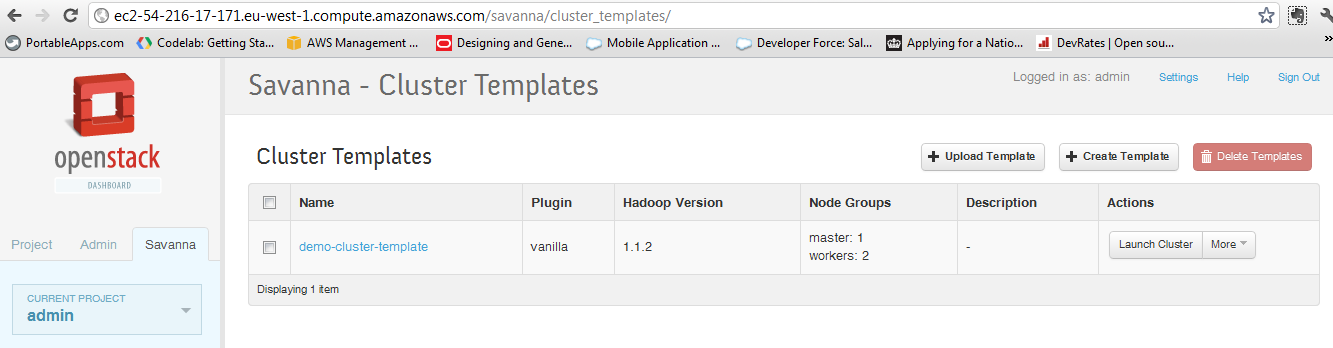
and finally we have to create the cluster: