Distributed Counters Feature Design

this is another experiment with longer posts.
previously, i used the time series example as the bed on which to test some ideas regarding feature design, to explain how we work and in general work out the rough patches along the way. i should probably note that these posts are purely fiction at this point. we have no plans to include a time series feature in ravendb at this time. i am trying to work out some thoughts in the open and get your feedback.
at any rate, yesterday we had a request for cassandra style counters at the mailing list. and as long as i am doing feature design series, i thought that i could talk about how i would go about implementing this. again, consider this fiction, i have no plans of implementing this at this time.
the essence of what we want is to be able to… count stuff. efficiently, in a distributed manner, with optional support for cross data center replication.
very roughly, the idea is to have “sub counters”, unique for every node in the system. whenever you increment the value, we log this to our own sub counter, and then replicate it out. whenever you read it, we just sum all the data we have from all the sub counters.
let us outline the various parts of the solution in the same order as the one i used for time series.
storage
a counter is just a named 64 bits signed integer. a counter name can be any string up to 128 printable characters. the external interface of the storage would look like this:
1: public struct counterincrement
2: {
3: public string name;
4: public long change;
5: }
6:
7: public struct counter
8: {
9: public string name;
10: public string source;
11: public long value;
12: }
13:
14: public interface icounterstorage
15: {
16: void localincrementbatch(counterincrement[] batch);
17:
18: counter[] read(string name);
19:
20: void replicatedupdates(counter[] updates);
21: }
as you can see, this gives us very simple interface for the storage. we can either change the data locally (which modify our own storage) or we can get an update from a replica about its changes.
there really isn’t much more to it, to be fair. the localincrementbatch() increment a local value, and read() will return all the values for a counter. there is a little bit of trickery involved in how exactly one would store the counter values.
for now, i think we’ll store each counter as two step values. we’ll have a tree of multi tree values that will carry each value from each source. that means that a counter will take roughly 4kb or so. this is easy to work with and nicely fit the model voron uses internally.
note that we’ll outline additional requirement for storage (searching for counter by prefix, iterating over counters, addresses of other servers, stats, etc) below. i’m not showing them here because they aren’t the major issue yet.
over the wire
skipping out on any optimizations that might be required, we will expose the following endpoints:
- get /counters/read?id=users/1/visits&users/1/posts <—will return json response with all the relevant values (already summed up).
{ “users/1/visits”: 43, “users/1/posts”: 3 } - get /counters/read?id=users/1/visits&users/1/1/posts&raw=true <—will return json response with all the relevant values, per source.
{ “users/1/visits”: {“rvn1”: 21, “rvn2”: 22 } , “users/1/posts”: { “rvn1”: 2, “rvn3”: 1 } } - post /counters/increment <– allows to increment counters. the request is a json array of the counter name and the change.
for a real system, you’ll probably need a lot more stuff, metrics, stats, etc. but this is the high level design, so this would be enough.
note that we are skipping the high performance stream based writes we outlined for time series. we’ll probably won’t need them, so that doesn’t matter, but they are an option if we need them.
system behavior
this is where it is really not interesting, there is very little behavior here, actually. we only have to read the data from the storage, sum it up, and send it to the user. hardly what i’ll call business logic.
client api
the client api will probably look something like this:
1: counters.increment("users/1/posts");
2: counters.increment("users/1/visits", 4);
3:
4: using(var batch = counters.batch())
5: {
6: batch.increment("users/1/posts");
7: batch.increment("users/1/visits",5);
8: batch.submit();
9: }
note that we’re offering both batch and single api. we’ll likely also want to offer a fire & forget style, which will be able to offer even better performance (because they could do batching across more than a single thread), but that is out of scope for now.
for simplicity sake, we are going to have the client just a container for all of endpoints that it knows about. the container would be responsible for… updating the client visible topology, selecting the best server to use at any given point, etc.
user interface
there isn’t much to it. just show a list of counter values in a list. allow to search by prefix, allow to dive into a particular counter and read its raw values, but that is about it. oh, and allow to delete a counter.
deleting data
honestly, i really hate deletes. they are very expensive to handle properly the moment you have more than a single node. in this case, there is an inherent race condition between a delete going out and another node getting an increment. and then there is the issue of what happens if you had a node down when you did the delete, etc.
this just sucks. deletion are handled normally, (with the race condition caveat, obviously), and i’ll discuss how we replicate them in a bit.
high availability / scale out
by definition, we actually don’t want to have storage replication here. either log shipping or consensus based. we actually do want to have different values, because we are going to be modifying things independently on many servers.
that means that we need to do replication at the database level. and that leads to some interesting questions. again, the hard part here is the deletes. actually, the really hard part is what we are going to do with the new server problem.
the new server problem dictates how we are going to bring a new server into the cluster. if we could fix the size of the cluster, that would make things a lot easier. however, we are actually interested in being able to dynamically grow the cluster size.
therefor, there are only two real ways to do it:
- add a new empty node to the cluster, and have it be filled from all the other servers.
- add a new node by backing up an existing node, and restoring as a new node.
ravendb, for example, follows the first option. but it means that in needs to track a lot more information. the second option is actually a lot simpler, because we don’t need to care about keeping around old data.
however, this means that the process of bringing up a new server would now be:
- update all nodes in the cluster with the new node address (node isn’t up yet, replication to it will fail and be queued).
- backup an existing node and restore at the new node.
- start the new node.
the order of steps is quite important. and it would be easy to get it wrong. also, on large systems, backup & restore can take a long time. operationally speaking, i would much rather just be able to do something like, bring a new node into the cluster in “silent” mode. that is, it would get information from all the other nodes, and i can “flip the switch” and make it visible to clients at any point in time. that is how you do it with ravendb, and it is an incredibly powerful system, when used properly.
that means that for all intents and purposes, we don’t do real deletes. what we’ll actually do is replace the counter value with delete marker. this turns deletes into a much simple “just another write”. it has the sad implication of not free disk space on deletes, but deletes tend to be rare, and it is usually fine to add a “purge” admin option that can be run on as needed basis.
but that brings us to an interesting issue, how do we actually handle replication.
the topology map
to simplify things, we are going to go with one way replication from a node to another. that allows complex topologies like master-master, cluster-cluster, replication chain, etc. but in the end, this is all about a single node replication to another.
the first question to ask is, are we going to replicate just our local changes, or are we going to have to replicate external changes as well? the problem with replicating external changes is that you may have the following topology:
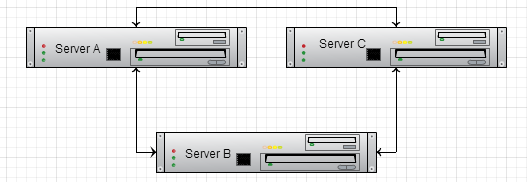
now, server a got a value and sent it to server b. server b then forwarded it to server c. however, at that point, we also have a the value from server a replicated directly to server c. which value is it supposed to pick? and what about a scenario where you have more complex topology?
in general, because in this type of system, we can have any node accept writes, and we actually desire this to be the case , we don’t want this behavior. we want to only replicate local data, not all the data.
of course, that leads to an annoying question, what happens if we have a 3 node cluster, and one node fails catastrophically. we can bring a new node in, and the other two nodes will be able to fill in their values via replication, but what about the node that is down? the data isn’t gone, it is still right there in the other two nodes, but we need a way to pull it out.
therefor, i think that the best option would be to say that nodes only replicate their local state, except in the case of a new node. a new node will be told the address of an existing node in the cluster, at which point it will:
- register itself in all the nodes in the cluster (discoverable from the existing node). this assumes a standard two way replication link between all servers, if this isn’t the case, the operators would have the responsibility to setup the actual replication semantics on their own.
- new node now starts getting updates from all the nodes in the cluster. it keeps them in a log for now, not doing anything yet.
- ask that node for a complete update of all of its current state.
- when it has all the complete state of the existing node, it replays all of the remembered logs that it didn’t have a chance to apply yet.
- then it announces that it is in a valid state to start accepting client connections.
note that this process is likely to be very sensitive to high data volumes. that is why you’ll usually want to select a backup node to read from, and that decision is an ops decision.
you’ll also want to be able to report extensively on the current status of the node, since this can take a while, and ops will be watching this very closely.
server name
a node requires a unique name. we can use guids, but those aren’t readable, so we can use machine name + port, but those can change. ideally, we can require the user to set us up with a unique name. that is important for readability and for being able to alter see all the values we have in all the nodes. it is important that names are never repeated, so we’ll probably have a guid there anyway, just to be on the safe side.
actual replication semantics
since we have the new server problem down to an automated process, we can choose the drastically simpler model of just having an internal queue per each replication destination. whenever we make a change, we also make a note of that in the queue for that destination, then we start an async replication process to that server, sending all of our updates there.
it is always safe to overwrite data using replication, because we are overwriting our own data, never anyone else.
and… that is about it, actually. there are probably a lot of details that i am missing / would discover if we were to actually implement this. but i think that this is a pretty good idea about what this feature is about.
