Smart Resource Utilization With Spark Dynamic Allocation

When a Spark application is submitted to a cluster, the cluster allocates the resources requested by the application for the entire duration of the application lifecycle. These resources cannot be shared with other application as they are dedicated to that application.
This paradigm is suitable for batch processing applications. The application is submitted, handling huge amounts of data, and when it is done (the main program exits and the driver JVM is terminated), the cluster reclaims the resources back and those resources are available for other applications to utilize. Usually, the batch application does need the resources for most of its lifecycle. However, what if this application is not a batch job? What if it is a server that serves users upon request? Or maybe a streaming application that handles data in a variable load?
On such applications, the demand for high resources is only needed during peak time, but during idle time, it is a waste of resources to allocate high capacity that is not used. Such an application use case can be:
A streaming application that handles varying loads of data using the new Spark Structured Streaming.
A REST server that serves SQL queries on data using Spark SQL.
A Notebook IDE such as Apache Zeppelin that allows interactive analytics using Spark over a cluster of nodes.
All those applications need Spark to run perpetually but also need high capacity resources only part of the time. For this, Spark comes to our aid with Spark Dynamic Allocation. The main idea is this: the Spark application will request minimal (or even no) resources during idle time, but when there are tasks to be performed, it will request more resources to complete those tasks. When the load is done, Spark will release those resources back to the cluster. In this way, we can utilize our cluster's resources in an efficient way.
How It Works
The minimal unit of resource that a Spark application can request and dismiss is an Executor. This is a single JVM that can handle one or many concurrent tasks according to its configuration. We can set the number of cores per executor in the configuration key spark.executor.cores or in spark-submit's parameter --executor-cores. If, for instance, it is set to 2, this Executor can handle up to two concurrent tasks. The RAM of each executor can also be set using the spark.executor.memory key or the --executor-memory parameter; for instance, 2GB per executor.
From the dynamic allocation point of view, in this case, the application can request resources of 2 cores and 2GB RAM units each time. The application will first request 1 unit of such resources but if the loads increase, the following requests will get exponentially bigger by the power of 2: 2, 4, 8, etc.
The application measures its load by the number of tasks waiting to be performed. If the queue of waiting tasks contains more tasks than the number of cores the application already has, it will try to request more cores. These requests are granted up to the cluster's limit or to a limit that can be configured in the application's context.
When the number of waiting tasks becomes zero, the application will dismiss the idle executors until it reaches the minimum number of executors it is configured to use. By default, this number is zero.
Configuration
In order to support dynamic allocation, the cluster must be configured to have an external shuffle service. This is needed in order to retain shuffle information when the Executor is removed. All cluster managers used by Spark support external shufflers. Here, I will talk about the Spark standalone cluster manager. For more details on configuring Mesos or Yarn, see Spark's dynamic allocation configuration. In order to configure an external shuffler on Spark standalone, start the worker with the key spark.shuffle.service.enabled set to true .
In addition, the Spark application must be started with the key spark.dynamicAllocation.enabled set to true. This can be done, for instance, through parameters to the spark-submit program, as follows:
spark-submit --master spark://<spark_master>:7077
--class com.haimcohen.spark.SparkJavaStreamTest
--executor-cores 1 --executor-memory 1G
--conf spark.dynamicAllocation.enabled=true spark-app.jarPlease note: Since a single Executor is the smallest unit an application can request and remove, it is wise to set a small amount of resources per executor. In the case above, each executor will utilize 1 core and 1GB RAM. This allows the application to increment its resources by 1 core and 1GB at a time.
Additional Configuration
Limit Resources
Each application can set the minimal and maximal resources the cluster should allocate to. This is done by setting the minimum and the maximum number of executors. The configuration keys to control those numbers are spark.dynamicAllocation.minExecutors (default value: zero) and spark.dynamicAllocation.maxExecutors (default value: infinity).
Resource Removal Policy
When no tasks are to be executed, the executor becomes idle. By default, 60 seconds of idle executor will be removed. This value can be controlled through the key spark.dynamicAllocation.executorIdleTimeout.
Caching
When an application caches a dataset or RDD in memory or disk, this cache memory is lost when the executor is removed. As a default policy, dynamic allocation will not remove Executors that cache data. I found it a bit harsh for my applications, as I needed the applications to cache the dataset for a limited amount of time. Luckily, it is possible to change that policy by setting the number of seconds an executor can be removed even if it cached data spark.dynamicAllocation.cachedExecutorIdleTimeout. In future versions of Spark, it is planned to manage caches in an external service, much in the same way shuffles management is done.
Testing
In order to test dynamic allocation, I started two long-running applications with dynamic allocation enabled. Each application configured to use 1 core and 1GB RAM per executor. The applications I used for testing are Apache Zeppelin and Spark Structured Streaming. I used a cluster of a single node with 8 cores and 15GB RAM.
When the applications were in an idle state, the Spark Standalone UI (port 8080 on the master node) looked like this:
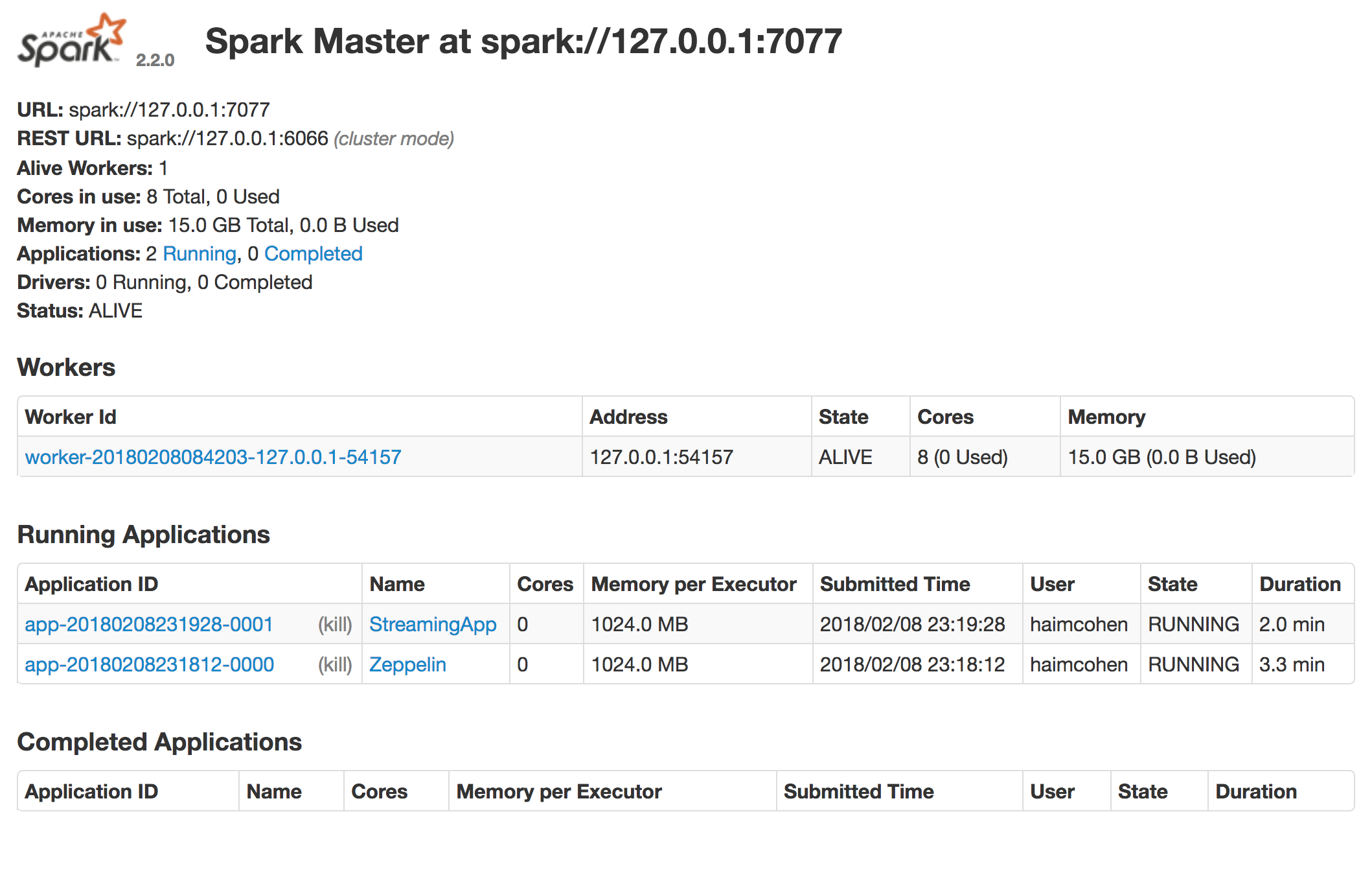
You can see that the worker has zero used cores and memory. When I ran some code in Zeppelin and added some files to the streaming application, I could see both applications running:
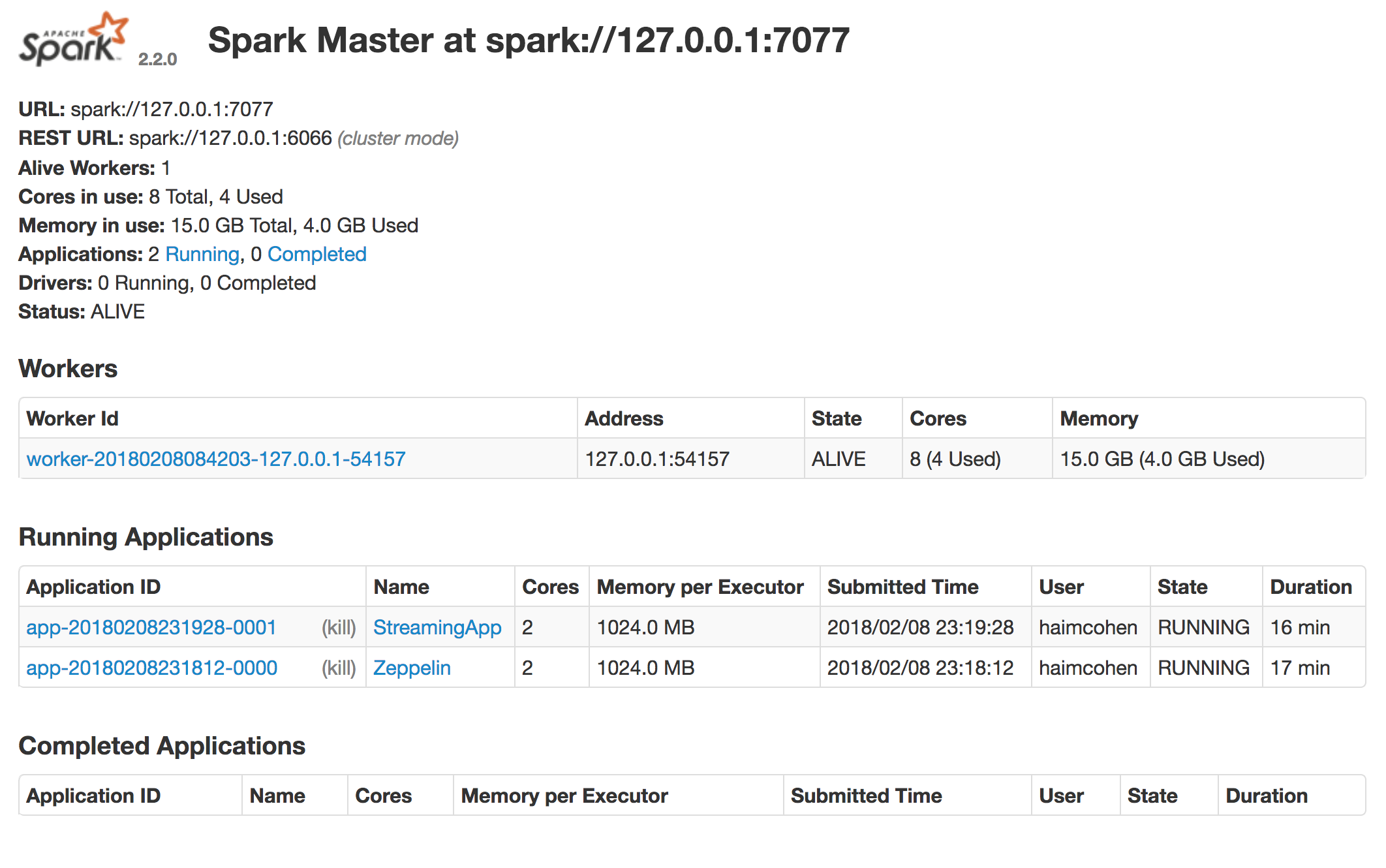
You can see each application uses 2 cores (1 core per executor) and the total cores used in our worker is 4. The memory is also totaled to 4GB used.
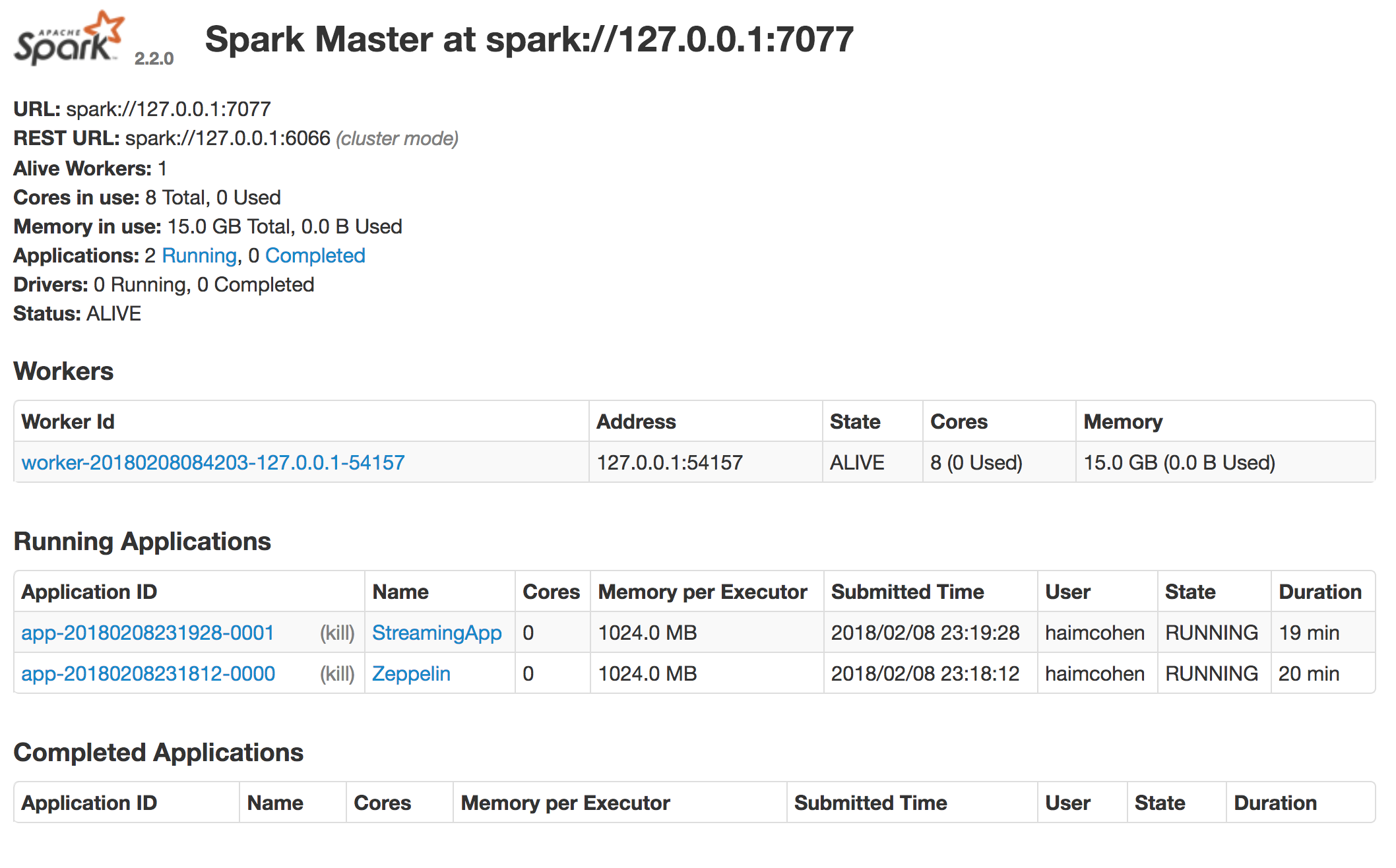
When the applications went back to idle, you could see that the executors were removed and no cores and memory were used:
Conclusion
On a long-running Spark application with a substantial amount of idle time, it is more efficient to use dynamic allocation and cluster resources for other needs during these idle periods. This still allows the long-running application to utilize high resources on peak time. Configuring your applications wisely will provide a good balance between smart allocation and performance.
