The Magic of Kafka With Spring Boot

Apache Kafka is a distributed streaming platform with capabilities such as publishing and subscribing to a stream of records, storing the records in a fault tolerant way, and processing that stream of records.
It is used to build real-time streaming data pipelines, that can perform functionalities such as reliably passing a stream of records from one application to another and processing and transferring the records to the target applications.
Topics
Kafka is run as a cluster in one or more servers and the cluster stores/retrieves the records in a feed/category called Topics. Each record in the topic is stored with a key, value, and timestamp.
The topics can have zero, one, or multiple consumers, who will subscribe to the data written to that topic. In Kafka terms, topics are always part of a multi-subscriber feed.
Partitions
The Kafka cluster uses a partitioned log for each topic.

The partition maintains the order in which data was inserted and once the record is published to the topic, it remains there depending on the retention period (which is configurable). The records are always appended at the end of the partitions. It maintains a flag called 'offsets,' which uniquely identifies each record within the partition.
The offset is controlled by the consuming applications. Using offset, consumers might backtrace to older offsets and reprocess the records if needed.
Producers
The stream of records, i.e. data, is published to the topics by the producers. They can also assign the partition when it is publishing data to the topic. The producer can send data in a round robin way or it can implement a priority system based on sending records to certain partitions based on the priority of the record.
Consumers
Consumers consume the records from the topic. They are based on the concept of a consumer-group, where some of the consumers are assigned in the group. The record which is published to the topic is only delivered to one instance of the consumer from one consumer-group. Kafka internally uses a mechanism of consuming records inside the consumer-group. Each instance of the consumer will get hold of the particular partition log, such that within a consumer-group, the records can be processed parallelly by each consumer.
Spring Boot Kafka
Spring provides good support for Kafka and provides the abstraction layers to work with over the native Kafka Java clients.
We can add the below dependencies to get started with Spring Boot and Kafka.
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.2.3.RELEASE</version>
</dependency>To download and install Kafka, please refer the official guide https://kafka.apache.org/quickstart .
Once you download Kafka, you can issue a command to start ZooKeeper which is used by Kafka to store metadata.
zookeeper-server-start.bat .\config\zookeeper.properties
Next, we need to start the Kafka cluster locally by issuing the below command.
kafka-server-start.bat .\config\server.properties
Now, by default, the Kafka server starts on localhost:9092.
Write a simple REST controller and expose one endpoint, /publish, as shown below. It is used to publish the message to the topic.
package com.rahul.kafkaspringboot.controllers;
import com.rahul.kafkaspringboot.services.Producer;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping(value = "/kafka")
public class KafkaController {
private final Producer producer;
@Autowired
public KafkaController(Producer producer) {
this.producer = producer;
}
@PostMapping(value = "/publish")
public void sendMessageToKafkaTopic(@RequestParam("message") String message){
this.producer.sendMessage(message);
}
}We can then write the producer which uses Spring's KafkaTemplate to send the message to a topic named users, as shown below.
package com.rahul.kafkaspringboot.services;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Service;
@Service
public class Producer {
private static final Logger logger = LoggerFactory.getLogger(Producer.class);
private static final String TOPIC = "users";
@Autowired
private KafkaTemplate<String,String> kafkaTemplate;
public void sendMessage(String message){
logger.info(String.format("$$$ -> Producing message --> %s",message));
this.kafkaTemplate.send(TOPIC,message);
}
}We can also write the consumer as shown below, which consumes the message from the topic users and output the logs to the console.
package com.rahul.kafkaspringboot.services;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Service;
@Service
public class Consumer {
private final Logger logger = LoggerFactory.getLogger(Consumer.class);
@KafkaListener(topics = "users", groupId = "group_id")
public void consume(String message){
logger.info(String.format("$$$ -> Consumed Message -> %s",message));
}
}Now, we need a way to tell our application where to find the Kafka servers and create a topic and publish to it. We can do it using application.yaml as shown below.
server:
port: 9000
spring:
kafka:
consumer:
bootstrap-servers: localhost:9092
group-id: group-id
auto-offset-reset: earliest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
producer:
bootstrap-servers: localhost:9092
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializerNow, if we run the application and hit the endpoint as shown below, we have published an message to the topic.
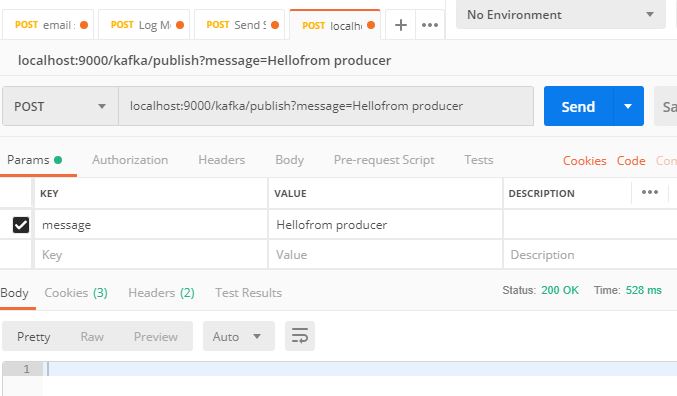
Now, if we check the logs from the console, it should print the message which was sent to the publish endpoint as seen below.

Summary
In this post, we have seen basic terminology used in the Kafka system. We also saw how easy it is to configure Kafka with Spring Boot. Most of the magic is done behind the scenes by Spring Boot. One easy and fast way is configuring Kafka-related details in the application.yml file, which is good if we change the Kafka clusters and we have to point the servers to new Kafka cluster address.
