In-Depth Understanding of Vector Search for RAG and Generative AI Applications

You might have used large language models like GPT-3.5, GPT-4o, or any of the other models, Mistral or Perplexity, and these large language models are awe-inspiring with what they can do and how much of a grasp they have of language.
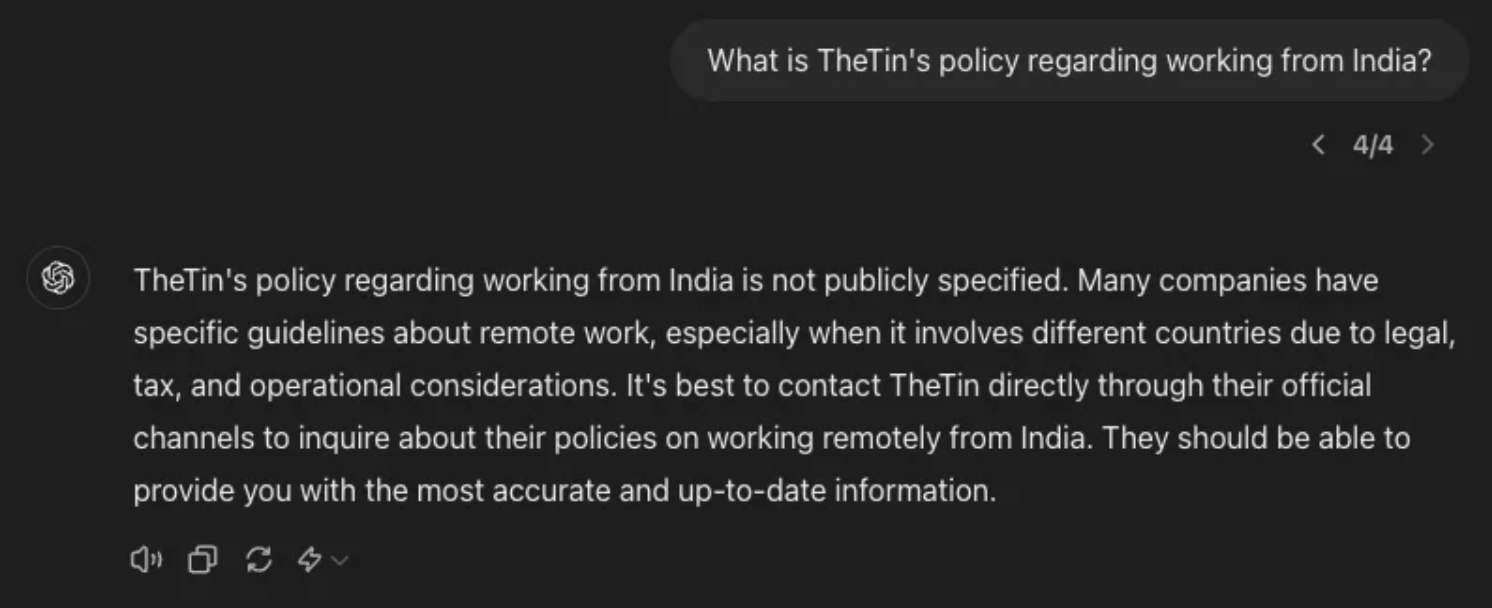
So, today I was chatting with an LLM, and I wanted to know about my company’s policy if I work from India instead of the UK. You can see I got a really generic answer, and then it asked me to consult my company directly.
The second question I asked was, “Who won the last T20 Worldcup?” and we all know that India won the ICC T20 2024 World Cup.

They’re large language models: they’re very good at next-word predictions; they’ve been trained on public knowledge up to a certain point; and they’re going to give us outdated information.
So, how can we incorporate domain knowledge into an LLM so that we can get it to answer those questions?
There are three main ways that people will go about incorporating domain knowledge:
- Prompt engineering: In context learning, we can derive an LLM to solve by putting in a lot of effort using prompt engineering; however, it will never be able to answer if it has never seen that information.
- Fine-tuning: Learning new skills; in this case, you start with the base model and train it on the data or skill you want it to achieve. And it will be really expensive to train the model on your data.
- Retrieval augmentation: Learning new facts temporarily to answer questions
How Do RAGs Work?
When I want to ask about any policy in my company, I will store it in a database and ask a question regarding the same. Our search system will search the document with the most relevant results and get back the information. We call this information "knowledge”. We will pass the knowledge and query to an LLM, and we will get the desired results.
We understand that if we provide LLM domain knowledge, then it will be able to answer perfectly. Now everything boils down to the retrieval part. Responses are only as good as retrieving data. So, let’s understand how we can improve document retrieval.
How Do We Search?
Traditional search has been keyword search-based, but then keyword search has this issue of the vocabulary gap. So, if I say I’m looking for underwater activities but the word "underwater" is nowhere in our knowledge base at all, then a keyword search would never match scuba and snorkeling. That’s why we want to have a vector-based retrieval as well, which can find things by semantic similarity. A vector-based search is going to help you realize that scuba diving and snorkeling are semantically similar to underwater and be able to return those. That’s why we’re talking about the importance of vector embedding today. So, let’s go deep into vectors.
Vector Embeddings
Vector Embeddings takes some input, like a word or a sentence, and then it sends it through through some embedding model. Then, you get back a list of floating point numbers and the amount of numbers is going to vary based on the actual model that you’re using.
So, here I have a table of the most common models we see. We have word2vec and that only takes an input of a single word at a time and the resulting vectors have a length of 300. What we’ve seen in the last few years is models based off of LLMs and these can take into much larger inputs which is really helpful because then we can search on more than just words.
The one that many people use now is OpenAI’s ada-002 which takes the text of up to 8,191 tokens and produces vectors that are 1536. You need to be consistent with what model you use, so you do want to make sure that you are using the same model for indexing the data and for searching.
You can learn more about the basics of vector search in my previous blog.
import json
import os
import azure.identity
import dotenv
import numpy as np
import openai
import pandas as pd
# Set up OpenAI client based on environment variables
dotenv.load_dotenv()
AZURE_OPENAI_SERVICE = os.getenv("AZURE_OPENAI_SERVICE")
AZURE_OPENAI_ADA_DEPLOYMENT = os.getenv("AZURE_OPENAI_ADA_DEPLOYMENT")
azure_credential = azure.identity.DefaultAzureCredential()
token_provider = azure.identity.get_bearer_token_provider(azure_credential,
"https://cognitiveservices.azure.com/.default")
openai_client = openai.AzureOpenAI(
api_version="2023-07-01-preview",
azure_endpoint=f"https://{AZURE_OPENAI_SERVICE}.openai.azure.com",
azure_ad_token_provider=token_provider)
In the above code, first, we will just set up a connection to OpenAI. I’m using Azure.
def get_embedding(text):
get_embeddings_response = openai_client.embeddings.create(model=AZURE_OPENAI_ADA_DEPLOYMENT, input=text)
return get_embeddings_response.data[0].embedding
def get_embeddings(sentences):
embeddings_response = openai_client.embeddings.create(model=AZURE_OPENAI_ADA_DEPLOYMENT, input=sentences)
return [embedding_object.embedding for embedding_object in embeddings_response.data]We have these functions here that are just wrappers for creating embeddings using the Ada 002 model:
# optimal size to embed is ~512 tokens
vector = get_embedding("A dog just walked past my house and yipped yipped like a Martian") # 8192 tokens limit

When we vectorize the sentence, “A dog just walked past my house and yipped yipped like a Martian”, we can write a long sentence and we can calculate the embedding. No matter how long is the sentence, we will get the embeddings of the same length which is 1536.

When we’re indexing documents for RAG chat apps we’re often going to be calculating embeddings for entire paragraphs up to 512 tokens is best practice. You don’t want to calculate the embedding for an entire book because that’s above the limit of 8192 tokens but also because if you try to embed long text then the nuance is going to be lost when you’re trying to compare one vector to another vector.
Vector Similarity
We compute embeddings so that we can calculate the similarity between inputs. The most common distance measurement is cosine similarity.
We can use other methods to calculate the distance between the vectors as well; however, it is recommended to use cosine similarity when we are using the ada-002 embedding model. Below is the formula to calculate the cosine similarities of 2 vectors.
def cosine_sim(a,b):
return dot(a,b)/(mag(a) * mag(b))How do you calculate cosine similarities? It’s the dot product over the product of the magnitudes. This tells us how similar the two vectors are. What is the angle between these two vectors in multi-dimensional space? Here we are visualizing in two-dimensional space because we can not visualize 1536 dimensions.
If the vectors are close, then there’s a very small Theta. That means you know your angle Theta is near zero, which means the cosine of the angle is near 1. As the vectors get farther and further away then your cosine goes down to zero and potentially even to negative 1:
def cosine_similarity(a, b):
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
sentences1 = ['The new movie is awesome',
'The new movie is awesome',
'The new movie is awesome']
sentences2 = ['djkshsjdkhfsjdfkhsd',
'This recent movie is so good',
'The new movie is awesome']
embeddings1 = get_embeddings(sentences1)
embeddings2 = get_embeddings(sentences2)
for i in range(len(sentences1)):
print(f"{sentences1[i]} \t\t {sentences2[i]} \t\t Score: {cosine_similarity(embeddings1[i], embeddings2[i]):.4f}")So here I’ve got a function to calculate the cosine similarity and I’m using NumPy to do the math for me since that’ll be nice and efficient. Now I’ve got three sentences that are all the same and then these sentences which are different. I’m going to get the embeddings for each of these sets of sentences and then just compare them to each other.
When the two sentences are the same then we see a cosine similarity of one we expect and then when a sentence is very similar, then we see a cosine similarity of 0.91 for sentence 2, and then sentence 1 is 0.74.
Now when you look at this it’s hard to think about whether the 0.75 means “This is pretty similar” or “Does it mean it’s pretty dissimilar?”.
When you do similarity with the Ada 002 model, there’s generally a very tight range between about .65 and 1(speaking from my experience and what I have seen so far), so this .75 is dissimilar.
Vector Search
Now the next step is to be able to do a vector search because everything we just did above was for similarity within the existing data set. What we want to be able to do is search for user queries.
We will compute the embedding vector for that query using the same model that we did our embeddings with for the knowledge base and then we look in our Vector database and find the K closest vectors for that user query vector.
# Load in vectors for movie titles
with open('openai_movies.json') as json_file:
movie_vectors = json.load(json_file)
# Compute vector for query
query = "My Neighbor Totoro"
embeddings_response = openai_client.embeddings.create(model=AZURE_OPENAI_ADA_DEPLOYMENT, input=[query])
vector = embeddings_response.data[0].embedding
# Compute cosine similarity between query and each movie title
scores = []
for movie in movie_vectors:
scores.append((movie, cosine_similarity(vector, movie_vectors[movie])))
# Display the top 10 results
df = pd.DataFrame(scores, columns=['Movie', 'Score'])
df = df.sort_values('Score', ascending=False)
df.head(10)I’ve got my query which is “My Neighbor Totoro”, because those movies were only Disney movies and as far as I know, “My Neighbor Totoro” is not a Disney movie. We’re going to do a comprehensive search here, so for every single movie in those vectors, we’re going to calculate the cosine similarity between the query vector and the vector for that movie and then we’re going to create a data frame, and sort it so that we can see the most similar ones.
Vector Database
We have learned how to use vector search. So moving on, how do we store our vectors? We want to store in some sort of database usually a vector database or a database that has a vector extension. We need something that can store vectors and ideally knows how to index vectors.
Below is a little example of Postgres code using the PG Vector extension:
CREATE EXTENSION vector;
CREATE TABLE items (id bigserial PRIMARY KEY,
embedding vector(1536));
INSERT INTO items (embedding) VALUES
('[0.0014701404143124819,
0.0034404152538627386,
-0.01280598994344729,...]');
CREATE INDEX ON items
USING hnsw (embedding vector_cosine_ops);
SELECT * FROM items
ORDER BY
embedding <=> '[-0.01266181, -0.0279284,...]'
LIMIT 5;Here we declare our Vector column and we say it’s going to be a vector with 1536 dimensions. Then we can insert our vectors in there and select where we’re checking to see which embedding is closest to the embedding that we’re interested in. This is an index using hnsw, which is an approximation algorithm.
On Azure, we have several options for Vector databases. We do have Vector support in the MongoDB vcore and also in the cosmos DB for Postgres. That’s a way you could keep your data where it is, for example; if you’re making a RAG chat application on your product inventory and your product inventory changes all the time and it’s already in the cosmos DB. Then it makes sense to take advantage of the vector capabilities there.
Otherwise, we have Azure AI search, a dedicated search technology that does not just do vector search but also keyword search. It has a lot more features. It can index things from many sources and this is what I generally recommend for a really good search quality.
I’m going to use Azure AI Search for the rest of this blog and we’re going to talk about all its features how it integrates and what makes it a really good retrieval system.
Azure AI Search
Azure AI Search is a search-as-a-service in the cloud, providing a rich search experience that is easy to integrate into custom applications, and easy to maintain because all infrastructure and administration is handled for you.
AI search has vector search which you can use via your Python SDK, which I’m going to use in the blog below, but also with semantic kernel LangChain, LlamaIndex, or any of those packages that you’re using. Most of them do have support for AI search as the RAG knowledge base.
To use AI Search, first, we will import the libraries.
import os
import azure.identity
import dotenv
import openai
from azure.search.documents import SearchClient
from azure.search.documents.indexes import SearchIndexClient
from azure.search.documents.indexes.models import (
HnswAlgorithmConfiguration,
HnswParameters,
SearchField,
SearchFieldDataType,
SearchIndex,
SimpleField,
VectorSearch,
VectorSearchAlgorithmKind,
VectorSearchProfile,
)
from azure.search.documents.models import VectorizedQuery
dotenv.load_dotenv()Initialize Azure search variables:
# Initialize Azure search variables
AZURE_SEARCH_SERVICE = os.getenv("AZURE_SEARCH_SERVICE")
AZURE_SEARCH_ENDPOINT = f"https://{AZURE_SEARCH_SERVICE}.search.windows.net"Set up OpenAI client based on environment variables:
# Set up OpenAI client based on environment variables
dotenv.load_dotenv()
AZURE_OPENAI_SERVICE = os.getenv("AZURE_OPENAI_SERVICE")
AZURE_OPENAI_ADA_DEPLOYMENT = os.getenv("AZURE_OPENAI_ADA_DEPLOYMENT")
azure_credential = azure.identity.DefaultAzureCredential()
token_provider = azure.identity.get_bearer_token_provider(azure_credential, "https://cognitiveservices.azure.com/.default")
openai_client = openai.AzureOpenAI(
api_version="2023-07-01-preview",
azure_endpoint=f"https://{AZURE_OPENAI_SERVICE}.openai.azure.com",
azure_ad_token_provider=token_provider)Defining a function to get the embeddings.
def get_embedding(text):
get_embeddings_response = openai_client.embeddings.create(model=AZURE_OPENAI_ADA_DEPLOYMENT, input=text)
return get_embeddings_response.data[0].embeddingCreating a Vector Index
Now we can create an index, we will name it “index-v1”. It has a couple of fields:
- ID field: Like our primary key
- Embedding field: That is going to be a vector and we tell it how many dimensions it’s going to have. Then we also give it a profile “
embedding_profile”.
AZURE_SEARCH_TINY_INDEX = "index-v1"
index = SearchIndex(
name=AZURE_SEARCH_TINY_INDEX,
fields=[
SimpleField(name="id", type=SearchFieldDataType.String, key=True),
SearchField(name="embedding",
type=SearchFieldDataType.Collection(SearchFieldDataType.Single),
searchable=True,
vector_search_dimensions=3,
vector_search_profile_name="embedding_profile")
],
vector_search=VectorSearch(
algorithms=[HnswAlgorithmConfiguration( # Hierachical Navigable Small World, IVF
name="hnsw_config",
kind=VectorSearchAlgorithmKind.HNSW,
parameters=HnswParameters(metric="cosine"),
)],
profiles=[VectorSearchProfile(name="embedding_profile", algorithm_configuration_name="hnsw_config")]
)
)
index_client = SearchIndexClient(endpoint=AZURE_SEARCH_ENDPOINT, credential=azure_credential)
index_client.create_index(index)In VecrotSearch() we will describe which algorithm or indexing strategy we want to use and we’re going to use hnsw, which stands for hierarchical navigable small world. There are a couple of other options like IVF, Exhaustive KNN, and some others.
AI search supports hnsw because it works well and they’re able to do it efficiently at scale. So, we’re going to say it’s hnsw and we can tell it like what metric to use for the similarity calculations. We can also customize other hnsw parameters if you’re familiar with them.
Search Using Vector Similarity
Once the vector is created with the index, now we just are going to upload the documents:
search_client = SearchClient(AZURE_SEARCH_ENDPOINT, AZURE_SEARCH_TINY_INDEX, credential=azure_credential)
search_client.upload_documents(documents=[
{"id": "1", "embedding": [1, 2, 3]},
{"id": "2", "embedding": [1, 1, 3]},
{"id": "3", "embedding": [4, 5, 6]}])Search Using Vector Similarity
Now will search through the documents. We’re not doing any sort of text search, we’re only doing a vector query search.
r = search_client.search(search_text=None, vector_queries=[
VectorizedQuery(vector=[-2, -1, -1], k_nearest_neighbors=3, fields="embedding")])
for doc in r:
print(f"id: {doc['id']}, score: {doc['@search.score']}")We’re asking for the 3 nearest neighbors and we’re telling it to search the “embedding_field” because you could have multiple Vector Fields.
We do this search and we can see the output scores. The score in this case is not necessarily the cosine similarity because the score can consider other things as well. There is some documentation about what score means in different situations.
r = search_client.search(search_text=None, vector_queries=[
VectorizedQuery(vector=[-2, -1, -1], k_nearest_neighbors=3, fields="embedding")])
for doc in r:
print(f"id: {doc['id']}, score: {doc['@search.score']}")We see much lower scores if we put vector = [-2, -1, -1]. I usually don’t look at the absolute scores myself you can but I typically look at the relative scores.
Searching on Large Index
AZURE_SEARCH_FULL_INDEX = "large-index"
search_client = SearchClient(AZURE_SEARCH_ENDPOINT, AZURE_SEARCH_FULL_INDEX, credential=azure_credential)
search_query = "learning about underwater activities"
search_vector = get_embedding(search_query)
r = search_client.search(search_text=None, top=5, vector_queries=[
VectorizedQuery(vector=search_vector, k_nearest_neighbors=5, fields="embedding")])
for doc in r:
content = doc["content"].replace("\n", " ")[:150]
print(f"Score: {doc['@search.score']:.5f}\tContent:{content}")Vector Search Strategies
During vector query execution, the search engine searches for similar vectors to determine which candidates to return in search results. Depending on how you indexed the vector information, the search for suitable matches can be extensive or limited to near neighbors to speed up processing. Once candidates have been identified, similarity criteria are utilized to rank each result based on the strength of the match.
There are 2 famous vector search algorithms in Azure:
- Exhaustive KNN: Runs a brute-force search across the whole vector space
- HNSW runs an approximate nearest neighbour (ANN) search.
Only vector fields labeled as searchable in the index or searchFields in the query are used for searching and scoring.
When To Use Exhaustive KNN
Exhaustive KNN computes the distances between all pairs of data points and identifies the precise k nearest neighbors for a query point. It is designed for cases in which strong recall matters most and users are ready to tolerate the trade-offs in query latency. Because exhaustive KNN is computationally demanding, it should be used with small to medium datasets or when precision requirements outweigh query efficiency considerations.
r = search_client.search(
None,
top = 5,
vector_queries = [VectorizedQuery(
vector = search_vector,
k_nearest_neighbour = 5,
field = "embedding")])A secondary use case is to create a dataset to test the approximate closest neighbor algorithm’s recall. Exhaustive KNN can be used to generate a ground truth collection of nearest neighbors.
When To Use HNSW
During indexing, HNSW generates additional data structures to facilitate speedier search, arranging data points into a hierarchical graph structure. HNSW includes various configuration options that can be adjusted to meet your search application’s throughput, latency, and recall requirements. For example, at query time, you can specify options for exhaustive search, even if the vector field is HNSW-indexed.
r = search_client.search(
None,
top = 5,
vector_queries = [VectorizedQuery(
vector = search_vector,
k_nearest_neighbour = 5,
field = "embedding",
exhaustive = True)])During query execution, HNSW provides quick neighbor queries by traversing the graph. This method strikes a balance between search precision and computing efficiency. HNSW is suggested for most circumstances because of its efficiency when searching massive data sets.
Filtered Vector Search
Now we have other capabilities when we’re doing Vector queries. You can set vector filter modes on a vector query to specify whether you want to filter before or after query execution.
Filters determine the scope of a vector query. Filters are set on and iterate over nonvector string and numeric fields attributed as filterable in the index, but the purpose of a filter determines what the vector query executes over: the entire searchable space, or the contents of a search result.
With a vector query, one thing you have to keep in mind is whether you should be doing a pre-filter or post-filter. You generally want to do a pre-filter: this means that you’re first doing this filter and then doing the vector search. The reason you want this is that if you did a post filter, there are some chances that you might not find a relevant vector match after that which will return empty results. Instead, what you want to do is filter all the documents and then query the vectors.
r = search_client.search(
None,
top = 5,
vector_queries = [VectorizedQuery(
vector = query_vector,
k_nearest_neighbour = 5,
field = "embedding",)]
vector_filter_mode = VectorFilterMode.PRE_FILTER,
filter = "your filter here"
)Multi-Vector Search
We also get support for multi-vector scenarios; for example, if you have an embedding for the title of a document that is different from the embedding for the body of the document. You can search these separately.
We use this a lot if we’re doing multimodal queries. If we have both an image embedding and a text embedding, we might want to search both of those embeddings.
Azure AI search not only supports text search but also image and audio search as well. Let’s see an example of an image search.
import os
import dotenv
from azure.identity import DefaultAzureCredential, get_bearer_token_provider
from azure.search.documents import SearchClient
from azure.search.documents.indexes import SearchIndexClient
from azure.search.documents.indexes.models import (
HnswAlgorithmConfiguration,
HnswParameters,
SearchField,
SearchFieldDataType,
SearchIndex,
SimpleField,
VectorSearch,
VectorSearchAlgorithmKind,
VectorSearchProfile,
)
from azure.search.documents.models import VectorizedQuery
dotenv.load_dotenv()
AZURE_SEARCH_SERVICE = os.getenv("AZURE_SEARCH_SERVICE")
AZURE_SEARCH_ENDPOINT = f"https://{AZURE_SEARCH_SERVICE}.search.windows.net"
AZURE_SEARCH_IMAGES_INDEX = "images-index4"
azure_credential = DefaultAzureCredential(exclude_shared_token_cache_credential=True)
search_client = SearchClient(AZURE_SEARCH_ENDPOINT, AZURE_SEARCH_IMAGES_INDEX, credential=azure_credential)Creating a Search Index for Images
We create a search index for images. This one has ID = file name and embedding. This time, the vector search dimensions are 1024 because that is the dimensions of the embeddings that come from the computer vision model, so it’s a slightly different length than the ada-002. Everything else is the same.
index = SearchIndex(
name=AZURE_SEARCH_IMAGES_INDEX,
fields=[
SimpleField(name="id", type=SearchFieldDataType.String, key=True),
SimpleField(name="filename", type=SearchFieldDataType.String),
SearchField(name="embedding",
type=SearchFieldDataType.Collection(SearchFieldDataType.Single),
searchable=True,
vector_search_dimensions=1024,
vector_search_profile_name="embedding_profile")
],
vector_search=VectorSearch(
algorithms=[HnswAlgorithmConfiguration(
name="hnsw_config",
kind=VectorSearchAlgorithmKind.HNSW,
parameters=HnswParameters(metric="cosine"),
)],
profiles=[VectorSearchProfile(name="embedding_profile", algorithm_configuration_name="hnsw_config")]
)
)
index_client = SearchIndexClient(endpoint=AZURE_SEARCH_ENDPOINT, credential=azure_credential)
index_client.create_index(index)Configure Azure Computer Vision Multi-Modal Embeddings API
Here we are integrating with the Azure Computer Vision service to obtain embeddings for images and text. It uses a bearer token for authentication, retrieves model parameters for the latest version, and defines functions to get the embeddings. The `get_image_embedding` function reads an image file, determines its MIME type, and sends a POST request to the Azure service, handling errors by printing the status code and response if it fails. Similarly, the `get_text_embedding` function sends a text string to the service to retrieve its vector representation. Both functions return the resulting vector embeddings.
import mimetypes
import os
import requests
from PIL import Image
token_provider = get_bearer_token_provider(azure_credential, "https://cognitiveservices.azure.com/.default")
AZURE_COMPUTERVISION_SERVICE = os.getenv("AZURE_COMPUTERVISION_SERVICE")
AZURE_COMPUTER_VISION_URL = f"https://{AZURE_COMPUTERVISION_SERVICE}.cognitiveservices.azure.com/computervision/retrieval"
def get_model_params():
return {"api-version": "2023-02-01-preview", "modelVersion": "latest"}
def get_auth_headers():
return {"Authorization": "Bearer " + token_provider()}
def get_image_embedding(image_file):
mimetype = mimetypes.guess_type(image_file)[0]
url = f"{AZURE_COMPUTER_VISION_URL}:vectorizeImage"
headers = get_auth_headers()
headers["Content-Type"] = mimetype
# add error checking
response = requests.post(url, headers=headers, params=get_model_params(), data=open(image_file, "rb"))
if response.status_code != 200:
print(image_file, response.status_code, response.json())
return response.json()["vector"]
def get_text_embedding(text):
url = f"{AZURE_COMPUTER_VISION_URL}:vectorizeText"
return requests.post(url, headers=get_auth_headers(), params=get_model_params(),
json={"text": text}).json()["vector"]Add Image Vector To Search Index
Now we process each image file in the “product_images” directory. For each image, it calls the get_image_embedding function to get the image's vector representation (embedding). Then, it uploads this embedding to a search client along with the image's filename and a unique identifier (derived from the filename without its extension). This allows the images to be indexed and searched based on their content.
for image_file in os.listdir("product_images"):
image_embedding = get_image_embedding(f"product_images/{image_file}")
search_client.upload_documents(documents=[{
"id": image_file.split(".")[0],
"filename": image_file,
"embedding": image_embedding}])Query Using an Image
query_image = "query_images/tealightsand_side.jpg"
Image.open(query_image)query_vector = get_image_embedding(query_image)
r = search_client.search(None, vector_queries=[
VectorizedQuery(vector=query_vector, k_nearest_neighbors=3, fields="embedding")])
all = [doc["filename"] for doc in r]
for filename in all:
print(filename)We are getting the embedding for a query image and searching for the top 3 most similar image embeddings using a search client. It then prints the filenames of the matching images.
Image.open("product_images/" + all[0])Now let’s take it to the next level and search images using text.
query_vector = get_text_embedding("lion king")
r = search_client.search(None, vector_queries=[
VectorizedQuery(vector=query_vector, k_nearest_neighbors=3, fields="embedding")])
all = [doc["filename"] for doc in r]
for filename in all:
print(filename)
Image.open("product_images/" + all[0])If you see here, we searched for “Lion King." Not only did it get the reference of Lion King, but also was able to read the texts on images and bring back the best match from the dataset.
Conclusion
I hope you enjoyed reading the blog and learned something new. In the upcoming blogs, I will be talking more about Azure AI Search.
Let’s connect on LinkedIn or GitHub. Thank you for reading!
