Scatter-Gather Pattern

Have you ever encountered a use case where you need to connect with multiple sources and aggregate their responses into a single response? If yes, then you already have some understanding of scatter-gather. Scatter-gather is an enterprise integration pattern, a design pattern to scale distributed systems or services running on the cloud, or a way to get a solution to the problem — “How to write code to fetch data from N sources?”.
The scatter-gather pattern provides guidelines to spread the load in distributed systems or achieve parallelism and reduce the response time of applications handling requests from multiple users. In this article, we’ll investigate this pattern in-depth. I’ll solve one simple problem by applying scatter-gather and later discuss the applicability of this pattern for complex use cases.
What Are the Features of the Scatter Gather Pattern?
- The scatter-gather pattern is applicable when we can divide a big task into smaller, independent sub-tasks that can be executed simultaneously by multiple cores or distributed computing nodes.
- Independent sub-tasks should be executed asynchronously in a predefined time window.
- The scatter-gather pattern is hierarchical in nature, and it is useful while designing systems for high scalability deployed in the cloud.
- Scatter-gather could be enhanced further with messaging patterns using Kafka, RabbitMQ, NATS, or other famous public cloud providers’ messaging services.
We’ll understand each feature with a simple example or use case. We'll see how this pattern is useful to solve
How To Fetch Data From N Sources
Let us take an example to understand the problem where the pattern can be efficient. Our use case is to build an application to list hotel prices. People travel worldwide and want a way to compare hotel prices at a certain location. Here is a high-level design for the requirement.
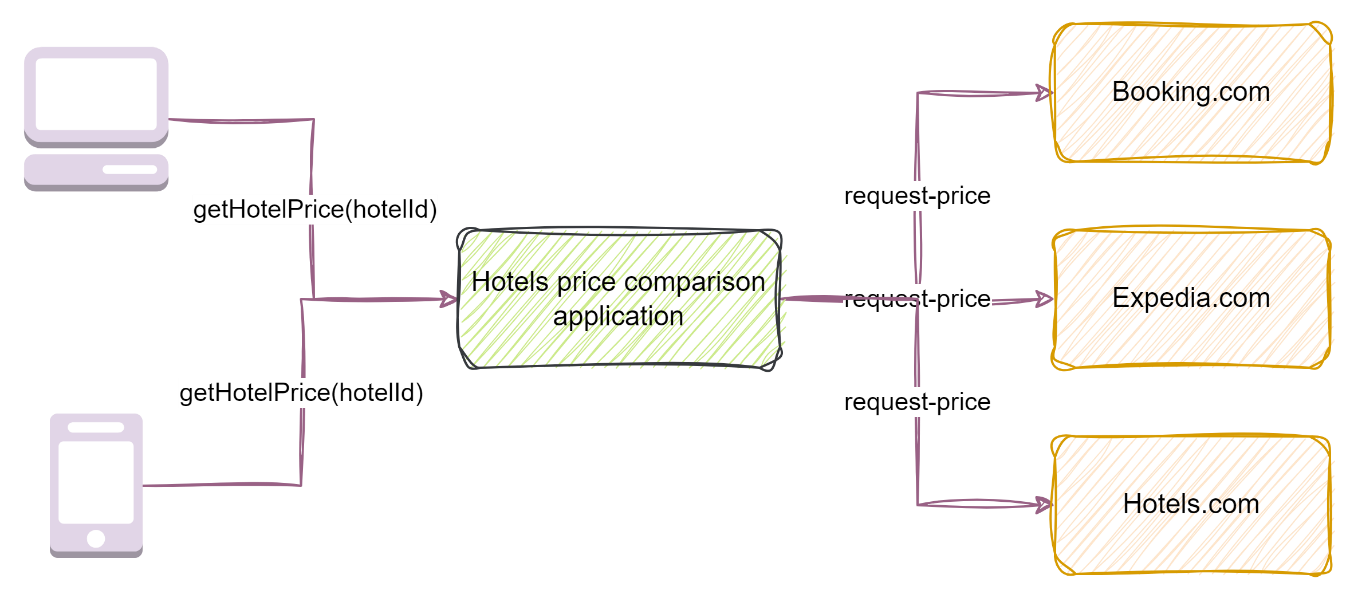
Figure 1: High-level design of hotel price comparison application
So, our main requirement is to “Write code to retrieve hotel prices from 3 hotel price listing websites?” We’ll solve this problem for a case where a single service instance is running and serving our clients logged in from mobile Apps or laptops. I am using Java as a programming language to solve this problem. You can use your preferred programming language to solve the problem.
Approach 1
Make three serial HTTP calls to Booking, Expedia, and Hotels websites and return prices to the user. These are the steps involved:
getHotelPrice()method running on the main thread of our hotels' price comparison service.- Whenever a user is calling
getHotelPrice()method with the hotel name or ID by an API, our service makes HTTP call to Booking.com and then waits for a response, then 2nd call to Expedia.com and again waiting for a response, and so forth. - At last, the service will return aggregated hotel prices from all websites.
This is a simple but inefficient approach to solving the problem, as we are wasting CPU resources while waiting for responses from hotel listing websites.
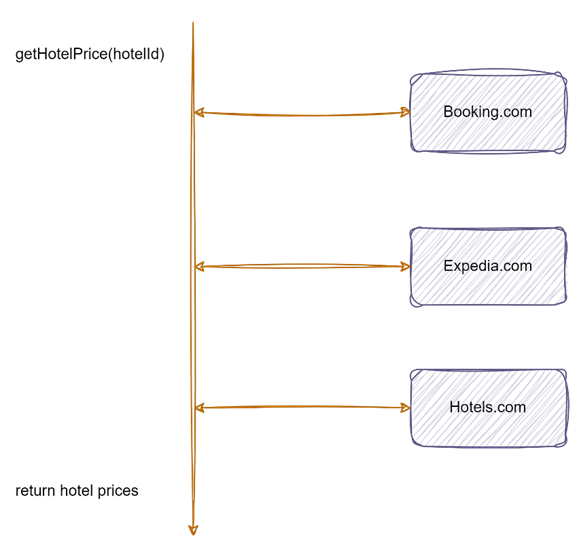
Figure 2: Sequential calls to hotel price listing websites
Approach 2
Our service makes 3 HTTP calls to Booking.com, Expedia.com, and Hotels.com at the same time and then waits for responses. This is a better solution than approach one as we are utilizing CPU resources effectively, but still, there is an issue.
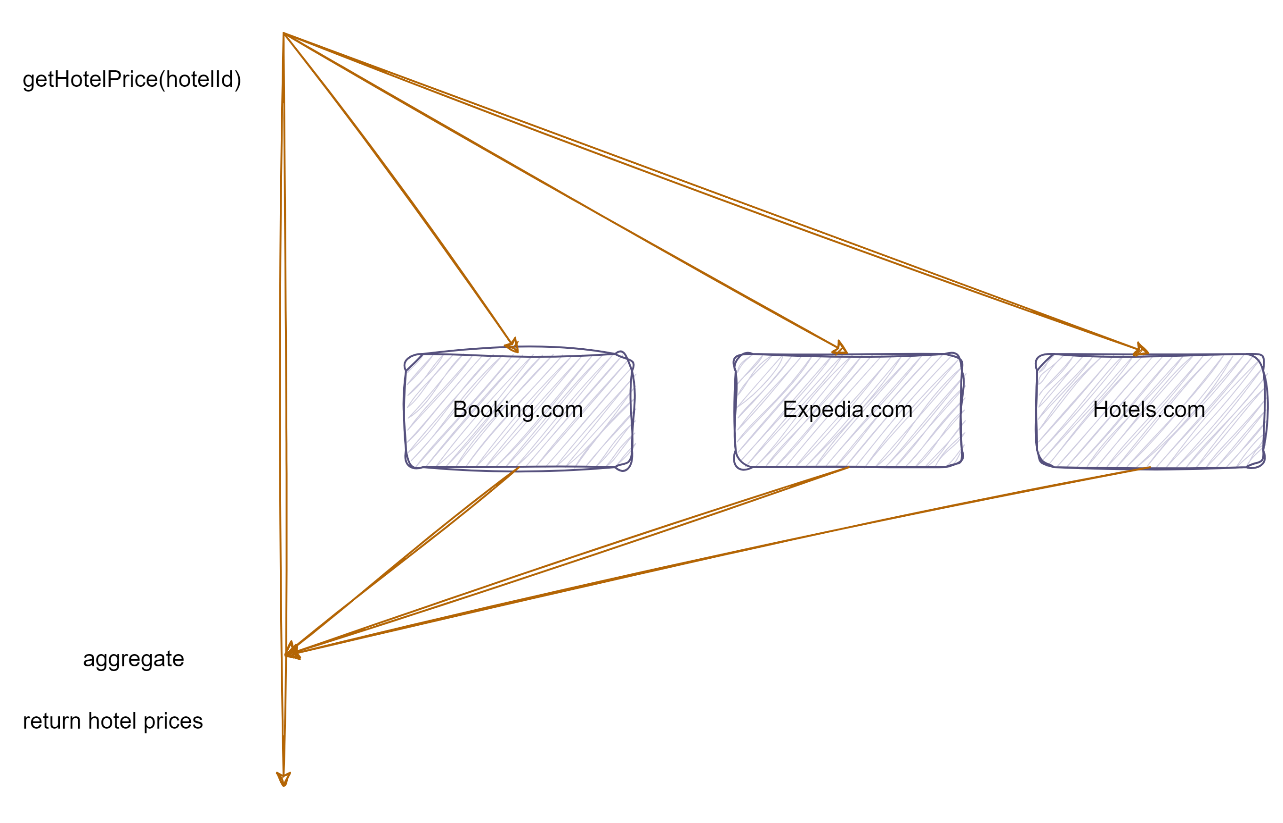
Figure 3: Parallel calls to hotel price listing websites
HTTP call is an I/O bound operation, and it is possible that one of the hotel listing websites is not available (due to official downtime or some other error) when our hotels' price comparison service is requesting for hotel price. It’s undesirable to ask the client to wait forever to get hotel prices. Let’s tweak our problem statement to “Write code to retrieve hotel prices from 3 hotel price listing websites, waiting for a maximum of 2 seconds?” By introducing a 2-second wait timeout, our service won’t wait forever for the response from unavailable websites. Our service may return a partial response (ignoring delayed or unavailable responses) after waiting 2 seconds.
Please show me some code.
There are different ways to solve this problem in Java, e.g., futures/callable, synchronization barrier phaser, and concurrent locks and conditions. I am writing code using CompletableFuture. CompletableFuture represents a future result of an asynchronous operation executed in a different thread. Let's break down our solution:
- Write a service to list the price of a given hotel from three hotel prices lister platforms: Booking, Expedia, and Hotels.
- Service should be able to return a partial response when one of the hotel prices lister platforms is unavailable or slow.
Step 1: Create an enumeration of HotelsListerPlatform
public enum HotelsListerPlatform {
BOOKING,
EXPEDIA,
HOTELS
}Step 2: Create an interface with the name PriceFetcher. We’ll create three separate classes for Booking, Expedia, and Hotels to implement this interface.
public interface PriceFetcher {
CompletableFuture<Double> fetchHotelPrice(String hotelId);
}Step 3: Create a factory to resolve the hotel lister platform name in our HotelsPriceComparisonService class
public class HotelsListerFactory {
private static final Map<HotelsListerPlatform, PriceFetcher> priceFetcherFactory = Map.of(
HotelsListerPlatform.BOOKING, new BookingPriceFetcher(),
HotelsListerPlatform.EXPEDIA, new ExpediaPriceFetcher(),
HotelsListerPlatform.HOTELS, new HotelsPriceFetcher()
);
public static PriceFetcher getPriceFetcher(HotelsListerPlatform hotelsListerPlatform) {
return priceFetcherFactory.get(hotelsListerPlatform);
}
}Step 4: Classes implementing the interface (We are introducing an artificial delay in HotelsPriceFetcher class to simulate the slowness of hotels com API)
public class BookingPriceFetcher implements PriceFetcher {
@Override
public CompletableFuture<Double> fetchHotelPrice(String hotelId) {
return CompletableFuture.supplyAsync(() -> 100.15, CompletableFuture.delayedExecutor(100, TimeUnit.MILLISECONDS));
}
}
public class ExpediaPriceFetcher implements PriceFetcher {
@Override
public CompletableFuture<Double> fetchHotelPrice(String hotelId) {
return CompletableFuture.supplyAsync(() -> 110.15, CompletableFuture.delayedExecutor(100, TimeUnit.MILLISECONDS));
}
}
public class HotelsPriceFetcher implements PriceFetcher {
@Override
public CompletableFuture<Double> fetchHotelPrice(String hotelId) {
return CompletableFuture.supplyAsync(() -> {
try {
// Artificial delay to simulate slow response
Thread.sleep(3000);
} catch (InterruptedException ex) {
ex.printStackTrace();
}
return 105.25;
}, CompletableFuture.delayedExecutor(100, TimeUnit.MILLISECONDS));
}
}Step 5: Create a class to write the business logic of scatter-gather using CompletableFuture and timeout
public class HotelsPriceComparisonService {
public List<Double> fetchHotelPrices(String hotelId, long timeoutInSeconds) {
// List of CompletableFuture ready to be called when client need the data
List<CompletableFuture<Double>> hotelPricesFutures = Stream.of(HotelsListerPlatform.values())
.map(hotelsListerPlatform -> {
PriceFetcher hotelsPriceFetcher = HotelsListerFactory.getPriceFetcher(hotelsListerPlatform);
return hotelsPriceFetcher.fetchHotelPrice(hotelId);
})
.toList();
try {
// Returns a new CompletableFuture that is completed when given list of CompletableFutures complete
CompletableFuture.allOf(hotelPricesFutures.toArray(new CompletableFuture[hotelPricesFutures.size()]))
.get(timeoutInSeconds, TimeUnit.SECONDS);
} catch (Exception ex) {
// You may log exception here
}
// Returns complete or partial (when one of the hotels listing websites is not available) list of prices
return hotelPricesFutures
.stream()
// Get the value from successfully completed future
.filter(future -> future.isDone() && !future.isCompletedExceptionally())
.map(CompletableFuture::join)
.toList();
}
}Step 6: Write some unit tests to verify our business logic.
@Test
public void shouldReturnResponsesFromAllHotelsListerPlatformWhenTimeoutIsMoreThanSlowestPlatform() {
HotelsPriceComparisonService hotelsPriceComparisonService = new HotelsPriceComparisonService();
List<Double> hotelPrices = hotelsPriceComparisonService.fetchHotelPrices("Hyatt", 4);
Assertions.assertEquals(hotelPrices, List.of(100.15, 110.15, 105.25));
}
@Test
public void shouldReturnPartialResponseWhenTimeoutIsMoreThanSlowestPlatform() {
HotelsPriceComparisonService hotelsPriceComparisonService = new HotelsPriceComparisonService();
List<Double> hotelPrices = hotelsPriceComparisonService.fetchHotelPrices("Hyatt", 2);
Assertions.assertEquals(hotelPrices, List.of(100.15, 110.15));
}Congratulations, you have successfully implemented a simpler version of Scatter-Gather. In real scenarios, problems are not as simple as calling three websites to get hotel prices. Real-world applications are a mix of CPU-bound and I/O-bound tasks where a single process or machine could be a bottleneck due to limited memory, network, or disk bandwidth. Instead of parallelizing an application across multiple cores on a single machine, we can use the scatter-gather pattern to parallelize requests across multiple processes on many different machines. This will ensure that the bottleneck in our process continues to be the CPU since the memory, network, and disk bandwidth are all spread across different machines.
Hierarchical Scatter-Gather
In the last section, we have implemented the simplest scatter-gather. Let’s assume that our hotel price comparison website is getting popular, and it is successfully handling loads from a small number of users in certain locations. Now, we are planning to expand our business to many users, and with a lot many hotels price lister platforms. We want to expand our business to the USA to help tourists plan their hotel stays while they are on vacations around different states in the USA. The simplest version of the scatter-gather won’t be able to sustain this load, but the hierarchical nature of the scatter-gather will help us to solve this problem.
Before delving into this complex scalability problem of our hotel price comparison website, first understand hierarchical scatter-gather with a simple example.
Imagine an organization running a set of surveys for all employees. These surveys will provide opportunities for all employees to share 360-degree feedback about the organization's culture and practices. This is a perfect example to demonstrate. The main challenge here is to distribute surveys to all employees and gather back results efficiently. The binary tree data structure can be used to solve this problem.
- A binary tree node represents an employee.
- Survey tasks are divided among employees in a full binary tree.
- Each employee processes their assigned survey tasks.
- Results are gathered from leaf nodes up to the root of the tree.
// A recursive method to create binary tree
private static WorkerTreeNode createBinaryTree(int depth) {
if (depth <= 0)
return null;
var node = new WorkerTreeNode(new Worker(UUID.randomUUID().toString()));
node.setLeft(createBinaryTree(depth - 1));
node.setRight(createBinaryTree(depth - 1));
return node;
}
// Scatter method to assign list of tasks to employee node in binary tree
private static void scatter(List<SurveyTask> tasks, WorkerTreeNode node) {
if (node == null)
return;
tasks.stream().forEach(task -> node.worker.tasks.add(task));
scatter(tasks, node.left);
scatter(tasks, node.right);
}
// Gather method to aggregate results from employee node in binary tree
private static List<CompletableFuture<String>> gather(WorkerTreeNode node) {
if (node == null)
return new ArrayList<>();
var leftResultsTask = gather(node.left);
var rightResultsTask = gather(node.right);
var results = new ArrayList<CompletableFuture<String>>();
node.worker.tasks.forEach(task -> results.add(node.worker.executeTask(task)));
results.addAll(leftResultsTask);
results.addAll(rightResultsTask);
return results;
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
var surveyTasks = IntStream.rangeClosed(1, 3).mapToObj(i -> new SurveyTask(i, String.format("Data for survey task %d", i))).toList();
//Create a binary tree
var root = createBinaryTree(2);
//Scatter surveyTasks to workers in the tree
scatter(surveyTasks, root);
//Gather results from all workers in the tree
var gatheredResults = gather(root);
var results = CompletableFuture.allOf(gatheredResults.toArray(new CompletableFuture<?>[0]))
.thenApply(v -> gatheredResults.stream()
.map(CompletableFuture::join)
.collect(Collectors.toList())
).get();
System.out.println(String.join("\n", results));
}The screenshot below shows the output after running scatter and gather phases. As you can see, there are three employees, and each employee is doing three survey tasks, so there are a total of 9 entries in the output.

Hierarchical Scatter-Gather To Scale Workloads in Cloud Infrastructure
The distribution of tasks using a hierarchical or tree structure is an application of a scatter-gather pattern to scale workloads in a distributed system environment or cloud. In this tree structure, when the root node receives an incoming request from any client, it divides it into multiple independent tasks and assigns them to available leaf nodes, the “scatter” phase.
Leaf nodes are multiple machines or containers available on a distributed network. Each leaf node works individually and in parallel on its computation, generating a fraction of the response. Once they have completed their task, each leaf sends its partial response back to the root, which collects them all as part of the “gather” phase. The root node then combines the partial responses and returns the result to the client. The diagram below illustrates it.
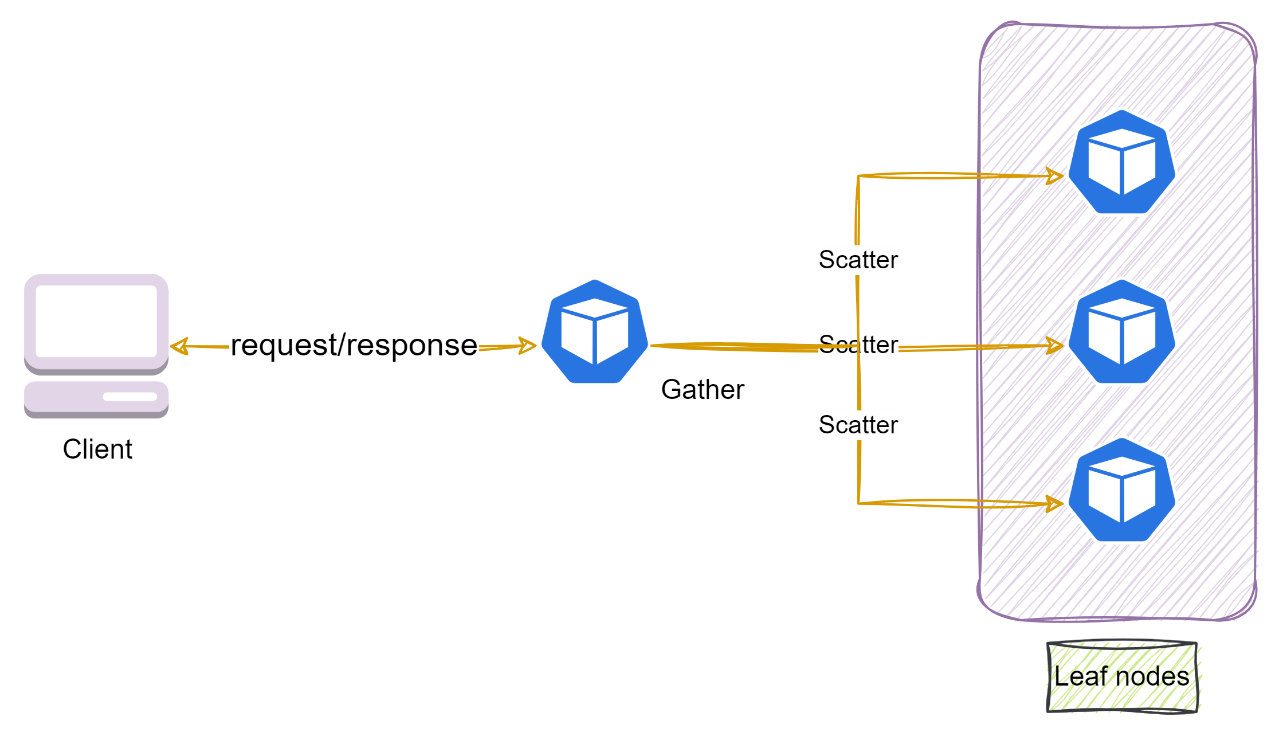
Figure 4: Hierarchical scatter-gather using Kubernetes pods
The strategy enables us to exploit cloud infrastructure to allocate as many virtual machines, compute nodes, or Kubernetes pods as needed and scale horizontally. If a particular leaf node is slow, the root node can also reshuffle the load for a desired response time.
Now, we are in a position to solve the scalability problem of our hotel price comparison website by applying hierarchical scatter-gather. Our goal is to launch our website in the USA. To improve the performance of our application, we can divide the USA into New England, Great Lakes, Midwest, Northwest, Southwest, South, and Southeast. When a request arrives, the root node divides it and assigns it to the seven leaf nodes to process in parallel. Each leaf node is responsible for a specific region in the country and returns a list of all hotel prices to that region. Finally, the root node merges all the results to create a final list to show to the customer.
There are two major problems with this approach:
- Slow or non-responsive leaf nodes: Even though our application is using a cloud infrastructure, there is always a likelihood that machines may become unavailable due to network or infrastructure issues (see fallacies of distributed systems). Moreover, our leaf nodes are communicating to external hotel price lister websites that may not respond swiftly. But there is nothing to worry about, as we have solved this problem while implementing the simple version of our problem by comparing prices from three hotels' lister websites. You guessed it right: timeouts, the root node must set an upper limit on the desired response time. If a leaf node does not respond within that time, the root node can ignore it and return a partially collected response from available leaf nodes to the user.
- Tight coupling between root node and leaf nodes: Our implementation is suffering from runtime tight coupling between root node and leaf nodes where the availability of our hotel price comparison website is impacted by the availability of leaf nodes and third-party hotel price lister websites. A splendid way to eliminate tight runtime coupling is to use message brokers. The message broker acts as an intermediary, holding the message until dependent services are ready to process it. This asynchronous approach allows services to operate independently, breaking the tight coupling that exists in the initial solution, i.e., synchronous https-based communication.
Loosely Coupled Hierarchical Scatter-Gather
There are two types of messaging concepts that can be implemented between root nodes and leaf nodes to remove runtime-tight coupling.
Topic: The topic works on the publish-subscribe model. A single message can be received by many subscribers, i.e., the root node is asking for hotel prices from all leaf nodes distributed across seven regions in the USA. The topic may also store the message so that it can be read later again.
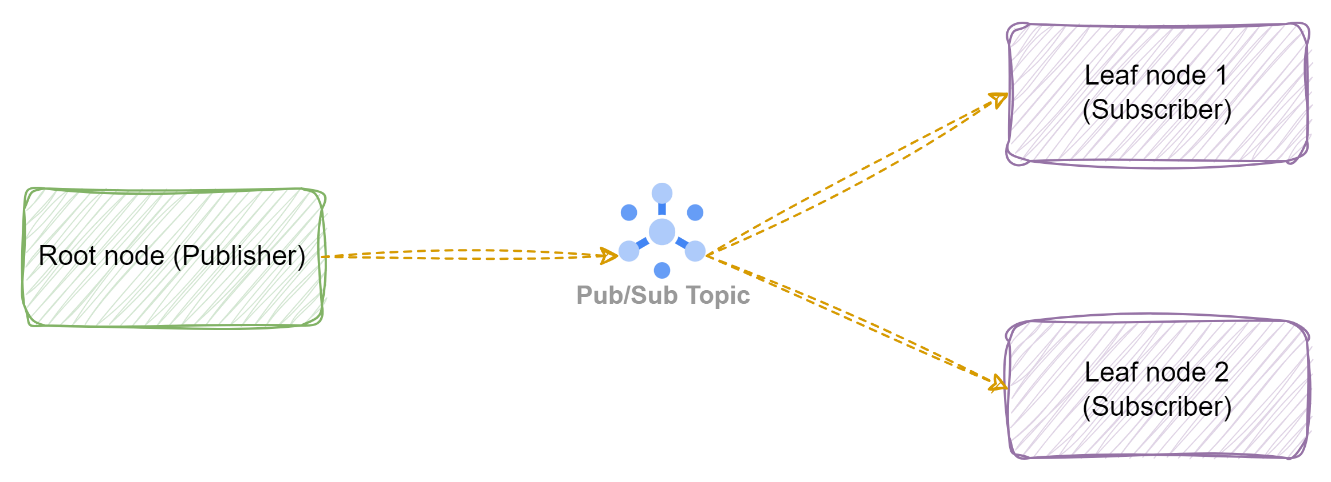
Figure 5: Publish Subscribe communication using Topic
Queue: Queue works on a point-to-point communication model. Queue sends the message to one consumer only, where messages will be queued until the next available node consumes a message from the queue one at a time. Message in queue is deleted as soon as it is consumed by one consumer node. The queue can work with acknowledgment or without acknowledgment (fire and forget) about the successful consumption of the message.
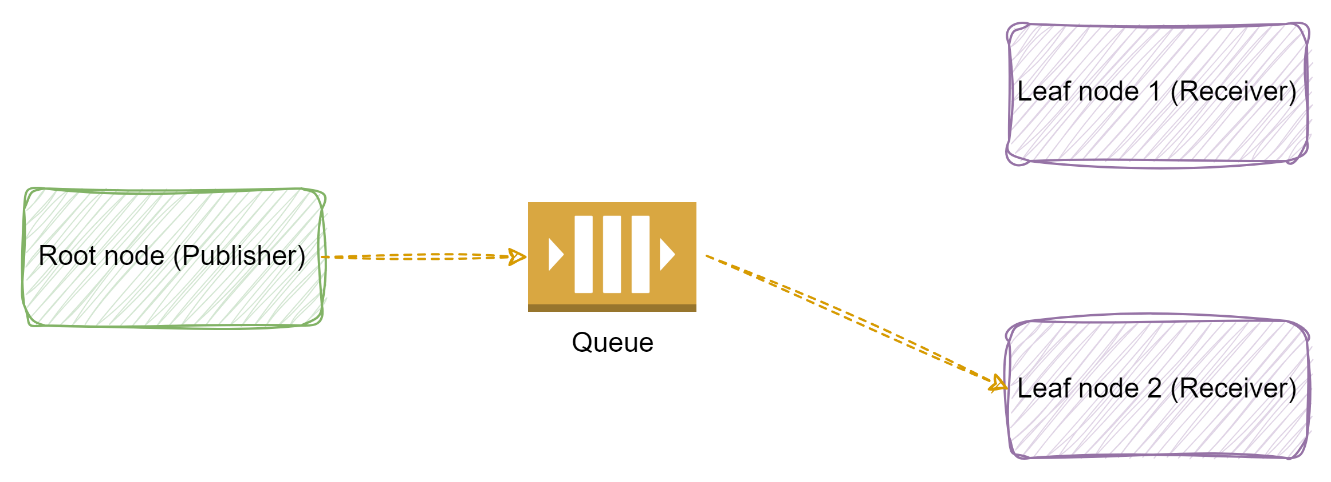
Figure 6: Point to Point communication using Queue
Now, we can use these messaging concepts to scale our hotel price comparison application. A combination of topic and queue could help to achieve runtime loose coupling between root and leaf nodes. Whenever there is an incoming request for hotel prices at a certain location, the root node broadcasts messages to the leaf nodes. All working leaf nodes can then subscribe to the incoming message, process it, call external hotel price lister platforms, and publish their hotel price results to a response queue. The root node can consume the results from that queue, aggregate them, and respond to the user. The figure below shows the implementation.
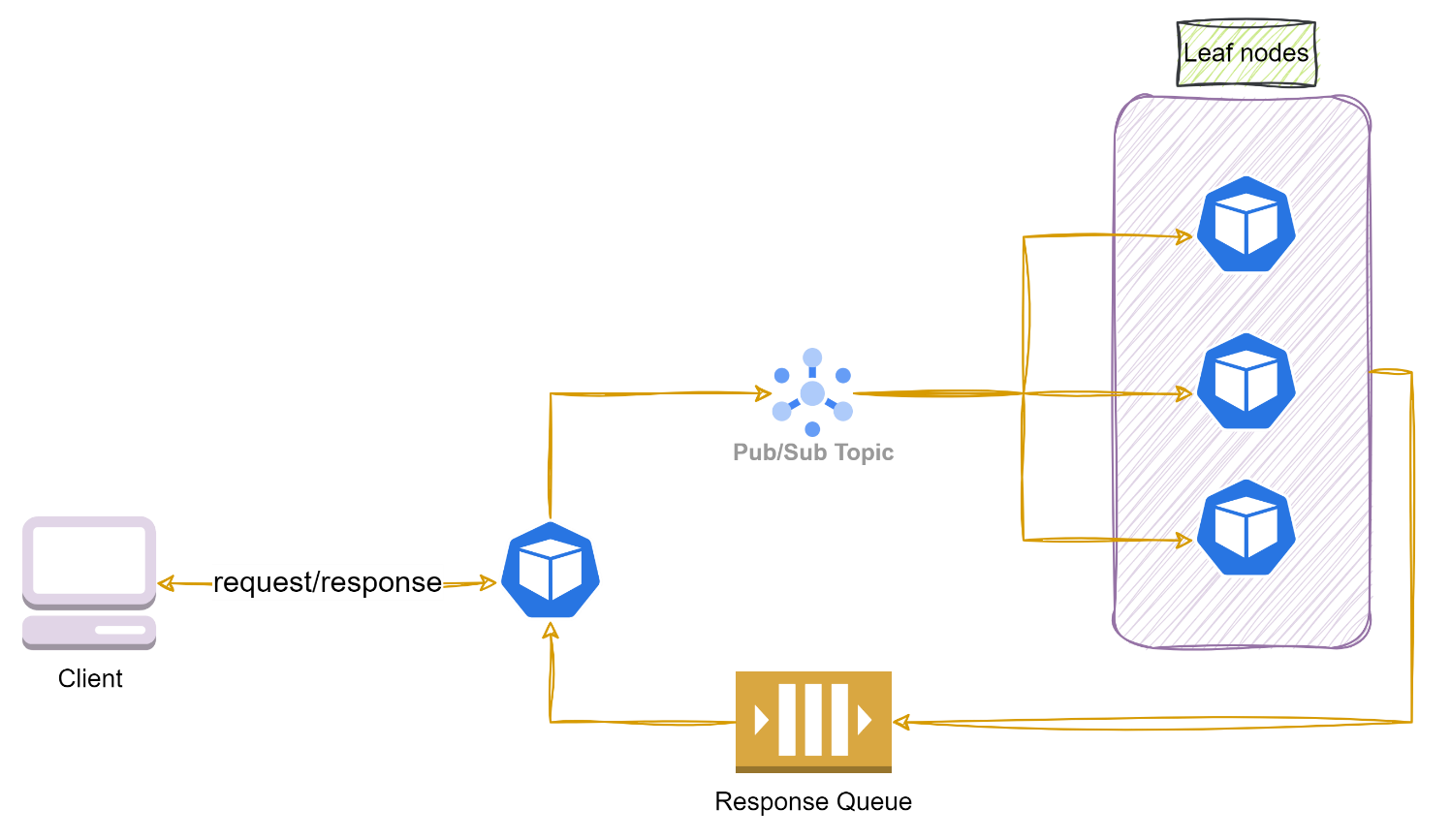
Figure 7: Loosely coupled scatter-gather with topic and queue
What Is the Right Number for Leaf Nodes?
We have come up with a possible solution to scale hotel price comparison application, but there is no silver bullet to solve all problems while designing software systems. Scatter-gather provides a way to parallelize load in several leaf nodes, but increased parallelization comes with a cost, and thus, choosing the right number of leaf nodes is crucial while implementing distributed systems.
- Nonlinear performance gain: There is an overhead involved while serving HTTP requests from clients, i.e., parsing HTTP requests, processing, and routing messages to topics and queues. This overhead cost is negligible with a small number of leaf nodes, but as parallelization continues and you add more leaf nodes, this overhead eventually dominates the compute cost. So, adding more leaf nodes is not proportional to gaining more performance.
- Sluggish leaf nodes: the root node waits for the results from all leaf nodes, which means that our application cannot be faster than the slowest leaf node. It is generally known as the “straggler node” problem, and it can substantially delay the overall response time due to a bunch of slow nodes or even a single node.
But still, our question is unanswered: what is the right number of leaf nodes? Well, it depends on the commitment towards the end user, i.e., Service Level Agreement (SLA). When our hotel price comparison application makes a promise to be available 96 % (57m 36s allowed downtime per day), then it needs a precise numerical target of availability from dependent systems, and that numerical target is Service Level Objective (SLO). There is a great post from Google about explaining these terms.
Example: How many nodes are needed to achieve 96% availability SLA?
Let’s assume that we are running our application on a Kubernetes cluster where the cluster’s nodes are hosted in a public cloud provider machine, and 99% availability SLA is guaranteed for these machines. Composite SLA calculation is all about simple Mathematics, e.g., addition, subtraction, multiplication, and probability. In simple terms, to calculate composite availability SLA: -
- Multiply availability for serial dependencies.
- Multiply unavailability for parallel dependencies.
Composite SLA of our hotel price comparison application = 0.99 * 0.99 * 0.99 * 0.99 * 0.99 = ~0.96, i.e., five leaf nodes are enough to get the desired SLA.
Let’s see what happens when we add another leaf node = 0.99 * 0.99 * 0.99 * 0.99 * 0.99 * 0.99 = ~0.95, i.e., adding an extra leaf node is breaching our SLA, and it gets worse when we add more leaf nodes. This calculation proves that adding more machines doesn’t help in improving our promised SLA.
Conclusion
In this article, we learned about the basics of scatter-gather patterns with a focus on solving one simple use case for a single machine case and later scaled it for a distributed environment. The pattern has several advantages, such as improved performance with parallel processing of tasks, increased fault tolerance by reallocating failed tasks to available nodes, better horizontal scalability, and good resource utilization. There are some disadvantages as well, e.g., complex topology between processing nodes may lead to low latency, incorrect number of leaf nodes may result in sub-optimal performance. Overall, the scatter-gather pattern is a powerful technique for developing high-performing and scalable distributed applications.
References
Enterprise Integration Patterns
SRE Fundamentals
Recommendations for defining reliability targets
Designing Distributed Systems
