An Overview of the Kafka Distributed Message System (Part 2)

Welcome back! If you missed Part 1, you can check it out here.
Broker, Topic, and Partition
Broker
In a simplified sense, a broker is a Kafka server. It is a service process that runs Kafka.
- When a broker connects within a cluster, it allows us to access the whole cluster.
- Brokers in a cluster are differentiated based on the ID which is typically a unique number.
Topic, Partition, and Offset
A topic is a data pipeline. A data pipeline produces messages and publishes events at one end and consumes messages and responds to events at the other end of the pipeline. The data pipeline stores, routes, and sends messages or events.
The topic stores the data for a default period of one week.
A topic can be divided into multiple partitions.
- As a first step, order data in the partitions. Secondly, if a topic has only one partition, order the messages for the topic as well. Messages don't order if one topic has multiple partitions.
- Parallel processing increases with more partitions. Generally, the recommended number of hosts is x2. For example, if there are three servers in a cluster, six partitions can be created for each topic.
- It is not possible to modify messages written to partitions. Modified data for the topic would need retransmission unless a topic repeats again.
- In case the key doesn't exist, the data will then be sent to any one of the partitions. If the key exists, the data for the same key transmits to their respective topic.
- Offset is an incremental ID. Each message sent to a partition has a unique incremental ID.
Distribution of Brokers, Topics, and Partitions
It is possible to set a different number of partitions for different topics Partitions are randomly distributed on different nodes in case if there are multiple nodes in a cluster.
Number of Copies for a Topic (Replication Factor)
Generally, a topic has 2 or 3 number of copies. This is mainly so that, in case a node fails and goes offline, the topic will remain available, and other nodes in the cluster will continue to provide services.
It is advisable to restrict your app to a small number of copies. With an increase in the number of copies, the time taken to synchronize the data increases and, at the same time, it lowers disk utilization.
Note: For both Kafka and Hadoop clusters, more nodes do not mean higher fault tolerance. There is a reduction in fault probability on relevant nodes, however, the fault tolerance is still the same. Let's say there are 100 nodes present in a Hadoop cluster and we have set the number of copies to two. It is not possible to access the data if the nodes that store these copies failed. The overall failure probability of nodes, where we have saved two copies, reduces compared to three or five nodes, among 100 nodes.
Partition Leader and ISR
There is only one leader partition and one or more in-sync replicas (ISRs) for a topic with multiple partitions. While the leader partition performs read and write, the ISR ensures backup.
Producer
Producer Writes Data to a Topic
After the producer specifies the partition name and connects to any node in the cluster, Kafka automatically performs load balancing and routes the write operation to write data to the correct partition (multiple partitions are on different nodes in the cluster).
Producer ACKs
The producer will obtain the data write notification by selecting the following modes.
- Set ACKs to 0. At this point, the producer does not wait for write notification resulting into data loss. There is maximum speed here.
- Set ACKs to 1. The speed is limited and not as high as the previous mode. The producer waits for a notification from the leader instead of ISR. It may result in a loss of ISR data.
Set ACKs to all. At this point, the speed is extremely slow. The producer waits for a notification from the leader, and there is no loss of ISR.
Producer Keys
A key is specified when the producer transmits data. For example, an e-commerce order would transmit data such as Order Number, Retailer, and Customer. How would you set the key in this case?
Set the key as:
- An order number or empty if the receiver (consumer) of the data is not concerned about the transmission sequence of orders.
- A retailer, if the data receiver would need the retailer to transmit the order in a sequence.
- As a customer, if the data receiver would need the retailer to send the order in sequence. If we set the key to Retailer, it does not mean that the string "Retailer" is specified for each key in transmission. Instead, a specific value for Retailer is mentioned. Let's take the following table for example:
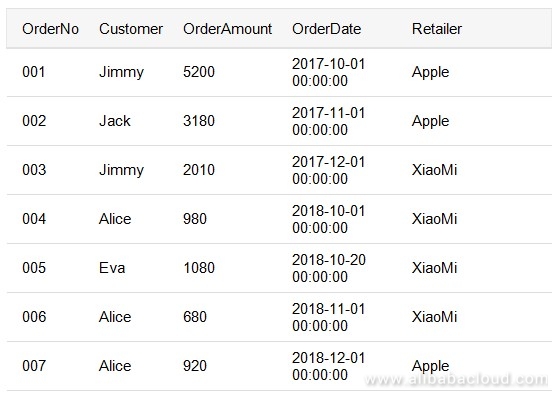
For orders 001 to 007, when we set the key to retailer, the key values are Apple (001), Apple (002), XiaoMi (003), XiaoMi (004), XiaoMi (005), XiaoMi (006), Apple (007).
In this use case, all the Apple orders go to one partition in the sequence, and all the Xiaomi orders go to the other partition in sequence. The two partitions may be the same or different. See the figure below:
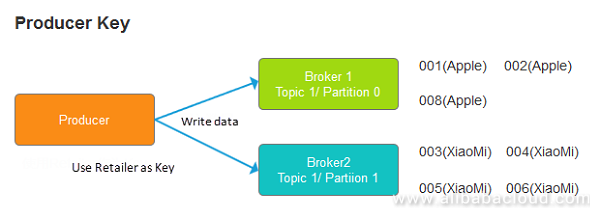 Producer Key is Used to Route Data
Producer Key is Used to Route Data
Consumer
The Basic Concept of a Consumer
Consumers read data from topics. Similar to the producer, as long as any node in the cluster is connected, and the topic name is specified, Kafka automatically extracts data from the correct broker and partition and sends the data to consumers. Data is ordered for each partition.
Consumer Group
Kafka uses the group concept to integrate the producer/consumer and publisher/subscriber models.
One topic may have multiple groups, and one group may include multiple consumers. Only one consumer in the group can consume one message. For different groups, consumers are in the publisher/subscriber model. All groups receive one message.
Note: Allocate one partition to only one consumer in the same group. If there are three partitions and four consumers in one of the groups, one consumer is redundant and cannot receive any data.
Consumer Offsets
Please note – Consumer offsets mentioned here are different as compared to offsets mentioned in the previous topic. In the previous topic, offsets are related to topic (especially partitions) whereas here I am referring to consumers. Here are some more points of consideration.
- Offset records the read location of each consumer in each group.
- Kafka uses a particular topic,
consumer_offsets, to save consumer offsets. - When a consumer comes online again after going offline, fetch the data from the location previously recorded by offsets.
Submission times for offsets:
- At Most Once: As long as a consumer receives a message, the consumer submits offsets. This ensures maximum efficiency. However, when the processing of a message fails, for example, the application becomes abnormal, and the message is no longer obtainable.
- At least Once: The offsets are submitted after a consumer processes a message. This may cause repeated reads. When the processing of a message becomes abnormal, the message reads again. This is the default value.
- Exactly Once: Still under trial.
Generally, "At least once" is selected and operation is performed on the application to ensure repeated operation. However, the result is not affected.
Note: CAP theory: A distributed system can meet at the most any two aspects along with Consistency, Availability, and Partition Tolerance at once.
ZooKeeper
ZooKeeper is a distributed service registration, discovery, and governance component. Many components in the big data ecosystem, HDFS for example, use ZooKeeper. Kafka depends on ZooKeeper. The Kafka installation package directly includes its compatible ZooKeeper version.
Kafka uses ZooKeeper for the following:
- Manage nodes in a cluster and maintain the list of nodes.
- Manage all topics and keep the list of topics.
- Elect the leader for partitions.
- Notify Kafka when there is any change detected in a cluster. The changes include topic creation, broker online/offline, and topic deletion.
Summary
This document discusses Kafka's main concepts and mechanisms. I believe that you will have a preliminary understanding of Kafka after reading this article. In the following chapters, we will perform actual operations to see how Kafka works. If you feel that Kafka is stable and robust during use, I hope you will like it.
