Time Series Analysis: VAR-Model-As-A-Service Using Flask and MinIO

VAR-As-A-Service is an MLOps approach for the unification and reuse of statistical models and machine learning models deployment pipelines. It is the second of a series of articles that is built on top of that project, representing experiments with various statistical and machine learning models, data pipelines implemented using existing DAG tools, and storage services, both cloud-based and alternative on-premises solutions. This article focuses on the model file storage using an approach also applicable and used for machine learning models. The implemented storage is based on MinIO as an AWS S3-compatible object storage service. Furthermore, the article gives an overview of alternative storage solutions and outlines the benefits of object-based storage.
The first article of the series (Time Series Analysis: VARMAX-As-A-Service) compares statistical and machine learning models as being both mathematical models and provides an end-to-end implementation of a VARMAX-based statistical model for macroeconomic forecast using a Python library called statsmodels. The model is deployed as a REST service using Python Flask and Apache web server, packaged in a docker container. The high-level architecture of the application is depicted in the following picture:
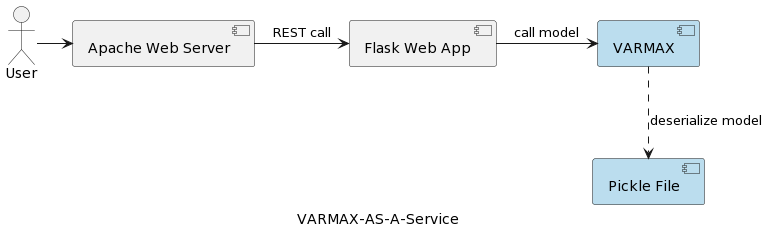
The model is serialized as a pickle file and deployed on the web server as part of the REST service package. However, in real projects, models are versioned, accompanied by metadata information, and secured, and the training experiments need to be logged and kept reproducible. Furthermore. from an architectural perspective, storing the model in the file system next to the application contradicts the single responsibility principle. A good example is a microservice-based architecture. Scaling the model service horizontally means that each and every microservice instance will have its own version of the physical pickle file replicated over all the service instances. That also means that the support of multiple versions of the models will require a new release and redeployment of the REST service and its infrastructure. The goal of this article is to decouple models from the web service infrastructure and enable the reuse of the web service logic with different versions of models.
Before diving into the implementation, let's say a few words about statistical models and the VAR model used in that project. Statistical models are mathematical models, and so are machine learning models. More about the difference between the two can be found in the first article of the series. A statistical model is usually specified as a mathematical relationship between one or more random variables and other non-random variables. Vector autoregression (VAR) is a statistical model used to capture the relationship between multiple quantities as they change over time. VAR models generalize the single-variable autoregressive model (AR) by allowing for multivariate time series. In the presented project, the model is trained to do forecasting for two variables. VAR models are often used in economics and the natural sciences. In general, the model is represented by a system of equations, which in the project are hidden behind the Python library statsmodels.
The architecture of the VAR model service application is depicted in the following picture:
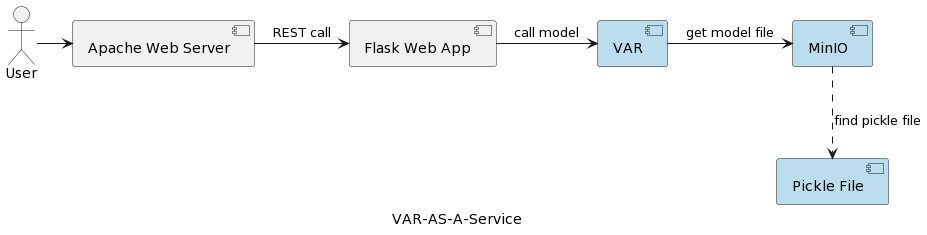
The VAR runtime component represents the actual model execution based on parameters sent by the user. It connects to a MinIO service via a REST interface, loads the model, and runs the prediction. Compared to the solution in the first article, where the VARMAX model is loaded and deserialized at application startup, the VAR model is read from the MinIO server each time a prediction is triggered. This comes at the cost of additional loading and deserialization time but also with the benefit of having the latest version of the deployed model at every single run. Furthermore, it enables dynamic versioning of models, making them automatically accessible to external systems and end-users, as will be shown later in the article. Note that due to that loading overhead, the performance of the selected storage service is of great importance.
But why MinIO and object-based storage in general?
MinIO is a high-performance object storage solution with native support for Kubernetes deployments that provides an Amazon Web Services S3-compatible API and supports all core S3 features. In the presented project, MinIO is in Standalone Mode, consisting of a single MinIO server and a single drive or storage volume on Linux using Docker Compose. For extended development or production environments, there is the option for a distributed mode described in the article Deploy MinIO in Distributed Mode.
Let's have a quick look at some storage alternatives while a comprehensive description can be found here and here:
- Local/Distributed file storage: Local file storage is the solution implemented in the first article, as it is the simplest option. Computation and storage are on the same system. It is acceptable during the PoC phase or for very simple models supporting a single version of the model. Local file systems have limited storage capacity and are unsuitable for larger datasets in case we want to store additional metadata like the training data set used. Since there is no replication or autoscaling, a local file system can not operate in an available, reliable, and scalable fashion. Each service deployed for horizontal scaling is deployed with its own copy of the model. Furthermore, the local storage is as secure as the host system is. Alternatives to the local file storage are NAS (Network-attached storage), SAN (Storage-area network), distributed file systems (Hadoop Distributed File System (HDFS), Google File System (GFS), Amazon Elastic File System (EFS) and Azure Files). Compared to the local file system, those solutions are characterized by availability, scalability, and resilience but come with the cost of increased complexity.
- Relational databases: Due to the binary serialization of models, relational databases provide the option for a blob or binary storage of models in table columns. Software developers and many data scientists are familiar with relational databases, which makes that solution straightforward. Model versions can be stored as separate table rows with additional metadata, which is easy to read from the database, too. A disadvantage is that the database will require more storage space, and this will impact backups. Having large amounts of binary data in a database can also have an impact on performance. In addition, relational databases impose some constraints on the data structures, which might complicate the storing of heterogeneous data like CSV files, images, and JSON files as model metadata.
- Object storage: Object storage has been around for quite some time but was revolutionized when Amazon made it the first AWS service in 2006 with Simple Storage Service (S3). Modern object storage is native to the cloud, and other clouds soon brought their offerings to market, too. Microsoft offers Azure Blob Storage, and Google has its Google Cloud Storage service. The S3 API is the de-facto standard for developers to interact with storage in the cloud, and there are multiple companies that offer S3-compatible storage for the public cloud, private cloud, and private on-premises solutions. Regardless of where an object store is located, it is accessed via a RESTful interface. While object storage eliminates the need for directories, folders, and other complex hierarchical organization, it’s not a good solution for dynamic data that is constantly changing as you’ll need to rewrite the entire object to modify it, but it is a good choice for storing serialized models and the mode's metadata.
A summary of the main benefits of object storage are:
- Massive scalability: Object storage size is essentially limitless, so data can scale to exabytes by simply adding new devices. Object storage solutions also perform best when running as a distributed cluster.
- Reduced complexity: Data is stored in a flat structure. The lack of complex trees or partitions (no folders or directories) reduces the complexity of retrieving files easier as one doesn't need to know the exact location.
- Searchability: Metadata is part of objects, making it easy to search through and navigate without the need for a separate application. One can tag objects with attributes and information, such as consumption, cost, and policies for automated deletion, retention, and tiering. Due to the flat address space of the underlying storage (every object in only one bucket and no buckets within buckets), object stores can find an object among potentially billions of objects quickly.
- Resiliency: Object storage can automatically replicate data and store it across multiple devices and geographical locations. This can help protect against outages, safeguard against data loss, and help support disaster recovery strategies.
- Simplicity: Using a REST API to store and retrieve models implies almost no learning curve and makes the integrations into microservice-based architectures a natural choice.
It is time to look at the implementation of the VAR model as a service and the integration with MinIO. The deployment of the presented solution is simplified by using Docker and Docker Compose. The organization of the whole project looks as follows:

As in the first article, the preparation of the model is comprised of a few steps that are written in a Python script called var_model.py located in a dedicated GitHub repository :
- Load data
- Divide data into train and test data set
- Prepare endogenous variables
- Find optimal model parameter p ( first p lags of each variable used as regression predictors)
- Instantiate the model with the optimal parameters identified
- Serialize the instantiated model to a pickle file
- Store the pickle file as a versioned object in a MinIO bucket
Those steps can also be implemented as tasks in a workflow engine (e.g., Apache Airflow) triggered by the need to train a new model version with more recent data. DAGs and their applications in MLOps will be the focus of another article.
The last step implemented in var_model.py is storing the serialized as a pickle file model in a bucket in S3. Due to the flat structure of the object storage, the format selected is:
<bucket name>/<file_name>
However, for file names, it is allowed to use a forward slash to mimic a hierarchical structure, keeping the advantage of a fast linear search. The convention for storing VAR models is as follows:
models/var/0_0_1/model.pkl
Where the bucket name is models, and the file name is var/0_0_1/model.pkl and in MinIO UI, it looks as follows:

This is a very convenient way of structuring various types of models and model versions while still having the performance and simplicity of flat file storage.
Note that the model versioning is implemented as part of the model name. MinIO provides versioning of files, too, but the approach selected here has some benefits:
- Support of snapshot versions and overriding
- Usage of semantic versioning (dots replaced by '_' due to restrictions)
- Greater control of the versioning strategy
- Decoupling of the underlying storage mechanism in terms of specific versioning features
Once the model is deployed, it is time to expose it as a REST service using Flask and deploy it using docker-compose running MinIO and an Apache Web server. The Docker image, as well as the model code, can be found on a dedicated GitHub repository.
And finally, the steps needed to run the application are:
- Deploy application:
docker-compose up -d - Execute model preparation algorithm:
python var_model.py(requires a running MinIO service) - Check if the model has been deployed: http://127.0.0.1:9101/browser
- Test model:
http://127.0.0.1:80/apidocs
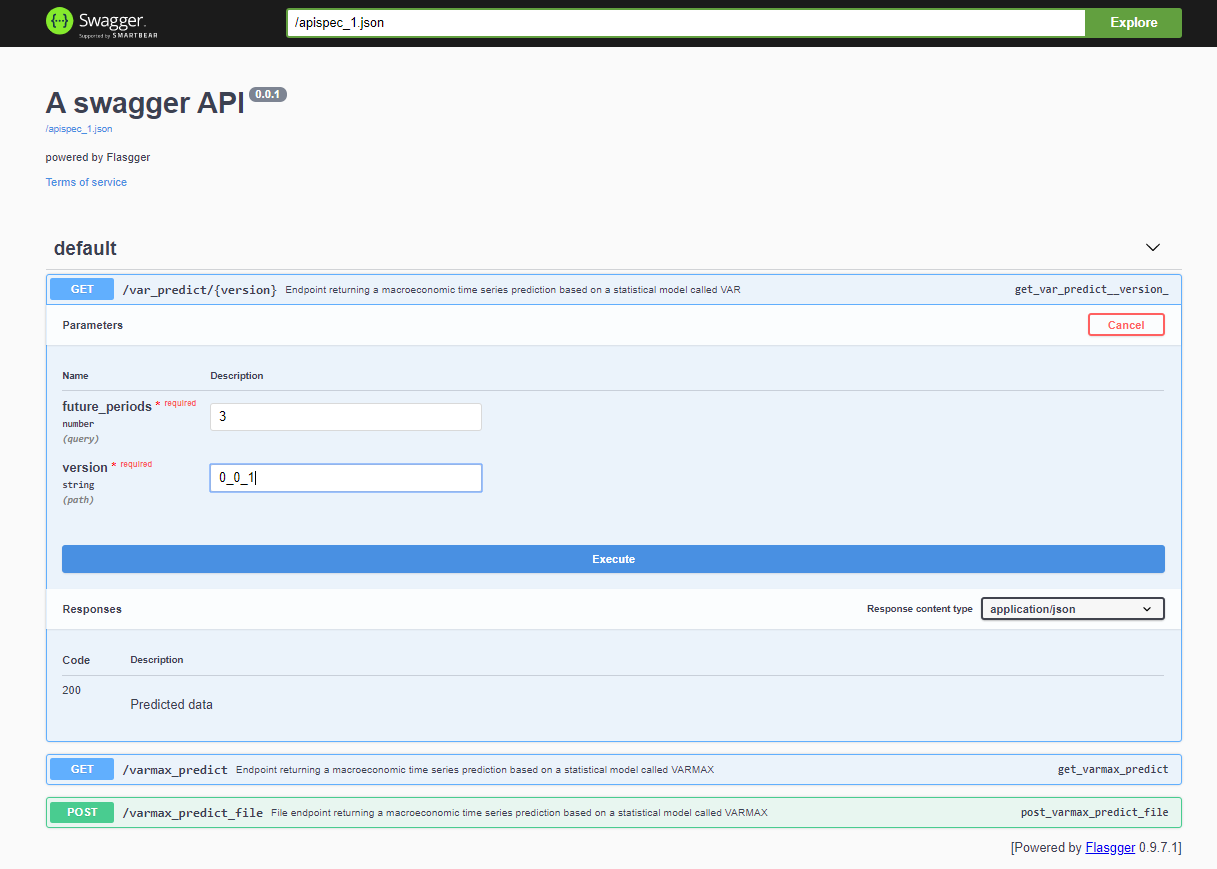
After deploying the project, the Swagger API is accessible via <host>:<port>/apidocs (e.g., 127.0.0.1:80/apidocs). There is one endpoint for the VAR model depicted next to the other two exposing a VARMAX model:
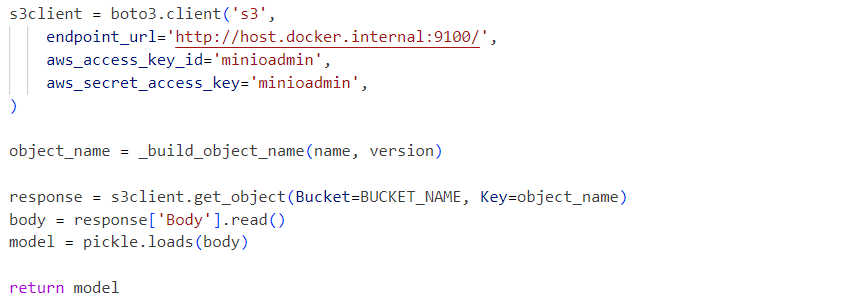
Internally, the service uses the deserialized model pickle file loaded from a MinIO service:
Requests are sent to the initialized model as follows:

The presented project is a simplified VAR model workflow that can be extended step by step with additional functionalities like:
- Explore standard serialization formats and replace the pickle with an alternative solution
- Integrate time series data visualization tools like Kibana or Apache Superset
- Store time series data in a time series database like Prometheus, TimescaleDB, InfluxDB, or an Object Storage such as S3
- Extend the pipeline with data loading and data preprocessing steps
- Incorporate metric reports as part of the pipelines
- Implement pipelines using specific tools like Apache Airflow or AWS Step Functions or more standard tools like Gitlab or GitHub
- Compare statistical models' performance and accuracy with machine learning models
- Implement end-to-end cloud-integrated solutions, including Infrastructure-As-Code
- Expose other statistical and ML models as services
- Implement a Model Storage API that abstracts away the actual storage mechanism and model's versioning, stores model metadata, and training data
These future improvements will be the focus of upcoming articles and projects. The goal of this article is to integrate an S3-compatible storage API and enable the storage of versioned models. That functionality will be extracted in a separate library soon. The presented end-to-end infrastructural solution can be deployed on production and improved as part of a CI/CD process over time, also using the distributed deployment options of MinIO or replacing it with AWS S3.
