KubeMQ: A Modern Alternative to Kafka

Modern applications are complex, with many different moving parts. Even for the most basic fulfillment center application, front-end interfaces trigger payment processing transactions, which in turn trigger manufacturing and shipping events. These services need a reliable way to communicate with one another regardless of the underlying network or the availability of other services.
To make such complex operations happen, there has to be some type of service “post office” to keep track of all the requests and alerts flying back and forth. The tool that achieves this is the message queue. A message queue is a specialized application that acts as an intermediary between different services of a distributed application or between different applications. It decouples the application services from one another, ensuring that processing occurs whether or not the recipient of a message is available. The message queue ensures all messages are eventually received successfully.
Common use cases for message queues include:
- Asynchronous processing between disparate applications.
- Microservice-based applications where reliable communication between the different components is critical.
- Transaction ordering and throttling.
- Data processing operations that can benefit from the streamlined efficiency of batching.
- Applications that must be scalable to meet sudden and unexpected changes in demand.
- Applications that must be resilient enough to recover from crashes and unexpected failures.
- Throttling resource consumption by long-running processes.
There’s no shortage of vendors in the message queue field. Larger cloud platforms like Amazon Web Services, Microsoft Azure, and Google Cloud have their own offerings (AWS Simple Queue Service, Azure’s Service Bus, and Google’s Pub/Sub). There are also standalone, general-purpose message brokers such as RabbitMQ, Apache’s ActiveMQ, and Kafka.
This article introduces a modern, Kubernetes-native message queue called KubeMQ, to show how organizations trying to implement—or already using—Kafka on Kubernetes can benefit from it.
Introducing Apache Kafka
To understand the full value of KubeMQ, we’ll first need to spend some time with Kafka. Kafka was originally created by LinkedIn engineers as a software bus for tracking LinkedIn user activities. It was later released as an open source product and today, Kafka is developed and managed by the Apache Software Foundation.
Apache notes that more than 80% of Fortune 100 companies trust and use Kafka. Despite being open source, it’s known to be a highly scalable system that can connect to a wide range of event producers and consumers. It can be configured to perform complex functions with data streams and can work well even in limited network environments. With widely available support within the online user community, Kafka has several commercial offerings as well. For example, AWS offers managed Kafka, as does Confluent.
Limitations of Kafka
Despite its high adoption, Kafka isn’t always the best choice as a message queuing system. It has a monolithic architecture, suitable for on-premise clusters or high-end multi-VM setups. Given how much memory and storage Kafka needs, quickly spinning up a multi-node cluster on a standalone workstation for testing purposes can be a challenge.
Simply put, it’s not easy to successfully bring together all the complex pieces necessary to integrate Kafka with your infrastructure. This is particularly the case with a Kubernetes-based architecture.
As you can see from the image below, there are different moving parts to a Kubernetes-based Kafka deployment. Besides provisioning the underlying compute, network, and storage infrastructure for a basic Kubernetes cluster (if you are implementing it on-prem), you’ll also need to install and integrate all the Kafka pieces with a package manager like Helm. These components can include an orchestrator like ZooKeeper or Mesos for managing Kafka’s brokers and topics. Other areas needing attention include dependencies, logs, partitions, and so on. If even one element is either missing or misconfigured, things won’t work—deploying Kafka successfully isn’t trivial.
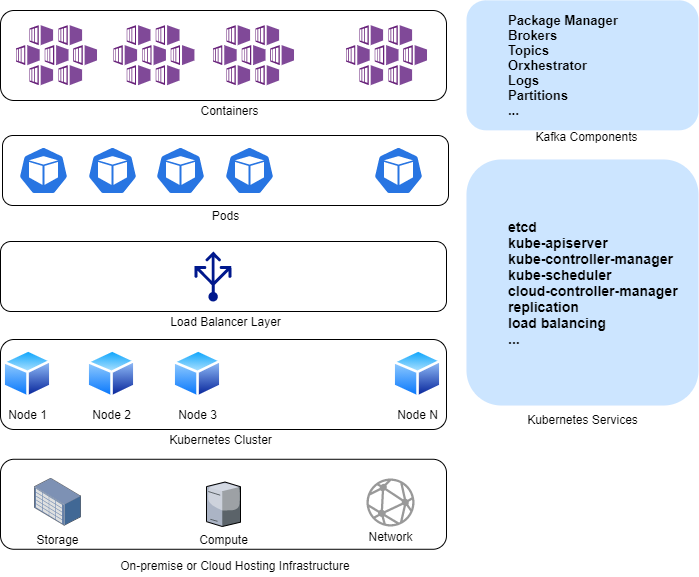
Kafka on Kubernetes Architecture
Adding a new Kafka node to a Kubernetes cluster requires complex manual balancing to maintain optimal resource usage. And that’s why there’s no simple way to manage and ensure a reliable backup and recovery strategy; it’s not easy to disaster-proof a Kafka cluster running on a large number of nodes. Unlike Kubernetes clusters where data is persisted outside the pod, and the orchestrator spins up a failed pod automatically, there’s no such native fail-proof mechanism for Kafka.
Finally, effective monitoring of Kafka/ZooKeeper/Kubernetes deployments requires third-party tools.
Introducing KubeMQ
KubeMQ is a messaging service that was built from the ground up with Kubernetes in mind. Following the container architecture best practices, KubeMQ is intended to be stateless and ephemeral. That is, a KubeMQ node will remain unchanged, predictable, and reproducible for its entire lifecycle. If configuration changes are needed, nodes are shut down and replaced.
This reproducibility means that, unlike Kafka, KubeMQ comes with a zero-configuration setup, needing no configuration tweaking after it’s installed.
KubeMQ was designed to accommodate the widest range of message patterns. It’s a message broker and message queue that supports the following:
- Pub/Sub with or without persistence
- Request/Reply (synchronous, asynchronous)
- At Most Once Delivery
- At Least Once Delivery
- Streaming patterns
- RPC
Comparatively, Kafka only supports Pub/Sub with persistence and streaming. RPC and Request/Reply patterns are not supported by Kafka at all.
In terms of resource usage, KubeMQ outshines Kafka with its minimal footprint. The KubeMQ docker container takes up only 30MB of space. Such a small footprint contributes to a fault-tolerant setup and streamlined deployments. Unlike Kafka, adding KubeMQ to a small development Kubernetes environment in a local workstation is straightforward. But at the same time, KubeMQ is scalable enough to be deployed in a hybrid environment running on hundreds of on-premise and cloud-hosted nodes. At the core of this deployment ease is kubemqctl, the command line interface tool for KubeMQ, analogous to Kubernetes’ kubectl.
Another area where KubeMQ outperforms Kafka is its speed. Kafka was written in Java and Scala while KubeMQ was written in Go, ensuring fast operation. In an internal benchmark operation, KubeMQ processed one million messages 20% faster than Kafka.
Going back to the “configuration-free” side of KubeMQ, a channel is the only object developers will need to create. You can forget all about brokers, exchanges, and orchestrators—KubeMQ’s Raft does all that instead of ZooKeeper.
From a monitoring perspective, dashboards via Prometheus and Grafana come fully integrated with KubeMQ, so you won’t have the added work of manually integrating third-party observability tools. However, you can still use your existing logging and monitoring solutions with KubeMQ, thanks to its native integration with tools including:
- Fluentd, Elastic, and Datadog, for monitoring
- Loggly, for logging
- Jaeger and Open Tracing, for tracing
Since Kafka isn’t a native part of the Cloud Native Computing Foundation (CNCF) landscape, integration with CNCF tools often is not supported and has to be manually configured.
If configured, connectivity can happen through the open source gRPC remote procedure call system, whose superior compatibility with Kubernetes is well known. Kafka’s own proprietary connectivity mechanism doesn’t necessarily deliver comparable results.
Transparent Migration from Kafka to KubeMQ
In addition to the simplicity of deployment and operation for KubeMQ, porting an existing Kafka setup to KubeMQ is simple.
To do this, developers can start by using the KubeMQ Kafka connector. KubeMQ target and source connectors are configured to convert messages from Kafka. At a high level, KubeMQ source connectors consume messages from a Kafka source topic as a subscriber, convert the message to a KubeMQ message format, and then send the message to an internal journal. KubeMQ target connectors subscribe to an output journal that contains the converted message, and then sends the messages to a target topic in Kafka. The high-level architecture is shown below:
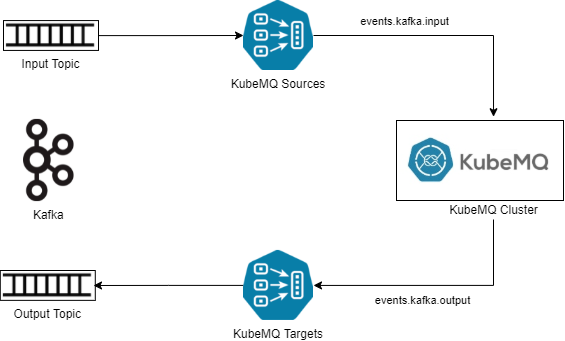
Additionally, any messaging patterns supported by Kafka are all supported by KubeMQ. For example, Kafka only supports Pub / Sub with persistence, and streaming. KubeMQ is a message queue and a message broker that supports Pub / Sub (with or without persistence) Request / Reply (sync, async), at least one delivery, streaming patterns, and RPC. So, there’s no need to refactor application code and accommodate complicated logic changes when migrating from Kafka to KubeMQ.
Final Words
For most workloads, the simplicity, light footprint, and container-first integration built into KubeMQ will deliver performance superior to Kafka. In addition, the almost null configuration needed will save many hours of administration and setup. As we mentioned, migration is straightforward.
KubeMQ is a free download that comes with a free, six-month development trial. If you are working with OpenShift, KubeMQ is available in the Red Hat Marketplace. It’s also available for all the major cloud environments, including GCP, AWS, Azure, and DigitalOcean.
