A Transition From Monolith to Microservices

These days, it is trendy to break monoliths into microservices. I am reminded of those days in the early 2000s when SOA was the buzzword and most organizations, urged by vendors and system integrators who were busy waving the SOA magic wand in the hopes that it would turn their legacy application to one that is more flexible and agile. One vendor even remarked, “With SOA, you don’t have to write a single line of code.” Unfortunately, the reality was far from the truth. The hype continued with most of them struggling to get it right and were left disillusioned. While the idea of services was not bad, SOA with its strongly typed service definitions and use of SOAP over HTTP was very cumbersome. These shortcomings along with the mindset of many vendors and organizations akin to the proverbial phrase, “When you have a new shiny hammer, everything looks like nails,” spelled doom for SOA.
A couple of years back, I embarked on a project to create a framework to help build process-oriented applications with ease and agility. After a lot of deliberation, I picked Java EE as the platform of choice for building the framework, considering many of the outstanding features provided by Java EE7 which was the latest release then.
The original monolith framework was designed according to the Java EE best practices. The framework with logically separate layers employed MVC architecture patterns and relied heavily on the dependency injection principles to reduce coupling and improve flexibility. The final deployment artifact consisted of several JAR and WAR components packaged within an EAR application as shown below.
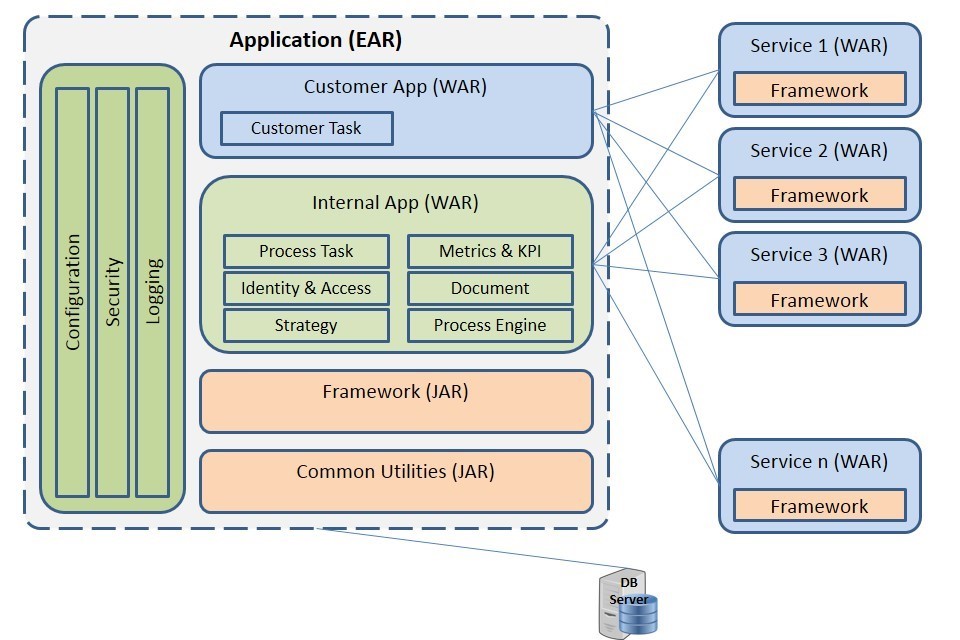
As the framework began taking shape, more functions were added. For more information on the functional and technical aspects of the framework, please refer to Part 6 and Part 7 of my video series.
Although the application employed most of the best practices in development, I eventually discovered that the whole application was beginning to get unwieldy to the point that each cycle of a fix, build and deploy took inordinately long time. The temptation to move to a microservices based architecture was too overpowering. Nevertheless, I refrained from the idea of splitting up the growing monolith, lest I should break any functionality. The platform continued to grow in complexity until at last, I realized that I had sunk too deep. I was left with no option but to stop and rethink about refactoring the whole application by creating smaller manageable microservices.
A couple of other reasons also forced me to go for it:
- Many of the functions could have been implemented using more appropriate technologies - Node.js and Spring Boot to name a few.
- Tight coupling between modules was beginning to take a toll on flexibility while working on functional changes within the application.
- The monolith architecture had scalability issues, especially when targeting cloud deployments.
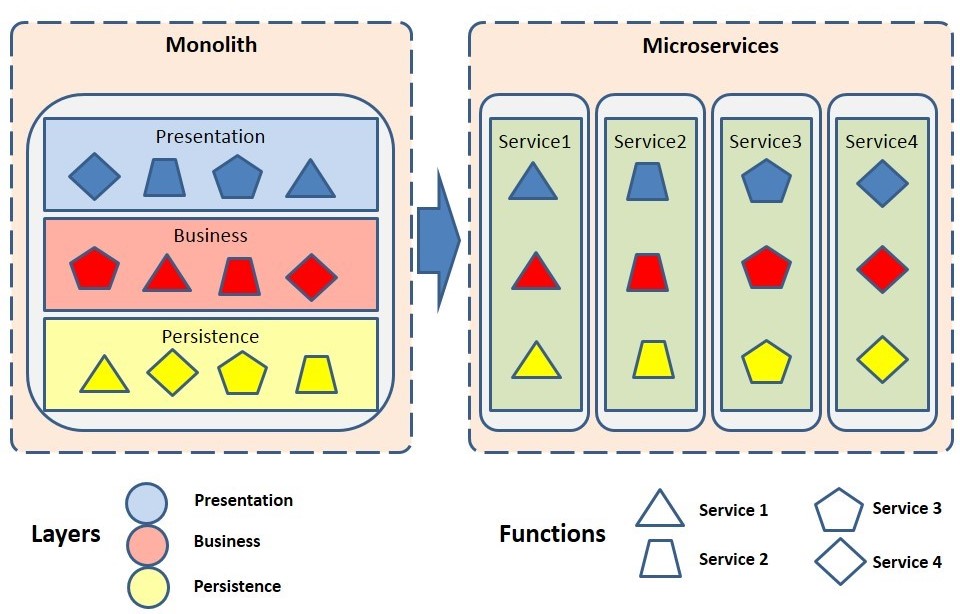
With microservices architecture, applications are modeled around self-contained business function or capability - no more and no less. Following the basic principles of microservices and dividing the monolith application into smaller functionally independent modules, resulting in multiple functional modules with the presentation, business and persistence layers co-located within a single process space.
The typical transition from a monolith to microservices is illustrated below.
Generally, there are two approaches for developing modern applications using microservices:
- Start a new application using microservices architecture right away, or
- Start with a monolith and then gradually split and migrate to microservices.
Though there are arguments both in favor and against the approaches, I prefer to align with the latter for the following reasons:
- Setting up the initial base infrastructure for microservices from scratch was time-consuming.
- Implementing use cases one by one within a monolith was quicker during the initial phases.
- As the monolith grew in size, the big picture of the complete application was clearer and could easily identify functional boundaries for potential refactoring into microservices.
- A well-designed monolith application can be broken down into microservices with minimal efforts.
So, when I finally got my head around the idea of breaking the monolith, it was reassuring to note Martin Fowler’s argument favoring a monolith-first strategy in his article Monolith First: “You should build a new application as a monolith initially, even if you think it's likely that it will benefit from a microservices architecture later on.” This was true because splitting a function was not so difficult, especially if the monolith was architected well in the first place. He further mentions “A monolith allows you to explore both the complexity of a system and its component boundaries” and “continue breaking out services as your knowledge of boundaries and service management increases.”
You only begin to reap the benefits of microservices architecture when your monolith has gotten sufficiently complex to the point that both development and maintenance efforts, as well as runtime performance, are impacted. Microservices architecture does not benefit smaller applications as the overheads due to the distributed architecture both in development and operation outweighs the benefits.
The figure below shows the microservices landscape for the refactored monolith.

So, how small or big should a microservice be? There is never an absolute answer. It is highly subjective and depends on your use case. However, you can take a leaf out of a key tenet of microservices – do one thing and do it well. The domain driven design approach to modularizing applications based on business context is ideal for decomposing large systems into smaller microservices.
Next, I will detail my experience in particular areas during the transition to a microservices architecture.
Scalability
Recall that monoliths with logically separated layers deployed as a single process though performed well was not quite as efficient in scaling due to the unbalanced load on components. This was partially offset by distributing the presentation, business and persistence layers into separate process space and using RPC (REST, web services etc.) for communication. However, a major drawback, in this case, was that it resulted in several remote call overheads for accessing even a single function. In contrast, using microservices approach, each service or function with all of the layers within the same process space, can be deployed and scaled independently.
One advantage of the microservices approach was the ability to leverage container technologies such as Docker, Kubernetes or Mesos offering the flexibility to move individual services across multiple environments (development, test, and production), avoiding configuration headaches while more importantly giving the ability to scale specific functions of the application depending on their resource utilization.
Service Discovery
With microservices, one important requirement is to be able to dynamically discover and access services in order to truly decouple and isolate them. Technically, this means no hard-coding of service endpoints within the client services. Eureka was one of the several choices to implement a service registry that supported registration, storing and querying metadata about services.
Load Balancing
With the proliferation of services in a microservices architecture along with the need to horizontally scale services on demand, a robust mechanism to balance loads between a set of redundant services is critical. Ribbon fit the bill with its pluggable load balancing rules, integration to service registries with built-in failure resiliency.
Ribbon, coupled with Eureka provided an excellent solution to deliver highly decoupled and scalable system.
Reactive Systems
The monolith relying mostly on synchronous interactions suffered from limited flexibility and resilience. The new microservices, on the other hand, were designed as Vertx cluster apps using a reactive programming paradigm. These microservices collaborating with other services over a messaging infrastructure improved responsiveness and decoupled systems in time and space. These practices provided the much-needed characteristics of a reactive system – responsiveness, resiliency, elasticity, and message-driven.
Persistence
Splitting the monolith data model into autonomous data models local to each service was indeed a challenge. The original data model consisted of several schemas containing a fairly large number of tables with plenty of joins between them. It was quite easy to maintain the transactional integrity of data through local transactions.
Breaking the monolith data model into functionally separate domains as required by microservices without the joins was tedious by itself, but more daunting was the prospect of synchronizing data across services and getting them to work consistently and with integrity. The “Saga pattern” was adopted to ensure transactional integrity of data across the services, with producers and consumers collaborating through events over an event bus. While data relating to each microservice was persisted locally, data outside of the microservice was persisted by sending appropriate events which were consumed by relevant services. Any error in persisting data downstream would trigger events to run compensating actions cascading upstream along the chain.
In order to keep persistent data private for services, the schema-per-service pattern was adopted. However, the various schemas shared the physical database running in cluster mode. Another challenge with the microservices data model was querying for data spanning across services which were a piece of cake with the monolith model. The microservices architecture necessitated querying individual data sources from respective services and aggregating them to produce the final composite result.
API Gateway
In a monolith, the façade pattern is commonly used to aggregate data fetched locally from multiple services in order to service a coarse grain request from the web layer. However, in a microservices architecture, since each service is responsible for its own data and lives in separate process space, an API gateway serves as the façade in a distributed environment such as this. The API gateway is the single point of entry for microservices for client interactions.
In my monolith, the two main client components – the Customer Web App and the Employee Web App deployed as WAR applications interact with other microservices via the API gateway. Requests using other protocols were handled through separate API gateways.
Cross-Cutting Concerns
One other challenge with microservices architecture was implementing cross-cutting concerns such as logging, security, audit trails, service registration, service discovery, configuration management etc. With a monolith, these were implemented within the application usually using a technology specific to the application. With microservices architecture employing polyglot technologies, these were not implemented individually for each service but rather using the microservices chassis pattern across the board.
Although implementing declarative security in a standard JEE app was straightforward, there were challenges in a microservices landscape with distributed security. The API gateway served as the ideal location to implement security services using delegated authorization with JWT tokens to propagate security credentials between microservices in a distributed environment.
Process Engine
When activities within an organization are automated as per defined processes, it is easy to measure performance directly using metrics derived from the processes. This was the primary driver to introduce a BPMN process engine at the heart of the monolith framework. Incidentally, the framework uses Camunda BPM as the process engine.
In order to keep the Camunda process engine independent and isolated from the application components, two important considerations were made:
- Microservices related to process services were designed as Camunda process applications, bundled with the relevant process models (.bpmn files) which were then independently deployed.
- The applications used RESTful APIs to interact with the Process Engine.
Configuring redundant process engines and persisting process data using a clustered database addressed the possibility of a single point of failure in the process engine. Most of the service applications were implemented using Spring Boot.
Conclusion
While this article details my experience transitioning from a monolith application to one that is microservices-based, it is not intended to favor one over the other. Although microservices offer superior performance metrics in several areas, monoliths must not be construed as bad as they have their own strengths. However, my decision to move towards a microservices architecture was mostly subjective as discussed. Nevertheless, I must admit that working with the original monolith framework within the IDE was cool especially navigating through the entire codebase, refactoring them and generating single deployment package effortlessly. So, do not attempt to break a monolith unless it gets too complex or you absolutely feel the need to break it up (you’ll know when it is time!).
