Git: Basic Terms and Commands Explained


"Before jumping to highlevel commands, it is always a good idea to understand the technical jargons used in any software programming."
If you have similar thoughts, then you’re in the right place.
Understanding the git workflow and its key concepts will help you be more productive in your day-to-day use of the git version control system to manage your code.
What Do We Refer to as Git?
git, like any other VCS, is used to keep a track of different versions of the same piece of data (or a filetype).
However, git stands out among other VCSs in being distributed in nature — also called a distributed version control system (DVCS); every developer machine acts like both a "node" as well as a "hub".
git maintains data integrity and treats every single filesystem change as data.
The basic skeleton architecture of git is based on branches. Your initial project itself is based out of a "master" branch. This promotes efficient feature developments, easy bug fixes, and code reviews. As a result, frequent synchronous work merges among peers.
The ideology behind git developed by Linus Torvalds is its "speed", "easy branching and merging", "data integrity", and "larger collaborations".
git stores your entire project history locally and lets you quickly access older versions of your data.
Git Workflow : The Three States of Git Files
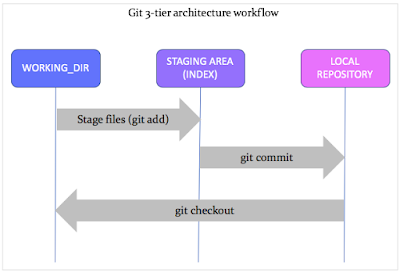
As you already know, many VCSs use a two-tier architecture — a repository and a working copy.
However, git works on a three-tier model — working directory, staging area, and local repository.
So why does git have three layers to save the same piece of code? The above sentence is contradictory, as git does give you an opportunity to save your work-in-progress at different intervals and versions.
The three stages of git store different (or the same) states of the same code (object) in each layer.
A git project, when first initialized (or cloned), makes a ‘working directory’ on your local machine to start editing your source code.
This is the first stage of your source code wherein you are free to modify the files and directories, probably add, delete, move, rename or copy them choosing your favorite editors. (I prefer ‘vim’ — the most efficient and powerful text editor).
Once you are happy with your edits, you stage your changes using the ‘git add’ command, which moves forward to the next stage — an ‘Index’ or ‘Staging area’. The Staging area displays a preview of what is going to be committed next.
But say you make more edits in your working directory while your first set of code is already staged (in the Staging area). The Working directory and Staging area will have different snapshots (versions) of your project.
To sync both stages, all you have to do is stage (git add) the latest Working directory changes you made.
Besides adding code changes, if you wish to undo any of the staged changes in the index, git has different commands to do so.
If there are no changes required at this stage, you move ahead and commit (‘git commit’) your changes, and the code moves and gets stored in the local git repository.
A commit makes sure that the same snapshot of your project exists in all three stages and that all three stages of git are in sync with each other.
The ‘git status’ command shows the working tree status and displays in which stage your files are.
Key Git Terms and git Commands
Although git is a VCS, it has its own filesystem architecture to handle source code.
Some popular VCSs that you might have already used are CVS (Concurrent Version Control System), SVN (Apache SubVersioN), ClearCase, and BitKeeper to name a few.
There is a general tendency to compare some of git's terms with those of earlier VCSs, but do not get carried away by how you used these terms. git has a different approach.
Repository
This is a local place/hub on your machine where the entire snapshot of your project is stored. Every minor change is stored and retrievable. Repository logs can easily be viewed and retrieved, i.e, you can jump to any older state (time-travel in history) of your code.
Working Directory
This is a local working copy of the project’s latest code.
Index (Staging area, Cache)
An Index is the snapshot of your next commit.
It is where the code moves to once you stage or add (git add) the code in the Working directory. A Staging area is like a cache memory and acts as a middle layer between the working directory (where the code is developed) and the local repository (where the code resides).
This layer gives a quick preview of the project snapshot that you are about to commit. You can still edit (add, modify, or delete) your code in the Index.
You could also revert back an older version (state) of a project here.
Commit
A commit is the latest snapshot (state) of a project.

Every commit has a unique commit ID. All commit logs are stored in the local repository.
A commit is a git object that stores the following attributes: commit ID, author name, authored date, and a commit message (header and body).
git hash or the ‘SHA-1’
The unique commit ID is called a ‘git hash’ or ‘SHA-1’. Every filesystem change (add, delete, edit, move, copy, rename, file permissions, etc.) is treated as a file and its contents are converted into a unique SHA-1 code.
Here is a sample commit ID: 8db083e7df7c9241e640b66c89c6f02649ac885a
They are often referred by the first 7 unique digits, such as 8db083e
You never ever have to remember the entire hash ID. git has a beautiful way of handling these commit (hash) IDs using references such as branches and tags.
Branch
A branch is a parallel, independent line of development.
A branch lets you work on the same piece of code in your isolated workspace.
Every branch has its own copy of the project history and develops on its own code. They are easily and often merged with each other.
Master
A master is the main default local branch when the project is first created as a git project.
HEAD
A HEAD is the snapshot of the latest commit on every branch.
It is a short name or pointer reference to an SHA-1 of a commit ID on each branch.
A HEAD always points to the branch’s latest commit (code) and automatically moves forward with each commit to point to the latest commit ID.
Extra: There is a concept of a ‘detached HEAD’ when the branch points to an older commit and not the latest one.
So you see, you now have the reference ‘HEAD’ for your latest commit ID and do not have to memorize the commit ID of your most recent work.
checkout
This command switches over to the specified branch and displays the current project state as it is in the branch.
It also restores the earlier working tree files.
clone
A clone is a working copy of a remote repository.
The ‘git clone’ command downloads the remote repository and creates a working directory on your local machine.
In addition, this command also stores a remote handler or pointer reference from the local repository to the remote repository.

The screenshot shows a local repository — "learn_branching" — that tracks a remote repository with the URL "https://github.com/divyabhushan/learn_branching.git", and "origin" is the name for the remote handler to the remote repository.
Conclusion
These basic concepts will definitely give you a better understanding of using git the most efficient way. Of course, there are many more concepts in git to explore.
Refer to git manual pages for a complete list of available commands as — "git help -a". To read about a specific command, use "git help <command_name>.
