Synchronous Replication in Tarantool (Part 3)


Read part 1 of this article here: Synchronous Replication in Tarantool (Part 1).
Read part 2 of this article here: Synchronous Replication in Tarantool (Part 2).
In continuation from where Part 2 left off, we will continue the journey of the long path to the algorithm's design and implementation. All sections are essential and add up to a single story.
5. Synchronous Replication
Before proceeding with our implementation of Raft, we decided to adopt several rules:
- If synchronous replication is not enabled, then the replication protocol and log format cannot be changed in any way. Full reverse compatibility must be maintained. It would allow updating Tarantool in the existing clusters and then, if necessary, setting up synchronous replication.
- If the replication is synchronous, the format of the existing log entries cannot be changed. Again, this is necessary for reverse compatibility. You can only add new entry types or new optional fields for existing entry types. The same is true for messages in replication channels.
- Tarantool's architecture cannot be changed in any significant way. Otherwise, it will lead us to the original problem where the task spanned several years. The main Tarantool threads should be left as they are and maintain their existing connections. The TX thread must keep managing transactions; the WAL thread, performing basic disk write operations; the IProto thread, providing the simplest interface between the network and users; and relay threads, reading the log and sending transactions to replicas. Any further optimizations or redistribution of system responsibilities must be done separately, without blocking the current processes.
These rules are easy to understand, but writing them down helped us manage our expectations and discard some unrealistic ideas.
Synchronous replication was developed on top of asynchronous. To understand how it works, we might want to look at the stages of a synchronous transaction's lifecycle:
- Creating a transaction
- Commit start
- Waiting for confirmation
- Reaching quorum
- Commit or rollback
As you progress through the steps, you'll find explanations of how everything works and what is different from asynchronous replication. Differences from Raft are also covered on each step and in the end of the article.
Creating a Transaction
Synchronicity in Tarantool is a property not of the whole database but of each individual transaction. Users can choose what data they want to replicate synchronously and what they don't.
This approach wasn't too difficult to implement and didn't affect the synchronous transaction processing algorithm. It provided significant flexibility for users. Now they don't have to pay for synchronous replication of the data they don't want to replicate in this way. This is especially useful if synchronous replication is needed for a small amount of rarely updated data.
A transaction is synchronous if it is related to at least one synchronous space. A space in Tarantool is a structure similar to an SQL table. When creating a space, you can use the option is_sync to make all transactions affecting this space are synchronous. If a transaction alters even a single synchronous space along with several non-synchronous ones, the transaction becomes synchronous.
Here is how it looks in code.
Turn on synchronous replication for the current space:
box.space[name]:alter({is_sync = true})Create a synchronous space:
box.schema.create_space(name, {is_sync = true})A synchronous transaction affecting one space:
sync = box.schema.create_space(
‘stest’, {is_sync = true}
):create_index(‘pk’)
-- Single-expression transaction,
-- synchronous.
sync:replace{1}
-- Two expressions in a transaction,
-- which is also synchronous.
box.begin()
sync:replace{2}
sync:replace{3}
box.commit()Synchronous transaction affecting two spaces, one of which is non-synchronous:
async = box.schema.create_space(
‘atest’, {is_sync = false}
):create_index(‘pk’)
-- Transaction on two spaces, one of which
-- is synchronous, so the whole transaction
-- is synchronous.
box.begin()
sync:replace{5}
async:replace{6}
box.commit()From the moment of creation to the beginning of the commit, the transaction acts as asynchronous.
Commit Start
Whether a transaction is synchronous or asynchronous, it must be logged. For asynchronous transactions, successful logging equals commit. However, synchronous transactions cannot be committed until replicas send their confirmations. So why do we still need to log them?
Suppose a synchronous transaction is created, sent to the replicas, and logged there. Then the leader is turned off and restarted. If the transaction wasn't logged on the leader, it only exists on the replicas. Note how this problem is the opposite of the one we need to solve for synchronous replication. With asynchronous replication, the transaction might not be on the replicas. With a similar pattern of synchronous replication, the transaction could be absent on the leader but exist on the replicas.
We don't want to lose the transaction after instance restart or finish it before sending it to a necessary number of replicas. For this reason, we must divide the commit into two parts. The first part is logging the transaction along with its data. The second part is logging a special COMMIT marker after the quorum is reached. This is very similar to the two-phase commit algorithm. If the transaction didn't replicate in a reasonable time, the ROLLBACK marker is logged after a timeout.
In fact, Raft suggests the same, but it doesn't declare how exactly to log the transaction and in which format. We encounter these details already while implementing replication for a particular database.
Rollback is another concept Raft doesn't clearly define. Transactions on the leader wait forever until a quorum is reached. In real cases, infinite waiting is rarely a good idea. Raft suggests cutting the replicas' logs instead of rolling back transactions, which in reality might not work, as mentioned in one of the previous sections.
In Tarantool, at the beginning of a commit, a synchronous transaction is logged but not committed, and the changes are not visible. The transaction end must be marked with a special COMMIT or ROLLBACK log entry. If a COMMIT marker is logged, the transaction changes become visible.
Waiting for Confirmation From the Replicas
After a transaction is logged, the leader must wait until it is replicated to the replica quorum. The leader stores the transaction in memory until it receives confirmations from the replicas. There must be a special place where the confirmations could be delivered and counted to determine which transactions have reached a quorum.
In Tarantool, this place is called limbo. It is a place for transactions whose fate hasn't been decided yet. A logged transaction is assigned an LSN and sent to the limbo: to the end of the queue of similar transactions.
The limbo is located in the TX thread, which also receives all replica confirmations from relay threads. It was the easiest way to implement the feature with minimal alterations to the existing Tarantool subsystems. All synchronous replication operations occur in the limbo, which interacts with other subsystems via their interfaces.
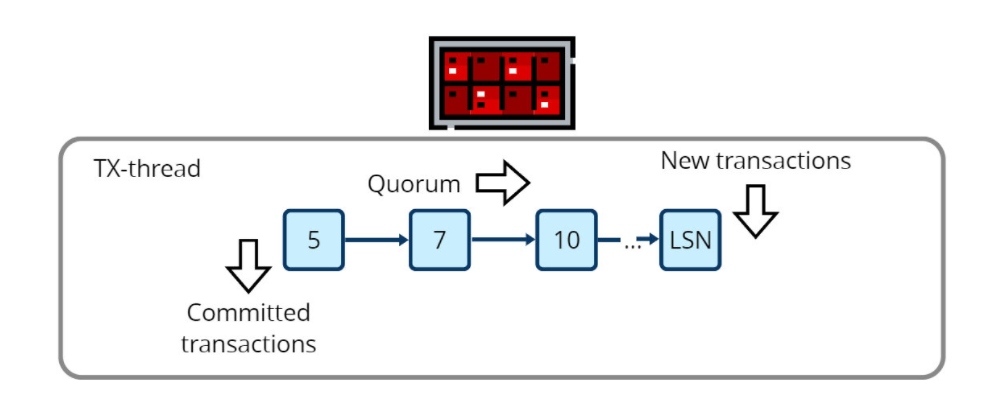
Tarantool subsystems (WAL, replication, transaction engine, etc.) have an internal API invisible to users. We rarely change it and try to keep the subsystems independent from one another. It is very important that synchronous replication doesn't break this isolation, and the limbo helps maintain it.
Reaching Quorum
While a transaction is stored in limbo, relay threads read the transaction from the log and send it to the replicas. Each replica receives the transaction and follows the same steps as the leader: write the transaction into its log and put it into its limbo. The replica understands if a transaction is synchronous the same way the leader does, checking whether the changed spaces are synchronous.
The difference here is that a replica doesn't own its limbo. A replica's limbo is a copy of the leader's limbo and depends on it entirely. A replica doesn't decide what to do with the transactions in its limbo. These transactions don't have timeouts and don't gather confirmations from other replicas. It is just a storage of transactions sent from the leader. Here they wait until the leader tells the replica what to do with them. Only the leader can decide what to do with synchronous transactions.
After logging a transaction, the replica sends a confirmation to the leader. Tarantool's subsystems have always used confirmations for monitoring. This is exactly the same confirmation format.
Confirmation is performed through a replica's vclock (vector clock), which changes after each new entry in the log. When the leader receives a confirmation message from a replica's vclock, it can see the LSN of the replica's most recent log entry. For example, the leader may send three transactions to a replica in one batch: {LSN = 1}, {LSN = 2}, {LSN = 3}. The replica responds with {LSN = 3}, which means that it logged all the transactions with LSNs less than or equal to 3. The transactions are now considered confirmed.
The leader reads confirmations from the replicas in the relay thread. From there, they are sent to the TX thread and become visible in box.info.replication. The limbo tracks these confirmations and monitors whether a quorum has been reached for the oldest waiting transaction.
To track the quorum as replication progresses, the limbo on the leader obtains a picture of how far what replica went. The limbo has a vclock storing `{replica ID, LSN}` pairs, except it's not a usual vclock. The first number is the replica's ID, and the second is the last LSN from the leader that was applied on that replica.
Thus, the limbo stores many versions of the leader's LSN as stored on the replicas. A regular vclock stores LSNs of different instances, but this one stores different LSNs of one instance: the leader.
The limbo can determine how many replicas applied a synchronous transaction. It simply counts how many parts of that special vclock are greater than the transaction's LSN or equal to it. This is slightly different from the vclock that users can see in box.info, but the idea is very similar. Every confirmation from a replica increments a part of this clock.
Below you can see an example of updating a limbo vclock on the leader of a three-node cluster. The leader is node 1.
Node 1: [0, 0, 0], limbo: [0, 0, 0]
Node 2: [0, 0, 0]
Node 3: [0, 0, 0]Let's say the leader begins to commit five synchronous transactions. They are logged on the leader but haven't been sent to the replicas yet. Then the vclocks will look like this:
Node 1: [5, 0, 0], limbo: [5, 0, 0]
Node 2: [0, 0, 0]
Node 3: [0, 0, 0]The first part of the leader's vclock was incremented because the five transactions were applied on the node with replica ID = 1. It doesn't matter that it was the leader; it is still one of the nodes in the quorum.
Now, let's say the first three transactions were replicated on node 2, and the first 4 on node 3. That is, replication is not finished yet. Then the vclocks will look like this:
Node 1: [5, 0, 0], limbo: [5, 3, 4]
Node 2: [3, 0, 0]
Node 3: [4, 0, 0]Pay attention to the changes in the leader's vclock. It is essentially a column in the matrix of all vclocks. Since Node 2 confirmed LSN 3, the second component of the leader's vclock was changed to 3. Since Node 3 confirmed LSN 4, the third component of the leader's vclock was changed to 4. Thus, you can tell what LSN has a quorum by looking at the leader's clock.
In this example, we have a quorum on LSN 4. It consists of nodes 1 and 3 since they confirmed this LSN. LSN 5 doesn't have a quorum yet since it exists only on node 1, and a quorum must consist of 50 % + 1 nodes: in our example, two nodes.
When the limbo sees that the quorum is reached at least for the first transaction in the queue, it begins to operate.
Committing the Transaction
The limbo wakes up and begins to process the queue from the head, ordering the transactions that reached quorum. If several transactions were sent to the replica, logged, and confirmed as a batch, they are processed as one.
The transactions are ordered by their LSNs, so at some point, the queue will reach a transaction that doesn't have a quorum. All the transactions that follow won't have a quorum, either. The limbo could also be empty. For the last transaction with a quorum and the biggest LSN, the limbo makes a COMMIT entry. Since replication is strictly ordered, this entry will also automatically confirm all previous transactions. Therefore, if a transaction with an LSN equal to L reaches a quorum, then all transactions with an LSN < L also reach it. This way, we use fewer entries in the log and save some space.
After the COMMIT entry, all finished transactions are reported to users as successful and deleted from memory.
Let's take a look at an example of how a limbo operates. Here, a cluster has five nodes, and the third node is the leader. The limbo contains transactions waiting for a quorum.
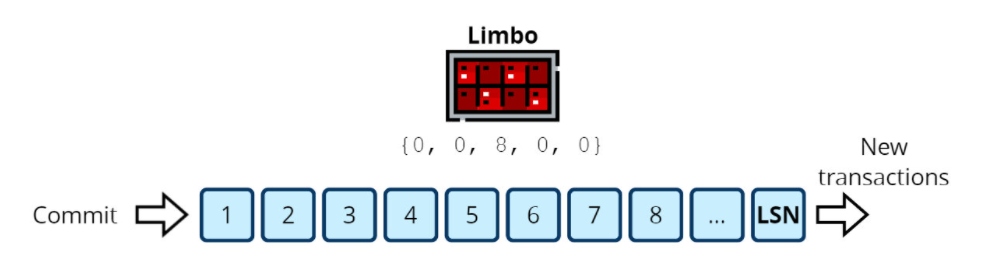
We can't commit anything yet: the latest transaction's LSN equals 1 and has been confirmed only by the leader. Now suppose that some of the replicas confirm several LSNs.
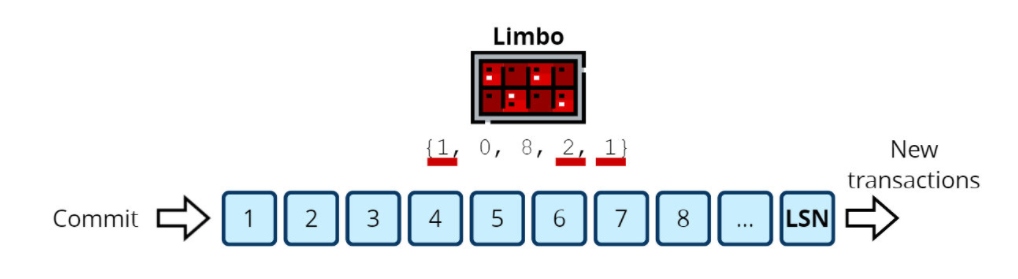
Now, LSN 1 is confirmed by nodes 1, 3, 4, and 5, which is more than half of the nodes. A quorum is reached, and we can commit. The next transaction's LSN equals 2 and has only two confirmations from nodes 3 and 4. It can't be committed, and neither can the following transactions, so we must write "COMMIT LSN 1" in the log.
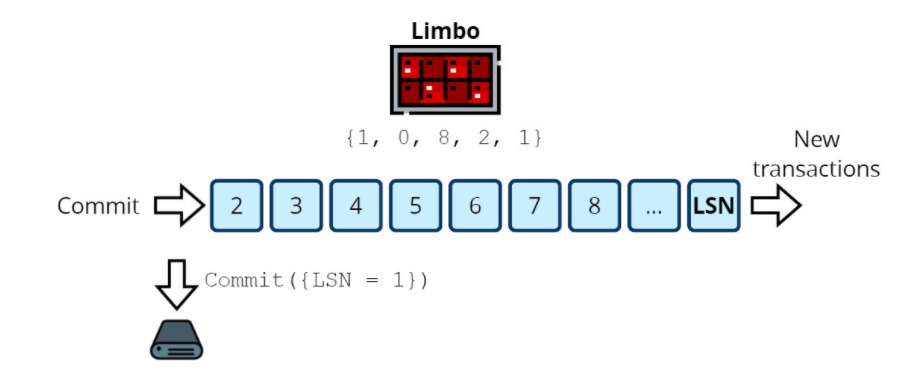
After some time, the limbo receives new confirmations from the replicas.
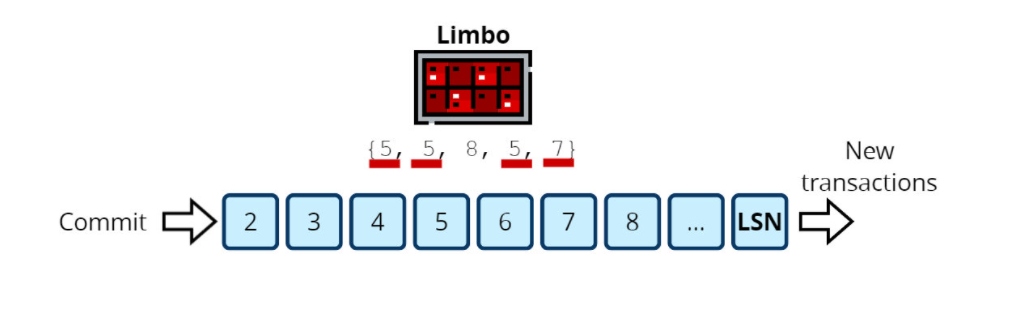
Now we have a quorum on LSN 5. It was confirmed by all nodes, as the corresponding LSNs are greater than or equal to 5. LSN 6 is confirmed only by nodes 3 and 5, which is less than half. The quorum is not reached, so we can commit all LSNs \<= 5.<= 5.
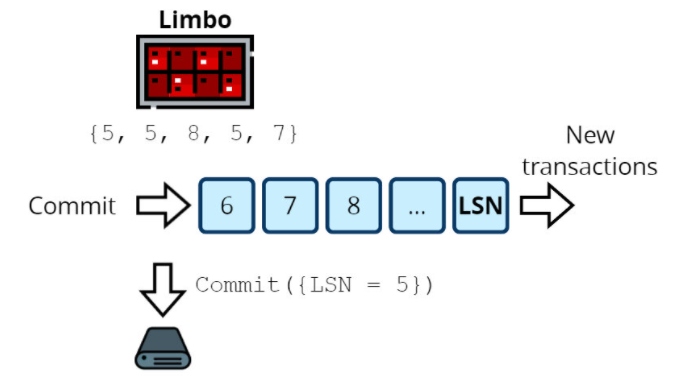
Note how one COMMIT entry finishes four transactions at once.
Since a COMMIT has been recorded in the replicated log, the entry will be sent to the replicas and release the finished transactions in their limbos, the same way as on the leader, except the replicas don't log a further COMMIT entry. They only log the entry sent by the leader.
Transaction Rollback
In some cases, a quorum cannot be reached. For example, there may not be enough active replicas in a cluster, or the replicas, unable to handle the load, may take too long to respond to the leader. Then the queue in the limbo grows faster than it can be processed.
An infinitely growing queue is a typical queue architecture problem. It is usually solved by setting up queue size or timeout. In the case of Tarantool, it would be unreasonable to limit the number of transactions. Instead, synchronous transactions have a timeout: the maximum time to collect confirmations from the replicas.
The timeout is set via a configuration option. If a transaction exceeds the timeout, it is rolled back. All the following transactions are also rolled back because their changes might be based on the previous one. Rolling back all the following transactions is also necessary to keep the log linear. The timeout is a global option. Therefore, if a single transaction exceeds it, the preceding transactions exceed it, too.
As a result, the limbo is fully cleaned up when the oldest transaction exceeds the timeout. Rollback is done via logging a special ROLLBACK entry. It cancels all transactions that are unfinished at the moment.
Keep in mind that the COMMIT and ROLLBACK entries don't need to reach a quorum. Otherwise, there will be an infinite sequence of quorum seeking. A COMMIT entry guarantees that the transaction is applied to at least a quorum of replicas. So if the leader fails, a new one can be chosen from the last quorum. Then the transaction won't be lost.
However, if the cluster loses more than a quorum of replicas, even a commit doesn't guarantee that the transaction won't be lost.
If a ROLLBACK entry was recorded, there are no guarantees whatsoever. Suppose a transaction has obtained a quorum, but the leader hasn't received the confirmations on time, so it records a ROLLBACK, reports a failure to the user, and then suddenly turns off before sending the ROLLBACK entry to the other nodes. The new leader sees the quorum but doesn't see the ROLLBACK entry, so it records a COMMIT instead. As a result, the user is notified of the old leader's failure and then sees the committed transaction on the new leader.
Unfortunately, distributed systems never offer a 100% guarantee. You can keep increasing the system's reliability, but it is physically impossible to create the perfect solution.
Leader Election
If a leader becomes unavailable for some reason, a new one must be elected. It could be done in different ways. For example, the second part of Raft is implemented in Tarantool and conducts the election automatically. There are other algorithms, too.
However, there are some general guidelines that any implementation of leader election must follow. They are explained in this section outside the framework of a specific algorithm.
The new leader must have the biggest LSN relative to the old leader. It guarantees that the new leader will contain the latest committed transactions from the old leader. For that to be true, the new leader should have participated in the latest quorum.
If the wrong node is chosen as a leader, some data may be lost. The new leader becomes the only source of correct data. Therefore, if it misses any committed data, they are considered non-existent, and this state is distributed to the whole cluster.
Let's look at an example. There are five nodes in the cluster. One of them, the leader, creates a transaction to assign the A key a new value of 20 instead of the old value, 10. For this transaction, it obtains a quorum of three nodes, commits it, and sends a response to the client.
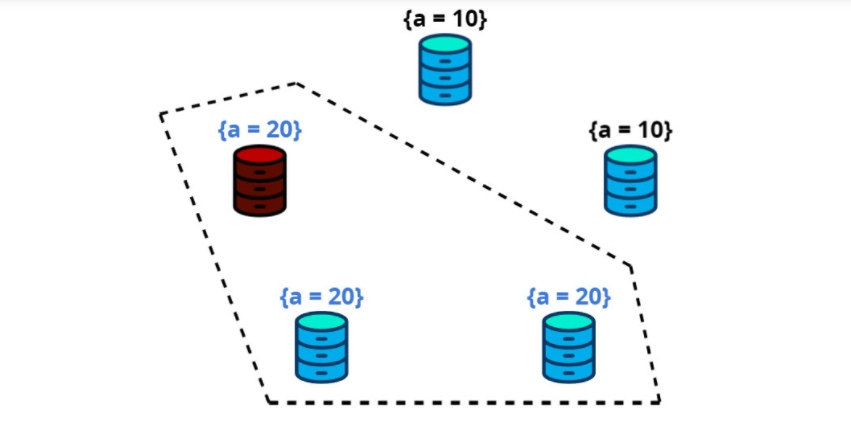
Then the leader is destroyed before sending the transaction to the other two nodes.
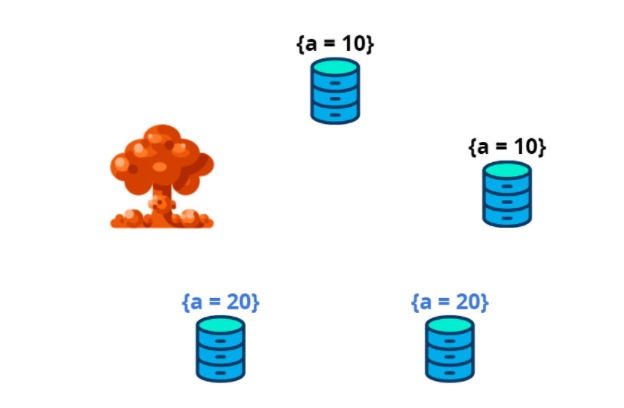
Only one of the nodes inside the blue outline can become the new leader. If one of the nodes inside the red outline becomes a leader, it will force the state {a = 10} on the other nodes. The transaction will be lost even though it reached quorum, was committed, and more than half of the cluster is still intact.
After the leader is chosen, all remaining transactions in the old leader's limbo must be finished. This is done using the box.ctl.clear_synchro_queue() function. It waits until the unfinished transactions reach a quorum and logs a COMMIT on behalf of the old leader. The limbos in the cluster are emptied when the other nodes receive this COMMIT via replication. The new leader assigns the empty limbo to itself and is ready to go.
It should be noted that cleaning the transaction queue doesn't roll anything back: clear_synchro_queue can only wait for the quorum and make commits. It happens because when the old leader fails, the new leader doesn't know if any pending transactions have been finished on the old leader and reported to the user as successful.
Indeed, the old leader might have gathered a quorum, written a COMMIT, reported success to the user, and then failed along with several other nodes in the quorum while more than half of the cluster would still be intact. Then the new leader would see that the transaction doesn't have a quorum at the moment. However, the leader cannot be certain that it hasn't been committed, so it must wait.
On the other hand, even if a transaction was rolled back on the old leader, its commit on the new leader is completely valid; but it is true only if the ROLLBACK hasn't been distributed to the whole cluster yet because ROLLBACK doesn't provide any guarantees.
Interface
The functions to work with synchronous replication in Tarantool are divided into two groups: managing synchronous/asynchronous mode and leader election. To make a space synchronous, set is_sync = true when creating or altering the space.
Creating a space:
box.schema.create_space('test', {is_sync = true})Altering a space:
box.space[‘test’]:alter({is_sync = true})Now any transaction altering the synchronous space becomes synchronous. You can configure synchronous mode parameters with global options:
box.cfg{
replication_synchro_quorum = <count or expression>,
replication_synchro_timeout = <seconds>,
memtx_use_mvcc_engine = <boolean>
}replication_synchro_quorumis the number of nodes that must confirm the transaction before the leader can commit it. It can be a number or a function of the cluster's size. For example, the canonical form isbox.cfg{replication_synchro_quorum = «N/2 + 1»}, which means the quorum comprises 50 % + 1 nodes. Tarantool substitutes N with the number of nodes known to the leader. You can set the quorum larger than the canonical formula to increase reliability, but choosing half of the nodes or less is unsafe.replication_synchro_timeoutis the number of seconds within which a transaction has to reach a quorum. It can be a fraction, so you can set almost any precision. After a transaction exceeds the timeout, ROLLBACK is logged for all pending transactions, and they are rolled back.memtx_use_mvcc_engineis used to avoid dirty reads. There were always dirty reads in Tarantool because the changes made by asynchronous transactions were visible before they were logged. It became a serious problem when synchronous replication appeared, but we couldn't turn off dirty reads by default because it would break compatibility with the existing applications. Besides, turning off dirty reads is a lot of additional transaction processing, which may affect the general performance. That is why there is an option to control dirty reads. By default, dirty reads are turned on.
There are several options for automated leader election, which are covered in a separate article. Alternatively, you can run elections manually or use your own algorithms with Tarantool's API.
To find the new leader, you need to know which node has the second-biggest LSN. Use box.info.vclock that contains the node's vclock and find the old leader's component in this vclock. You could also try finding the node where all vclock parts are greater than or equal to all vclock parts on the other nodes, but you might encounter incomparable vclocks.
After finding the candidate, call box.ctl.clear_synchro_queue() on it. Until this function returns success, the leader cannot create new transactions.
Differences From Raft
Identifying Transactions
The main difference between Tarantool and Raft is how they identify transactions. This difference arises from the log formats. In Raft, there is only one log, and it has no vector values in it. Raft log entries have the format {{key = value}, log_index, term}. In Tarantool terms, it is the transaction's changes and LSN. Tarantool doesn't store terms in entries or keep a sequence of log_index values. Therefore, it must store replica IDs. In Tarantool, LSNs are computed individually on each node for the transactions this node created.
However, these problems are not severe enough to be blocking. First, there is only one node that creates transactions, and only one vclock component changes each time: the one with the ID that equals the replica ID of the leader. So the log is, in fact, linear as long as the leader is known and keeps working. Second, storing terms in all entries is unnecessary and can be expensive. It's enough to log when the term has changed and store the current term number in memory. The leader election module does that apart from synchronous replication.
Difficulties arise when the leader changes. Then the LSN count must be moved to another part of vclock with a different replica ID, and it must be done for the whole cluster. To do that, the new leader finishes the old leader's transactions, takes over the limbo, and begins generating its own transactions. The same happens on the replicas. They receive COMMIT and ROLLBACK for the old leader's transactions, followed by new transactions with a different replica ID. Limbos of the whole cluster switch automatically when they are emptied and begin receiving transactions with another replica ID.
It is almost like 31 Raft protocols run in the cluster by turns.
No Log Rollback
Log properties, however, are a serious problem. According to Raft, you must have the ability to roll back the log, or delete transactions from the end. In Raft, it happens when a new cluster leader has been elected, but there might still be replicas whose log is ahead of the leader's log. For example, some candidates could have been down during the election but become available later. These replicas cannot contain committed data. Otherwise, this data would have the quorum and be on the new leader. Raft removes the head of these replicas' logs to make sure that each replica's log is a prefix of the leader's log.
In Tarantool, there is no rollback for the log because it is a redo log, not an undo log. Besides, the Tarantool architecture doesn't allow rolling back LSNs. If there are replicas ahead of the new leader in the cluster, Tarantool has no choice but to delete and reconnect them, downloading all data from the leader. This is called a "rejoin."
However, we are working on making it possible to roll back without deleting and reconnecting replicas.
Conclusion
Synchronous replication has been available in Tarantool since the 2.5 release, and automated election since the 2.6 release. Currently, they are still beta features. They haven't been properly tested on real systems, and the interfaces and user experience may change. While the existing realization is being polished, there are plans to optimize and extend it. The optimizations are mostly technical.
As for extensions, the Tarantool vector log format allows implementing "master-master" synchronous replication where transactions can be created on more than one node at the same time. Master-master has already been implemented in asynchronous replication, where it helps distribute the load of write transactions that involve complex computations. It will also be useful in synchronous replication.
In conclusion, I'd like to spell out one of the main lessons that is not related to implementation: when designing a large and complex task, too much planning can do serious harm. Sometimes it's easier and more efficient to create a working prototype of the required feature and develop it step-by-step rather than try to do everything at once and perfectly.
In addition to developing synchronous replication, we are planning some equally exciting things in future Tarantool releases, partly related to synchronization. We can already shed a bit of light on some of them.
Transactions in the Binary Protocol
Since Tarantool was created, it couldn't process "long" transactions (consisting of more than one expression) directly over the network using only a remote Tarantool connector. For any operation more complicated than one replace/delete/insert/update, you had to write Lua code that would do the necessary operations in one transaction and call this code as a function.
At the moment, we plan to implement transaction creation right in the network protocol. For a Lua client, it will look like this:
c = netbox.connect(host)
c:begin()
c.space.test1:replace{100}
c.space.test2:delete({5})
c:commit()No server-side code is required. It will be possible to work with synchronous transactions this way as well.
Transaction Options
A transaction commit in Tarantool is always a blocking operation. The current fiber stops executing code until the commit is complete. It can take quite a long time, which increases the latency for sending a response to the client, even if it's unnecessary to wait for the commit to complete. This is especially problematic with synchronous transactions, which can take milliseconds to commit.
We are developing an extension of the commit interface that will make it possible to avoid blocking the fiber. It will look like this:
box.begin()
box.space.test1:replace{100}
box.commit({is_lazy = true})
box.begin()
box.space.test2:replace{200}
box.space.test3:replace{300}
box.commit({is_lazy = true})Both box.commit() functions will return control immediately, and the transaction will be logged and committed at the end of the Tarantool event loop iteration. This approach can reduce the latency and make better use of WAL thread resources: Tarantool will be able to batch write more transactions to disk by the end of the event loop iteration.
In addition, it can sometimes be convenient if not a whole space is synchronous but only specific transactions, even those applied to asynchronous spaces. To make it possible, we plan to add another option to box.commit() — is_sync. It will look like this: box.commit({is_sync= true}).
Monitoring
Currently, there is no way to know how many synchronous transactions are waiting in the limbo to be committed. Also, there is no way to know the quorum value if replication_synchro_quorum is an expression. For example, if the "N/2 + 1" expression was used, then the code cannot find out the actual quorum value in any reasonable way (an unreasonable way does exist).
To make these unknown values more accessible, we are developing a separate monitoring function, box.info.synchro.
