Spark Structured Streaming Joins

Objective
In this article, we'll look at the different joins available in Spark Structured Streaming. In a streaming job, you may have multiple static and streaming data sources. You may have to join them to implement various functionalities. We will see how Spark Structured Streaming handles various types of joins with both static and streaming datasets.
Overview
The table below gives you an overview of different types of streams on the left/right and what is supported/unsupported in Structured Streaming.
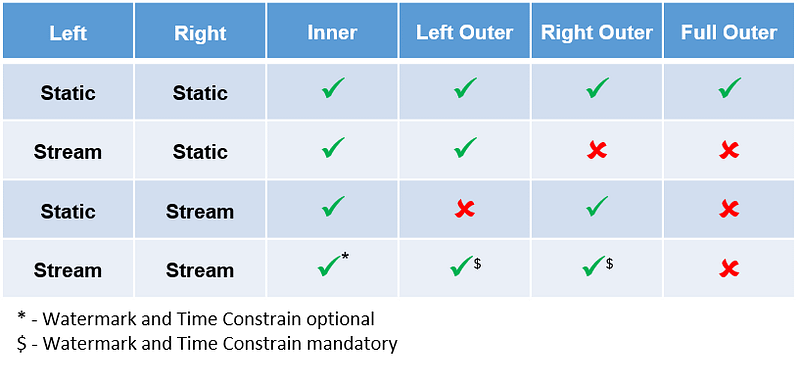
Inner Join
From the table above, it's clear that inner join is supported irrespective of whether it is a static or streaming dataset. An inner join on streaming and static datasets doesn’t have to be stateful as the set of records in the stream will be matched with a static set of records. An inner join with a static and streaming join is not stateful, whereas when you inner join two streaming datasets, optionally you can watermark and add a time constraint to it. We will discuss the inner joining of two streaming datasets in a later section.

Full Outer Join
A full outer join is supported only when two static datasets are joined. From the table below, it’s clear that a full outer join is not supported if a streaming dataset is involved. One of the reasons for not supporting a full outer join in any of the streaming datasets is due to the fact that both left and right don’t have to wait for each other's matching data to arrive. In streaming, due to late arriving data, a given record may not match with its corresponding record in the same window and this may result in very inconsistent output when you use a full outer join.
Static Data and Static Joins

When a static dataset is used in a streaming job the data is loaded only once at the beginning of the job. When you join two static datasets all types of joins are supported. We will not go into detail about the two types of static join datasets in this article.
Streaming Data and Static Joins

When a streaming dataset and a static dataset are used in the above configuration, then only an inner join and a left outer join are supported. Right outer joins and full outer joins are not supported.

In my view, the right outer join is not required, as only static data will be returned as output in that micro-batch, which may not be of much use. For the same reason, I believe the full outer join is also not supported. A left outer join, on its own, is good enough to return a streaming record when there is no matching static record.

Inner joins and left outer joins on streaming and static datasets don’t have to be stateful, as the streaming set of records in a given window can be matched with a static set of records.
Sample Code
Refer to the code below to join a streaming dataset with a static dataset. Checkout working examples here.
val leftOuterJoinDS = streamingEmployeeDS.join(staticDepartmentDS, $"departmentId" === $"id", "left_outer")Static Data and Stream Joins

When we have a static dataset on the left and a streaming dataset on the right, then only an inner join and a right outer join are supported. Left outer joins and full outer joins are not supported.
In my view, a left outer join is not required, as only static data will be returned as output in that micro-batch, which may not be of any use. For the same reason, I believe the full outer join is also not supported. Right outer joins, alone, are good enough to return a streaming record when there is no matching static record.

Inner joins and right outer joins on static and streaming datasets don’t have to be stateful, as the streaming set of records in a given window will be matched with a static set of records.
Sample Code
Refer to the code below to join a static dataset with streaming dataset. Checkout working examples here.
val rightOuterJoinDS = staticDepartmentDS .join(streamingEmployeeDS, $"id" === $"departmentId", "right_outer")Streams and Stream Joins
Joining two streaming datasets is supported only from Spark version 2.3 on.

Stream — Stream (Inner Join)
Add description

When you inner join two streaming datasets watermarking and time constraint is optional. If watermark and time constraints are not specified then data is stored in the state indefinitely. Setting watermark on both sides and time constraint will enable state cleanup accordingly.
Stream to Stream (Left and Right Outer Join)

Both left and right outer joins are conditionally supported in structured streaming. When you left/right outer joins, two streaming datasets watermarking and time constraints are mandatory. When you use a left outer join, you have to make sure the dataset on the righthand side is watermarked with a time constraint and vice-versa. I strongly recommend watermarking both sides for state cleanup.

Watermark vs. Time Constraint
It’s very important to understand the difference between watermark and time constraint. Watermarking a stream decides how delayed a record can arrive and gives a timeline after which the records can be dropped. For example, if you set a watermark for 30 minutes, then records older than 30 minutes will be dropped/ignored. Time constraints decide how long records will be retained in Spark's state in correlation to the other stream.

In the example above, when the following values are set, then Spark will automatically decide Spark's state duration as three hours for stream 1 and one hour for stream 2.
Stream 1 watermark = 1 hour
Stream 2 watermark = 2 hours
Time constraint: Stream 1 time >= stream 2 time AND stream 1 time <= stream 2 time + interval 1 hourSample Code
Refer code below to join two streaming dataset. Checkout working examples here.
Watermark
val employeeStreamDS = rateSourceData.withWatermark("empTimestamp", "10 seconds")Time constraint
val joinedDS = departmentStreamDS.join(employeeStreamDS, expr(""" id = departmentId AND empTimestamp >= depTimestamp - interval 1 minutes AND empTimestamp <= depTimestamp + interval 1 minutes """ ), "left_outer")Summary
For two static streams, all types of joins are supported. When a static and stream is joined, inner join and the side of stream dataset is supported, i.e. if a streaming dataset is on the left then a left outer join is supported, otherwise, a right outer join is supported. When two streams are joined, inner, left outer, and right outer joins are conditionally supported. It is recommended to apply watermarking on both sides and time constraints for all joins.
