Telemetry Pipelines Workshop: Metric Collection Processing

This article is part of a series exploring a workshop guiding you through the open-source project Fluent Bit, what it is, a basic installation, and setting up the first telemetry pipeline project. Learn how to manage your cloud native data from source to destination using the telemetry pipeline phases covering collection, aggregation, transformation, and forwarding from any source to any destination.
The previous article in this series saw us solving the use case for parsing multiple events using telemetry pipelines with Fluent Bit. In this article, we continue onwards with the use case covering metric collection processing. You can find more details in the accompanying workshop lab.
Let's get started with this use case.
Before we get started it's important to review the phases of a telemetry pipeline. In the diagram below we see them laid out again. Each incoming event goes from input to parser to filter to buffer to routing before they are sent to their final output destination(s).
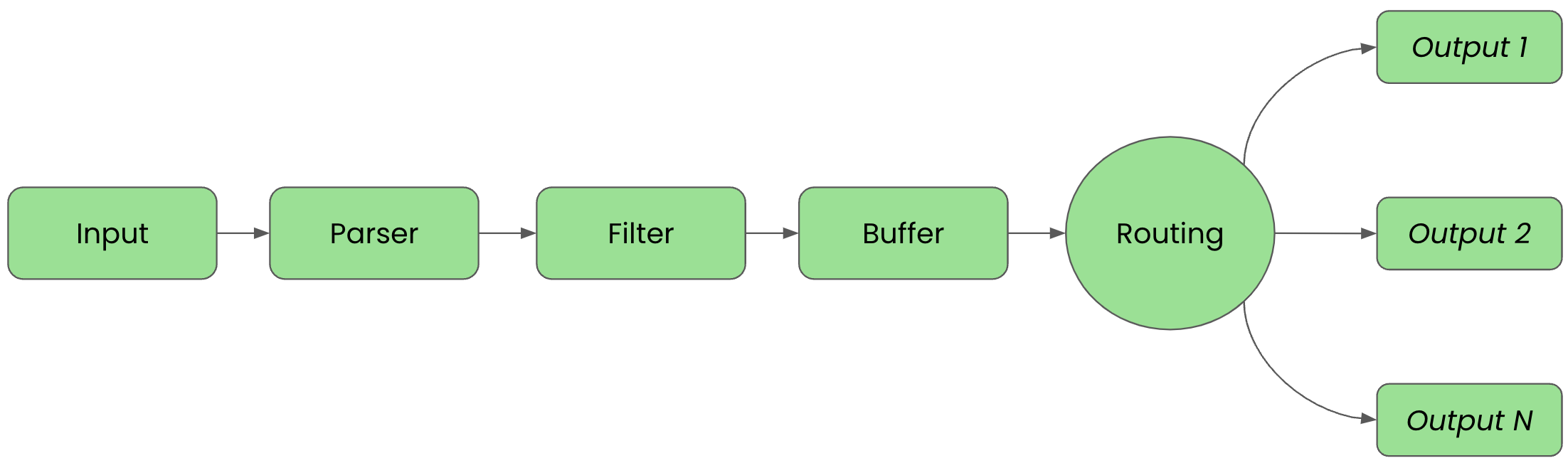
For clarity in this article, we'll split up the configuration into files that are imported into a main fluent bit configuration file we'll name workshop-fb.conf.
Metric Collection Processing
For the next telemetry pipeline, we'll expand the configuration from the previous article to collect metrics from our Fluent Bit instance and then expose them as a Prometheus metrics endpoint. We continue on with our previous configuration files, starting with the INPUT phase adding metrics from Fluent Bit to inputs.conf:
# This entry generates a success message for the workshop.
[INPUT]
Name dummy
Tag event.success
Dummy {"message":"true 200 success"}
# This entry generates an error message for the workshop.
[INPUT]
Name dummy
Tag event.error
Dummy {"message":"false 500 error"}
# This entry collects fluent bit metrics for the workshop.
[INPUT]
Name fluentbit_metrics
Tag fb_metrics
Host 0.0.0.0
Scrape_Interval 5s
We are using the fluentbit_metrics input plugin to collect metrics on set intervals. There are three keys used to set up our inputs:
Name- The name of the plugin to be usedTag- The tag we assign, can be anything, to help find events of this type in the matching phaseHost- The instance to gather metrics from, our local machineScrape_Interval- How often metrics are collected
Our configuration is tagging each successful event with fb_metrics, which is needed in the output phase to match to these events.
Now let's expand the output configuration file outputs.conf using our favorite editor. Add the following configuration:
# This entry directs all tags (it matches any we encounter)
# to print to standard output, which is our console.
[OUTPUT]
Name stdout
Match *
# This entry directs all events matching the tag to be exposed as a
# Prometheus endpoint on the given IP and port number while adding
# a few tags.
[OUTPUT]
Name prometheus_exporter
Match fb_metrics
Host 0.0.0.0
Port 9999
# add user-defined labels
Add_Label app fluent-bit
Add_Label workshop lab4
With our inputs and outputs configured, we can ignore filtering and parsing for now. In our main configuration file workshop-fb.conf, we leave everything as it was in the previous article:
# Fluent Bit main configuration file.
[SERVICE]
parsers_file parsers.conf
# Imports section.
@INCLUDE inputs.conf
@INCLUDE outputs.conf
@INCLUDE filters.conf
To see if our metrics pipeline configuration works, we can test-run it with our Fluent Bit installation, first using the source installation followed by the container version. Below the source install is shown from the directory we created to hold all our configuration files:
# source install. # $ [PATH_TO]/fluent-bit --config=workshop-fb.conf
The console output should look something like this, noting that we've cut out the ASCII logo at start-up:
...
[2024/04/10 15:44:13] [ info] [input:dummy:dummy.0] initializing
[2024/04/10 15:44:13] [ info] [input:dummy:dummy.0] storage_strategy='memory' (memory only)
[2024/04/10 15:44:13] [ info] [input:dummy:dummy.1] initializing
[2024/04/10 15:44:13] [ info] [input:dummy:dummy.1] storage_strategy='memory' (memory only)
[2024/04/10 15:44:13] [ info] [input:fluentbit_metrics:fluentbit_metrics.2] initializing
[2024/04/10 15:44:13] [ info] [input:fluentbit_metrics:fluentbit_metrics.2] storage_strategy='memory' (memory only)
[2024/04/10 15:44:13] [ info] [output:stdout:stdout.0] worker #0 started
[2024/04/10 15:44:13] [ info] [output:prometheus_exporter:prometheus_exporter.1] listening iface=0.0.0.0 tcp_port=9999
[2024/04/10 15:44:13] [ info] [sp] stream processor started
[0] event.success: [[1712756654.565023000, {}], {"valid_message"=>"true", "code"=>"200", "type"=>"success"}]
[0] event.error: [[1712756654.566612000, {}], {"valid_message"=>"false", "code"=>"500", "type"=>"error"}]
[0] event.success: [[1712756655.565109000, {}], {"valid_message"=>"true", "code"=>"200", "type"=>"success"}]
[0] event.error: [[1712756655.565459000, {}], {"valid_message"=>"false", "code"=>"500", "type"=>"error"}]
[0] event.success: [[1712756656.561462000, {}], {"valid_message"=>"true", "code"=>"200", "type"=>"success"}]
[0] event.error: [[1712756656.561594000, {}], {"valid_message"=>"false", "code"=>"500", "type"=>"error"}]
[0] event.success: [[1712756657.564943000, {}], {"valid_message"=>"true", "code"=>"200", "type"=>"success"}]
[0] event.error: [[1712756657.565054000, {}], {"valid_message"=>"false", "code"=>"500", "type"=>"error"}]
[0] event.success: [[1712756658.565192000, {}], {"valid_message"=>"true", "code"=>"200", "type"=>"success"}]
[0] event.error: [[1712756658.565392000, {}], {"valid_message"=>"false", "code"=>"500", "type"=>"error"}]
2024-04-10T13:44:18.565531017Z fluentbit_uptime{hostname="Erics-Pro-M2.local"} = 5
2024-04-10T13:44:18.565354809Z fluentbit_input_bytes_total{name="dummy.0"} = 235
2024-04-10T13:44:18.565354809Z fluentbit_input_records_total{name="dummy.0"} = 5
2024-04-10T13:44:18.565463183Z fluentbit_input_bytes_total{name="dummy.1"} = 230
2024-04-10T13:44:18.565463183Z fluentbit_input_records_total{name="dummy.1"} = 5
...
We see the previous pipeline event processing, and then after 5 seconds, the Fluent Bit metrics from our machine are collected before going back to the previous pipeline messages. This cycles every 5 seconds until exiting with CTRL_C.
Fluent Bit metrics collection pipeline is cycling through metrics collection every 5 seconds and it's exposing a Prometheus-compatible metrics endpoint which you can verify in a web browser using http://localhost:9999/metrics:
# HELP fluentbit_uptime Number of seconds that Fluent Bit has been running.
# TYPE fluentbit_uptime counter
fluentbit_uptime{app="fluent-bit",workshop="lab4",hostname="Erics-Pro-M2.local"} 5
# HELP fluentbit_input_bytes_total Number of input bytes.
# TYPE fluentbit_input_bytes_total counter
fluentbit_input_bytes_total{app="fluent-bit",workshop="lab4",name="dummy.0"} 235
# HELP fluentbit_input_records_total Number of input records.
# TYPE fluentbit_input_records_total counter
fluentbit_input_records_total{app="fluent-bit",workshop="lab4",name="dummy.0"} 5
# HELP fluentbit_input_bytes_total Number of input bytes.
# TYPE fluentbit_input_bytes_total counter
fluentbit_input_bytes_total{app="fluent-bit",workshop="lab4",name="dummy.1"} 230
# HELP fluentbit_input_records_total Number of input records.
# TYPE fluentbit_input_records_total counter
fluentbit_input_records_total{app="fluent-bit",workshop="lab4",name="dummy.1"} 5
# HELP fluentbit_input_bytes_total Number of input bytes.
# TYPE fluentbit_input_bytes_total counter
fluentbit_input_bytes_total{app="fluent-bit",workshop="lab4",name="fluentbit_metrics.2"} 0
# HELP fluentbit_input_records_total Number of input records.
# TYPE fluentbit_input_records_total counter
fluentbit_input_records_total{app="fluent-bit",workshop="lab4",name="fluentbit_metrics.2"} 0
# HELP fluentbit_input_metrics_scrapes_total Number of total metrics scrapes
# TYPE fluentbit_input_metrics_scrapes_total counter
fluentbit_input_metrics_scrapes_total{app="fluent-bit",workshop="lab4",name="fluentbit_metrics.2"} 1
# HELP fluentbit_filter_records_total Total number of new records processed.
# TYPE fluentbit_filter_records_total counter
fluentbit_filter_records_total{app="fluent-bit",workshop="lab4",name="message_cleaning_parser"} 10
# HELP fluentbit_filter_bytes_total Total number of new bytes processed.
# TYPE fluentbit_filter_bytes_total counter
fluentbit_filter_bytes_total{app="fluent-bit",workshop="lab4",name="message_cleaning_parser"} 625
...
Let's now try testing our configuration by running it using a container image. We can continue to use the previous Buildfile we created to build a new container image and insert our configuration files.
$ podman build -t workshop-fb:v5 -f Buildfile STEP 1/6: FROM cr.fluentbit.io/fluent/fluent-bit:3.0.1 STEP 2/6: COPY ./workshop-fb.conf /fluent-bit/etc/fluent-bit.conf --> d43439e7a9ee STEP 3/6: COPY ./inputs.conf /fluent-bit/etc/inputs.conf --> 7cd7ccd760f9 STEP 4/6: COPY ./outputs.conf /fluent-bit/etc/outputs.conf --> f2ecf24abe9e STEP 5/6: COPY ./filters.conf /fluent-bit/etc/filters.conf --> 53e639fbd264 STEP 6/6: COPY ./parsers.conf /fluent-bit/etc/parsers.conf COMMIT workshop-fb:v5 --> 821bf26f6d64 Successfully tagged localhost/workshop-fb:v5 e74b2f22872958a79c0e056efce66a811c93f43da641a2efaa30cacceb94a195
Now we'll run our new container image, but we need a way for the container to write to the two log files so that we can check them (not internally on the container filesystem). We mount our local directory to the containers tmp directory so we can see the files on our local machine as follows:
$ podman run workshop-fb:v5
The output looks exactly like the source output above, just with different timestamps. Again, you can stop the container using CTRL_C. Also note the container metrics collection pipeline is exposing a Prometheus-compatible metrics endpoint, which you can verify in a web browser using http://localhost:9999/metrics, just like above.
Once you have your metrics collection pipeline up and running, you can configure a Prometheus instance to scrape the provided endpoint, which stores them in a time series database, and provides you with the ability to query them for visualization and dashboard creation.
This completes our use cases for this article, be sure to explore this hands-on experience with the accompanying workshop lab.
What's Next?
This article walked us through the use case for metric collection processing using telemetry pipelines with Fluent Bit. The series continues with the next step where we'll zoom in on routing events to their correct output destinations.
Stay tuned for more hands on material to help you with your cloud-native observability journey.
