Leveraging Apache Airflow on AWS EKS (Part 1): Foundations of Data Orchestration in the Cloud

Introduction to Data Orchestration in the Cloud
In an era that is packed with data-driven actions, companies now have to solve the problem of orchestrating their cloud-based data. Amid the growing pace of the data volume, variation, and velocity, efficient cloud data workflow management is becoming more and more essential. This write-up is the beginning of our examination of how Apache Airflow bridges this gap, especially in the section dealing with Amazon Web Services (AWS) and the Elastic Kubernetes Service (EKS).
Companies that want to make the most out of their data assets through the orchestration of data workflows in the cloud face this strategic challenge, though this could be a tough and complex job more so when dealing with huge volumes of data. Streamlined and extendable data processing plays a critical role. In an age where data is the source of decision-making, innovation, as well as competitiveness, companies have to revise their data management strategies. The data management skills that come with working and coordinating in the cloud not only increase operational efficiency but also provide the foundation on which the discovery of important information and the making of wise decisions are built.
Challenges in Cloud-Based Data Orchestration
Data infrastructure migration to the cloud requires organizations to manage the complexity of the data operation more effectively. Apache Airflow is a tool that covers the essentials for designing and managing complicated data pipelines, combining it with flexibility and scalability. The next parts will be tailored to Apache Airflow in-depth integration with prominent technologies are Kubernetes (K8s), Snowflake, Terraform, and Data Build Tool (DBT), and show how these tools altogether can improve cloud data orchestration on AWS EKS. With the sensitivity of examining actual use cases, best practices, and practical examples, this analysis aims to provide organizations with the needed know-how to successfully navigate through the changing environment of data orchestration in the cloud.
Integration With Key Technologies
This investigation covers all the key technologies caused by this integration. Snowflake, being a cloud-based data warehouse and having the edge over other data integrators, serves as the core foundation here showing how it fits in and helps Apache Airflow. On top of that, the orchestra is touched upon in the domain of the Terraform tool which allows you to write an infrastructure as a code and in the jargon of DBT, a tool of data transformation. The service utilizes the integration capabilities with EKS/Kubernetes to implement containerization, which together with the industry movement toward containers on AWS, in turn, echoes the shift of the industry towards containerized solutions on AWS.
Addressing the Gap in Literature
The total IT landscape is in a state of flux, which is the reason why the gap in the current research literature on the application of these technologies in data feeder orchestration on the cloud becomes much more meaningful. Apart from the technicality of systematically integrating Apache Airflow, Snowflake, Terraform, DBT, and EKS/Kubernetes on AWS, such as the connection of data workflows, there is still a lack of literature addressing all of these functions. The purpose of this article is to fill the gap that exists where there is no nuanced way of understanding the synergy of these technologies presented, provide the reader with more practical insights, and link all pillars current table in the available literature. The lack of a combined source of information on the complexity of integration processes is what created a substantial gap to be addressed. This article addresses this gap. The real-world use cases and practical examples will enable the organizations to have the know-how they need to successfully strategize for dealing with and improving their data orchestration practices on the cloud.
Related Work
As organizations are adopting cloud-based infrastructures at a fast pace, the number of studies that discuss the orchestration of different key technologies like Apache Airflow, SnowFlake, Terraform, DBT, and EKS/Kubernetes witnessed a jump in number. Studies reveal the emerging trend in cloud-based data variation. Nevertheless, when there are incomplete or undermined data management processes in cloud computing, organizations become susceptible to security vulnerabilities, and the integrity and confidentiality of sensitive data are compromised. This could result in data silos affecting the smooth collaboration as well as data-dependent decision-making. Lastly, if proper resource utilization is not handled well, then operation costs may zoom upwards.
Literature Review
A lot of academic papers advanced that Apache Airflow is a tool for workflow automation that allows you to build and orchestrate complex data workflows. Research done by BP Harenslak and J de Ruiter (2021) shows the Data pipelines with Apache Airflow - adaptable using Apache. They provide you with the initial steps in the process. The research paper "Building and Maintaining Metadata Aggregation Workflows Using Apache Airflow" covers a practical view targeted to industrial group usage. Another example is the "Developing Practical Data Pipelines using Apache Airflow on Google Cloud Platform” tutorial by Sameer Shukla (2022), which introduces certain Airflow concepts working on a related platform to AWS.
Snowflake has been widely discussed under the category of cloud-based data warehouse. Big data handling was tackled by Karthik Allam, Madhu Ankam, and Manohar Nalmala in their research. It showcased the scalability and efficiency of Snowflake (2023). The expression of infrastructure as code and cloud-based data and orchestration sets the focus of the article under the name of Campbell, B. (2020), stating that with Terraform, infrastructure provisioning and management on cloud platforms, particularly within AWS, becomes much more simplified.
Data transformation tools research reveals the need for and significance of DBT. Cyr and Do focused on the session "DBT in Production" by explaining this important tool used by data analysts to ensure fast and high-quality insights. The container orchestration literature has become popular, particularly within the AWS ecologism. Algarni (2021) looks at web application manageability on AWS using EKS and enumerates the advantages and challenges that come with that integration.
Gap in Literature
Although existing literature provides insights on these individual technologies, it lacks much of the integration subsystem in the case of Apache Airflow that connects all the things and uses them in an orchestrated way to support large volumes of data and overall efficiency.
Objective
In contrast to existing studies, this paper systematically addresses the integration of Apache Airflow on AWS EKS, delving into enhancing process capability with Snowflake, Terraform, and Data Build Tool to manage cloud data workflows. This article aims to fill this void by providing a nuanced understanding of how these technologies synergize.
Data Orchestration Challenges in the Cloud
The immediate comprehension of the challenges that might be faced in the process of data orchestration in the cloud is critical for organizations that are striving to execute competent cloud-based data orchestration strategies. Methods are usually a mixture of strong technology implementations, effective norms, and standards, as well as periodic checks and assessments to avoid performance deficiencies. The knowledge that Table 1 shows will be shared and the techniques will get along with each other.
| Challenges | Elaboration | Implication | How the Technology Helps |
|---|---|---|---|
| Scalability Issues |
The scalability problem of the data orchestration in the cloud setting becomes pressing as the workload changes; for example, a huge data flow using a data warehouse. As dataset shapes or sizes grow or fluctuate, orchestrating tasks at scale complexity seems to appear.
|
The flexibility of scaling is likely to raise bottlenecks, increase processing time, and resource inefficiencies which eventually will be unable to efficiently deal with dynamic workloads.
|
Apache Airflow: Adaptively scales workloads through distributed architecture to optimize the efficient operation of all the workloads. This website offers a one-stop shop to simplify the college search and application process through comprehensive tools, guidance, and resources. Snowflake: Based on its native cloud architecture, the automation of all necessary processes is provided, including increasing the data set volumes without any operational difficulties. DBT: It accommodates scaled-up transformations of data and allows organizations to quickly process and analyze big data. Terraform: Provides a possibility for the formation of it as well as appropriate proportions of the resources in the cloud, according to the demand changes. |
| Data Integration Complexities |
One issue that has come to the front in the past few years is the matter of data intake from multiple different sources as well as formats. In a cloud environment, which puts the data in separate storage systems, this has to be dealt with serenely and precisely. |
Synchronization intricacies may result in inconsistencies, misprints, and delays that undermine the reliability and significance of the outcomes retrieved from orchestrated workflows. |
Apache Airflow: Provides operators and hooks for integrating with various data sources, facilitating seamless data movement and transformation within orchestrated workflows. Snowflake: Offers native connectors and integrations, streamlining the integration of diverse data sources into its cloud-based data warehouse. DBT: Integrates with various data warehouses, including Snowflake, and provides a structured framework for managing data transformations. Terraform: Allows infrastructure-as-code definitions, ensuring consistent and repeatable integration of cloud resources into orchestrated workflows. |
| Security Concerns |
Securing data and data in transit and at rest throughout a procedure of orchestration is full of complexity as well. Access control, encryption, and compliance with industry standards took place as key elements. |
Security lapses can expose sensitive information, leading to data breaches, compliance violations, and reputational damage for organizations leveraging cloud-based data orchestration. |
Apache Airflow: Supports secure connections and authentication mechanisms, contributing to the overall security of orchestrated workflows. Snowflake: Implements robust security features, including encryption, access controls, and compliance certifications, ensuring secure data storage and processing. DBT: Supports encryption and access controls, enhancing the security of data transformation processes. Terraform: Enables the definition of security configurations as code, ensuring secure provisioning and management of cloud resources. |
| Orchestration of Hybrid Architectures |
Organizations often operate in hybrid cloud environments, combining on-premises and multiple cloud platforms. Orchestrating data workflows seamlessly across these diverse architectures presents challenges in terms of connectivity and interoperability. |
Discrepancies in the managing processes atop hybrid topologies are likely to give origin to the data inconsistencies, higher latency, and inefficient collaboration among the sections of such structures. |
Apache Airflow: Supports the orchestration of workflows across hybrid environments, allowing organizations to seamlessly integrate on-premises and multiple cloud platforms. Snowflake: Functions as a cloud-native data warehouse, facilitating data processing across various cloud environments. DBT: This can be utilized across hybrid environments, allowing organizations to transform data regardless of its location. Terraform: Provides a unified approach to managing infrastructure across hybrid cloud architectures, ensuring consistency and compatibility. |
| Resource Management and Cost Optimization |
Regarding efficient management of cloud resources, computation, storage, and network, price optimization is a cost-effective thing to worry about. Failures to allocate resources to the respective areas and to the utilization of all the resources in the best way result in increased operational costs. |
Inefficient resource management may result in higher-than-necessary cloud expenditures, impacting the overall cost-effectiveness of data orchestration processes. |
Apache Airflow: Allows dynamic allocation and deallocation of resources based on workflow demands, contributing to cost-efficient resource management. Snowflake: Offers automatic scaling and resource optimization features, aligning resource usage with actual requirements. DBT: Supports efficient resource usage in data transformation processes, contributing to overall cost optimization. Terraform: Enables definition of infrastructure requirements in code, optimizing resource provisioning and utilization for cost-effectiveness. |
| Workflow Monitoring, and Debugging |
Monitoring and debugging of orchestrated workflow in near real-time might be the key factor to reliability and error fixing and therefore should be in place. The day-to-day operation of orchestration workflows with real-time monitoring and debugging is pivotal for the pursuit of stability and resolving popping-up problems. |
Declaration of essential monitoring and debugging capacities may prevent the late problem solution, therefore, slowing down the glitches and also jeopardizing in-system reliability. |
Apache Airflow: Provides a user-friendly web interface for real-time monitoring and logging, facilitating effective debugging of orchestrated workflows. Snowflake: Offers comprehensive monitoring tools and logs, allowing organizations to track and debug data processing workflows. DBT: Provides logging capabilities and a structured framework for debugging data transformation processes. Terraform: Supports logging and monitoring features, aiding in the identification and resolution of issues within the infrastructure. |
| Data Governance and Compliance |
Ensuring data governance and compliance with regulatory requirements is crucial, especially when orchestrating workflows involving sensitive or regulated data in the cloud for example: Payment Card Industry Data Security Standard (PCI DSS). |
Failure to meet data governance and compliance standards may result in legal consequences, fines, and reputational damage to organizations |
Apache Airflow: Allows organizations to enforce data governance policies through configurable workflows and access controls. Snowflake: Implements features for data governance, including data sharing controls, auditing, and compliance certifications. DBT: Supports data lineage tracking and documentation, enhancing data governance practices within orchestrated workflows. Terraform: Enables definition of infrastructure under compliance standards, contributing to overall governance. |
Table 1: Challenges of Data Orchestration in the Cloud
Through the collaborative use of Apache Airflow, Snowflake, Terraform, and DBT, organizations can comprehensively address common challenges in cloud-based data orchestration, ensuring the efficiency, security, and compliance of their data workflows. Not forgetting the base technology architecture, how does EKS/AWS integration with these technologies collectively address these challenges? These will be unraveled in the following sections.
Understanding Apache Airflow
Apache Airflow is an open-source platform designed for orchestrating complex workflows, particularly data workflows. The data workflow can be scheduled in batches depending on the volume and can be easily monitored with the Airflow web interface. It uses Directed Acyclic Graphs (DAGs) to represent workflows and relies on a modular and extensible architecture making some other functional components in the Apache Airflow architecture optional.
Apache Airflow Architecture
The whole operation is about single and multiple-node architecture. First, we aim to identify the most essential Apache components of the Airflow architecture.
- The Scheduler is the core subject that is responsible for the asynchronous execution of triggered tasks based on a defined schedule or external events. It provides discipline in the completion of activities at the exact hours and sequential order.
- The Executor is involved with carrying out the instructions defined in a DAG syntax. Airflow uses executors that can execute different types of jobs; for example,
LocalExecutor(for sequential job execution),CeleryExecutor(for distributed Celery-based job execution), and others. The choice of executor is the feature of the scheduler which chooses how tasks are parallelizable and distributed, It affects the configuration protocol of the scheduler. - The user interface of the Web Server is web-based and gives the possibility to control the DAGs and observe the processes via working with them. It enables the user to view all the DAGs that come with the task. It facilitates to take a closer look at the logs and execute the tasks manually. The Web Server will communicate with the Metadata Database to do some fetching of details about DAGs and tasks.
- This Metadata Database keeps an eye on DAG; the task’s metadata and its execution history. It is notable since it enables to management of the state of workflows, tracking of task status, and provision of abilities like task logging and bug retries. Apache Airflow is inclusive of widespread database ecosystems such as SQLite, MySQL, and PostgreSQL.
- A Worker constructs the assigned tasks from the scheduler and runs these tasks as a given responsibility in a distributed system. In a setup with various workers, tasks can be offered in parallel to these few workers for a faster outcome. The Worker communicates with the schedule making its call whether to get assigned a task based on its accessibility and order within the dependency list.
- A DAG processor (based on the need) interprets a DAG file into a metadata database and organizes it chronologically DAGs form pipelines driven by Airflow then on the last part DAG is simplified. DAG (Directed Acyclic Graph) is non-fundamental but it runs by default from the scheduler. DAG is run separately to achieve scalability and security purposes.
Operators delimit the solo activities under which conditional tasks are to be achieved. Every operator controls a particular action; e.g., a Python script is executed, some SQL query is fulfilled or an external systems interaction is performed. Airflow is scalable and provides a box set of operators as well as capable ones of creating custom operators based on their use cases.
Single Node Apache Airflow Architecture
In a single-node Apache Airflow architecture, all components of Airflow run on a single machine. This configuration is suitable for small-scale or development environments. The key components include the Webserver, Scheduler, Executor, Message Queue (Optional), and Metadata Database. The queue by default resides within the executor. In distributed setups, a message queue (e.g., RabbitMQ or Apache Kafka) might be introduced to facilitate communication between the scheduler and the workers.
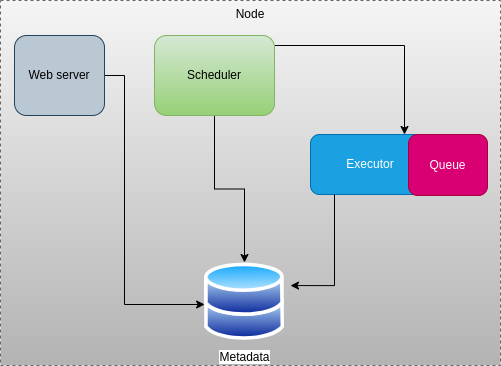
Figure 1: Single node Apache Airflow Architecture
Multiple Node Apache Airflow Architecture
In a multiple-node Apache Airflow architecture, components are distributed across different machines, providing scalability and resilience. This setup is suitable for production environments. The components are the Webserver, Scheduler, Workers, Executor, Message Queue (Optional), and Metadata Database.
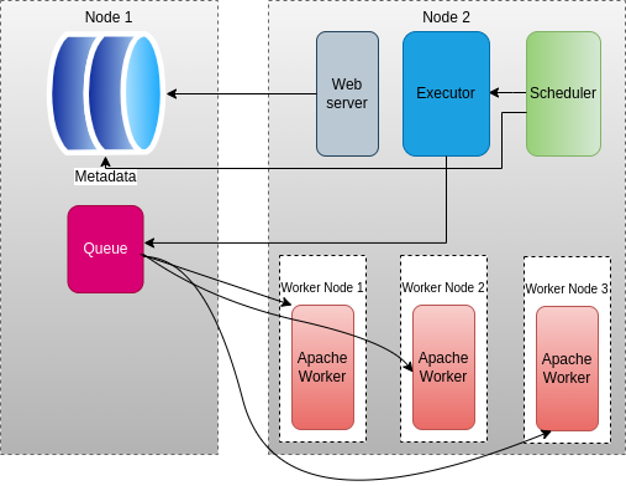
Figure 2: Multiple Nodes Apache Airflow Architecture
Apache Airflow was created with the ability to model and branch out more and more for various domains. The various domains are data engineering, machine learning, and other cloud ELT (Extract, Load, Transform) with these features. Cloud ELT takes the opposite perspective in that it begins by getting data from the source systems and putting it into the cloud storage or data lake first without transforming it instantly. This way of "Cloud Storage Load First" also makes good use of the scalability and flexibility that is provided by cloud storage. The potential in Apache Airflow’s architecture to add flexibility to users provides them with the necessary room to adjust the workflows they design according to their actual needs.
Understanding AWS EKS
AWS EKS (Elastic Kubernetes Service) is a fully managed Kubernetes service provided by Amazon Web Services (AWS). It simplifies the deployment, management, and scaling of containerized applications using Kubernetes on AWS infrastructure. Kubernetes is an open-source container orchestration platform that automates containerized applications' deployment, scaling, and management. In 2017 AWS announced the integration of Kubernetes with AWS. It is designed to make it easier to manage complex Kubernetes without writing longer vanilla Kubernetes codes to provision machines and deal with failures.
The salient facilities of AWS EKS are:
- Managed Kubernetes control plane: The AWS EKS relieves you from the job management and control plane maintenance of the Kubernetes control plane by taking care of the management and control plane maintenance of the cluster data store, API server, and so on.
- Scalability: EKS provides a way to achieve the scalability of instances through the inclusion or exclusion of node workers in a Kubernetes cluster. This is where scaling helps in dealing with varying workloads as well as blanket resource utilization.
- Integration with AWS Services: Through integration with countless AWS services, EKS becomes compatible with load balancer ELB, RDS DB, and S3 storage. Such integration removes the need for developers to employ or configure the underlying services and makes managing applications that utilize them easier.
- Security: To make AWS similar safety standards, EKS uses AWS security-related best practices, of which IAM (Identity Access Management) is one of them. It also offers VPC (Virtual Private Cloud) networking, consequently allowing you to maintain and protect your clusters from Kubernetes within AWS architecture.
- Compatibility and open standards: EKS has an API, and many tools provided by standard Kubernetes. This paradigm enables you to employ the familiar cloud-native workflows and management toolkit, which simplifies your work with AWS Fargate.
- High Availability: EKS, the control plane which, among other things, works to make sure nothing happens to the data that is in the racks, spreads the control plane among multiple Availability Zones. Consequently, this will prevent interruption of services due to happenstances, unavailability, and building the clusters which will be resilient to failures.
- Managed worker nodes: EKS lets you undertake the deployment of worker nodes without having to manage EC2 instances that are underling from your clusters manually. AWS gives you the choice of using AWS Fargate (web services to process serverless containers) or EC2 (managing instances directly).
- Container networking: EKS relies on the Amazon EC2 container network interface (CNI) for networking within a container environment, where EKS containers communicate with each other and also exploit the native features of Amazon VPC.
- Monitoring and logging: EKS weaves native compatibility with CloudWatch from AWS for monitoring and logging, allowing you to delve deeper into the Elasticsearch performance and health indicators of your Kubernetes clusters, thus giving you insights to improve upon them.
- Managed updates: EKS provides support for updating Kubernetes versions which allows your serverless applications and services to benefit from the latest version of Kubernetes.
AWS will make a change to the control plane at its end, and you will be able to use the other side to protect it. AWS EKS provides an advantage to organizations who are ready to orchestrate containers using the Kubernetes environment with the relief that the infrastructure and control plane components will be completely managed by the vendors. It makes it possible to scale and deploy apps with a secure package manager in a managed environment based on AWS.
Setting Up AWS EKS Cluster
The focus of this article is to configure Apache Airflow on AWS EKS (Elastic Kubernetes Service) in particular for data orchestration. This process involves several steps, but first, we will have to set up Elastic Kubernetes Service on AWS. Below is a high-level guide to help you get started. You may need to adapt these steps based on your specific requirements and environment. Some prerequisites must be satisfied to set up Apache Airflow on AWS EKS. It is very important to have an AWS Account registered and ensure you have the necessary permissions to create and manage EKS clusters, EC2 instances, IAM roles, and other resources on it. Indeed, we have to execute many commands here.
Step 1: Installing Necessary Tools
Sign in to AWS Management Console. This step involves entering your IAM user information to access the AWS Console and opening up the AWS Cloudshell as seen in the screenshot below.
Figure 3: Screenshot of AWS Console home
Here we have the Cloudshell command line interface.
Figure 4: Screenshot of AWS Cloudshell command line Interface
It’s very important to understand that Python must be properly installed in the production environment to achieve a perfect installation. Certainly, this is provisioned by the AWS console but an upgrade might be required, all you need to do is type the following command to check and update the environment.
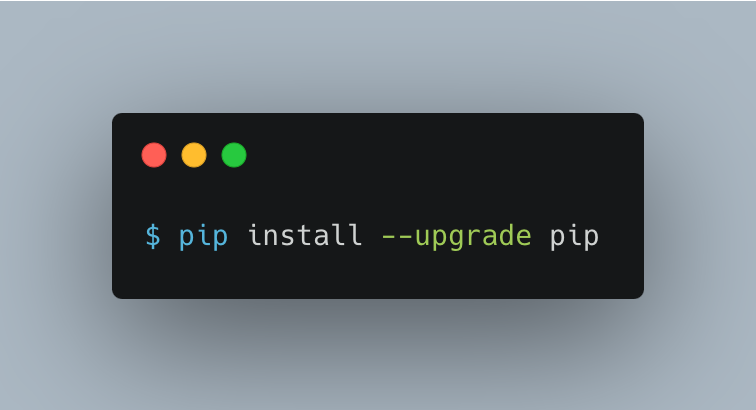
Next, we create a Python virtual environment to avoid having conflict dependencies between other installations in that environment and the already installed Python dependencies that we have on the system.
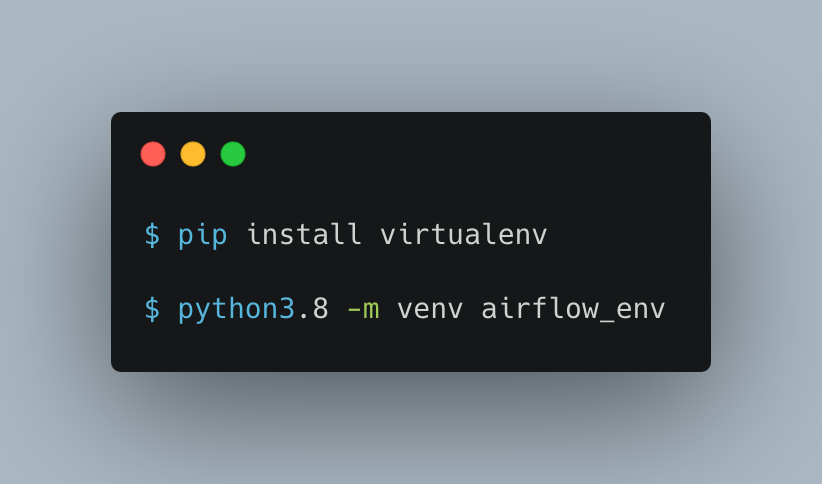
Replace 3.8 with the version on your system.
You will observe that the virtual environment now precedes the username on the console airflow_env.
It indicates that we have successfully configured the virtual environment.
kubectl
The first tool to install here is kubectl from the console. It is a command line tool that you use to communicate with the Kubernetes API server. You can follow the installation from the kubectl GitHub repository.
Check if kubctl is installed on your machine with the following command.
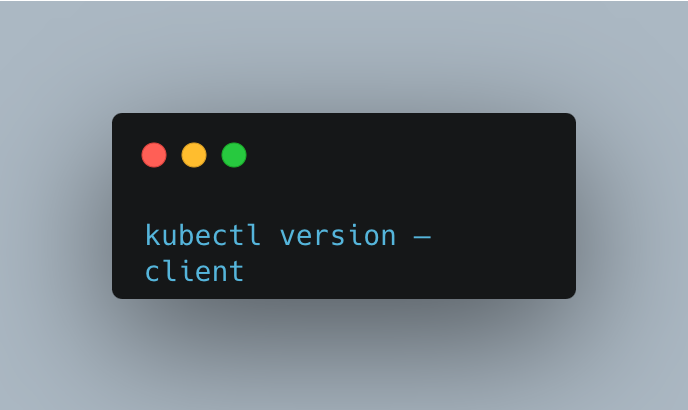
If you have kubectl installed in the path of your device, the output will be similar to the following.
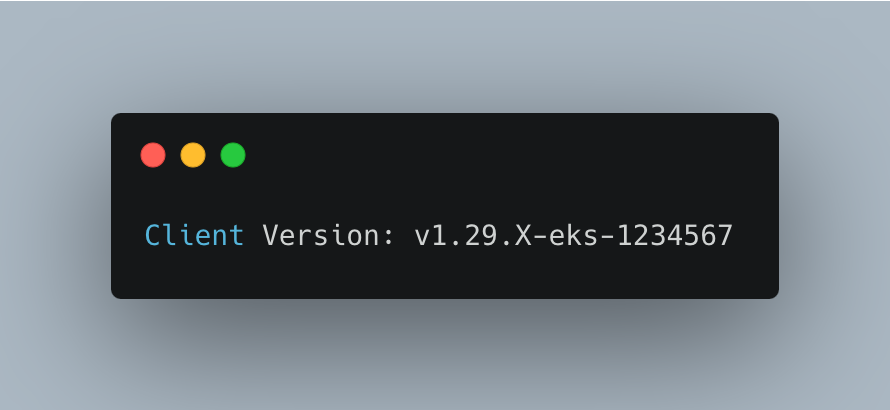
If you receive no output, then you either don't have kubectl installed, or it's not installed in a location that's in your device's path. Follow the steps to download and install the binaries.

To download a specific version, replace the $(curl -L -s https://dl.k8s.io/release/stable.txt) portion of the command with the specific version. For example, to download version 1.29.1 on Linux x86-64, type:
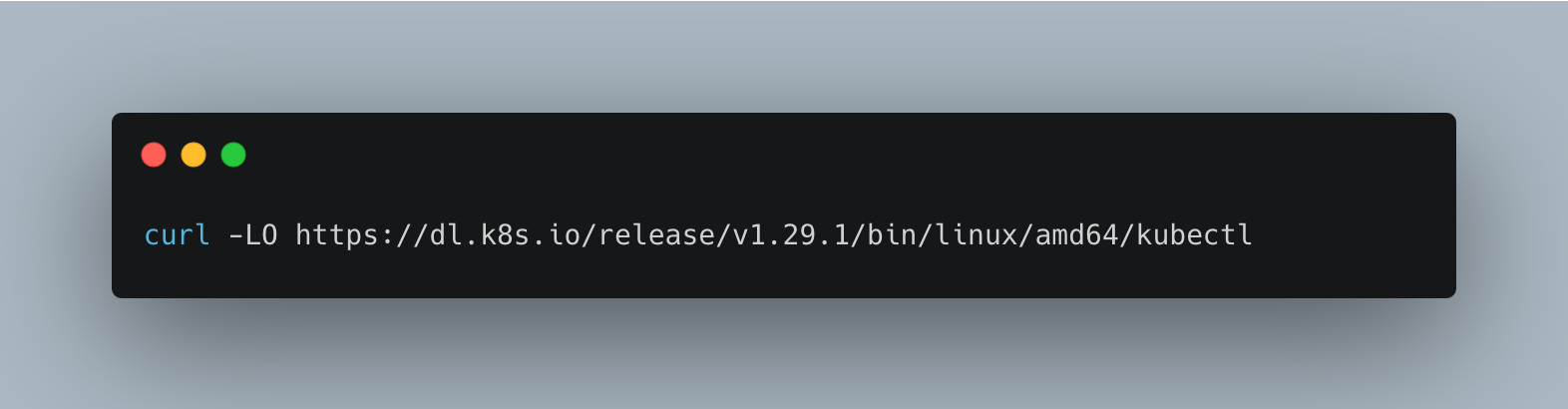
Validating the binary is optional. To do this, download the kubectl checksum file with the command below.

Validate the kubectl binary against the checksum file by tying or pasting this command.
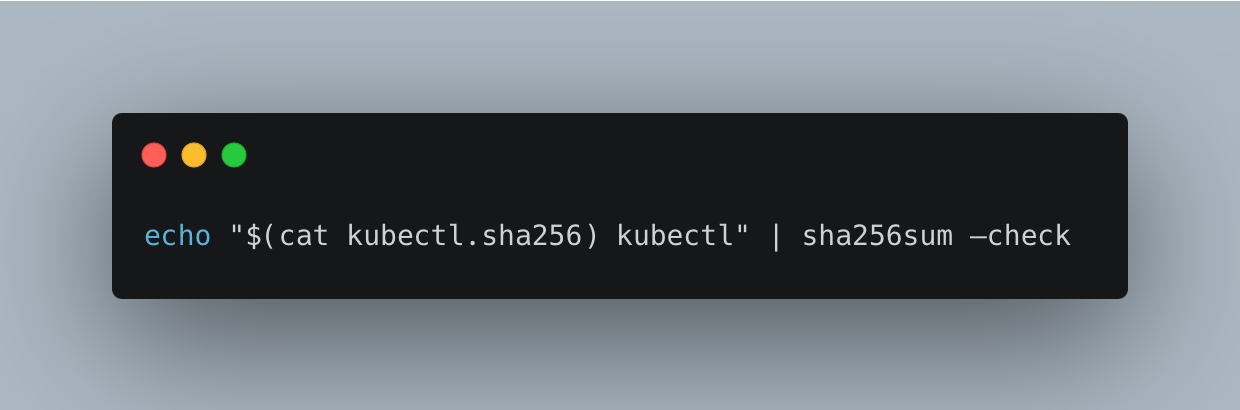
After using this command, ensure you receive the following output below.
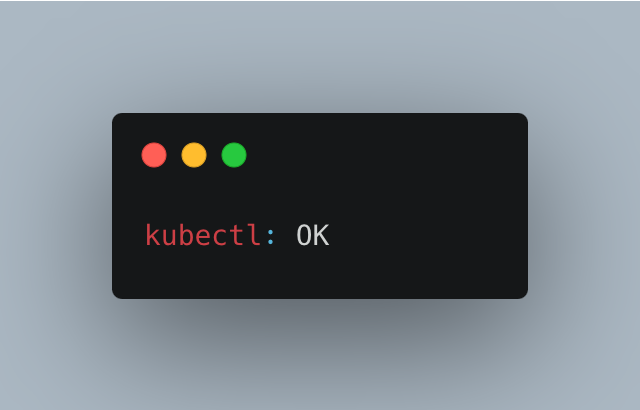
Now, install kubectl utilities with the following command with permission 0755:
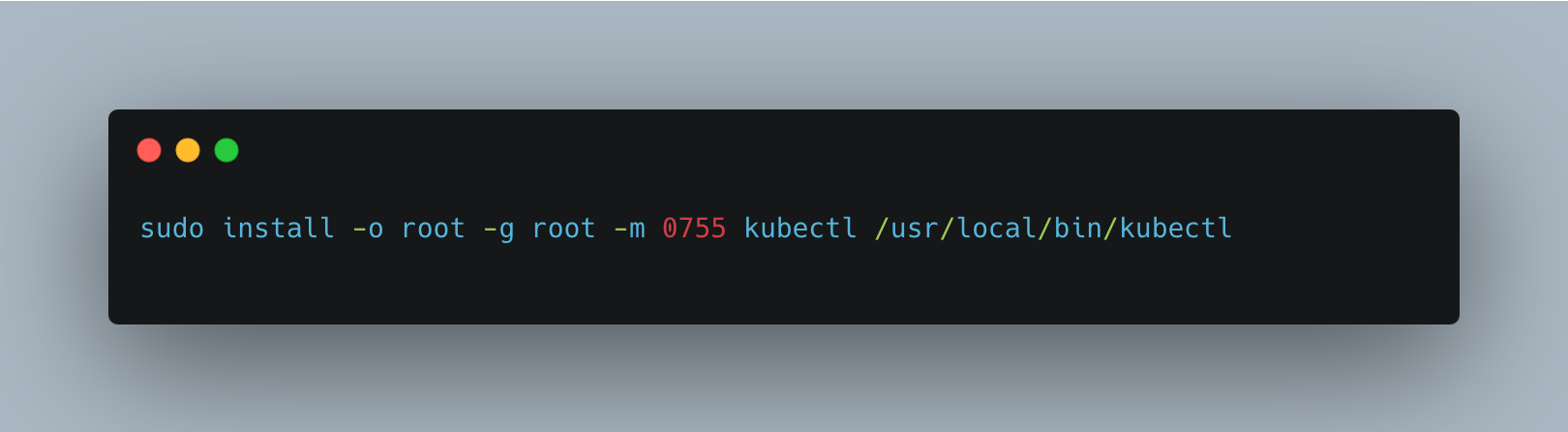
Once Kubectl is completed, you need to install the [eksctl] command line tool. Download and extract the latest release of eksctl with the following command.

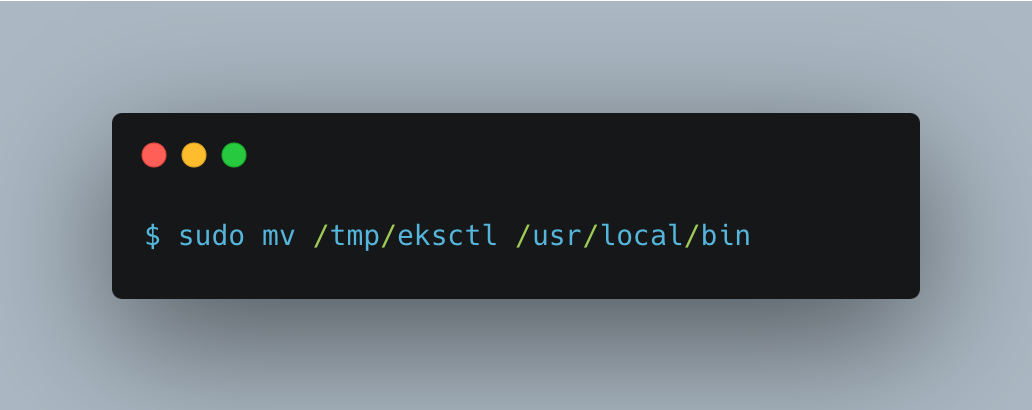
Test that your installation was successful with the following command.
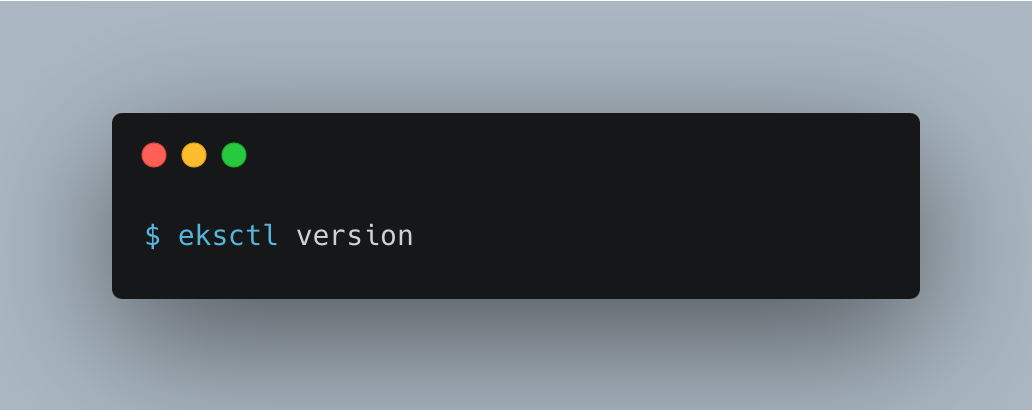
Running the above script correctly, you should have the output below.

Figure 5: Output response of eksctl installation
Helm
The next tool to install is Helm. Helm helps you to install and manage applications on Kubernetes. Without Helm, it can be a nightmare to manage applications on the Kubernetes cluster. Install helm3 with the command below.
Then check the installation and version with the following command.

So with just one command you can install and run any application on your Kubernetes cluster. Let’s add the repo with the command below.
Step 2: Creating the Amazon EKS Cluster With eksctl
Here we are going to create the cluster with a config file. Create a file called “cluster.yaml” with the following content parameters. We have included some add-on policies as well: AWS EBS (Elastic Block Store), and fs ingress - the use will be explained later in this section.
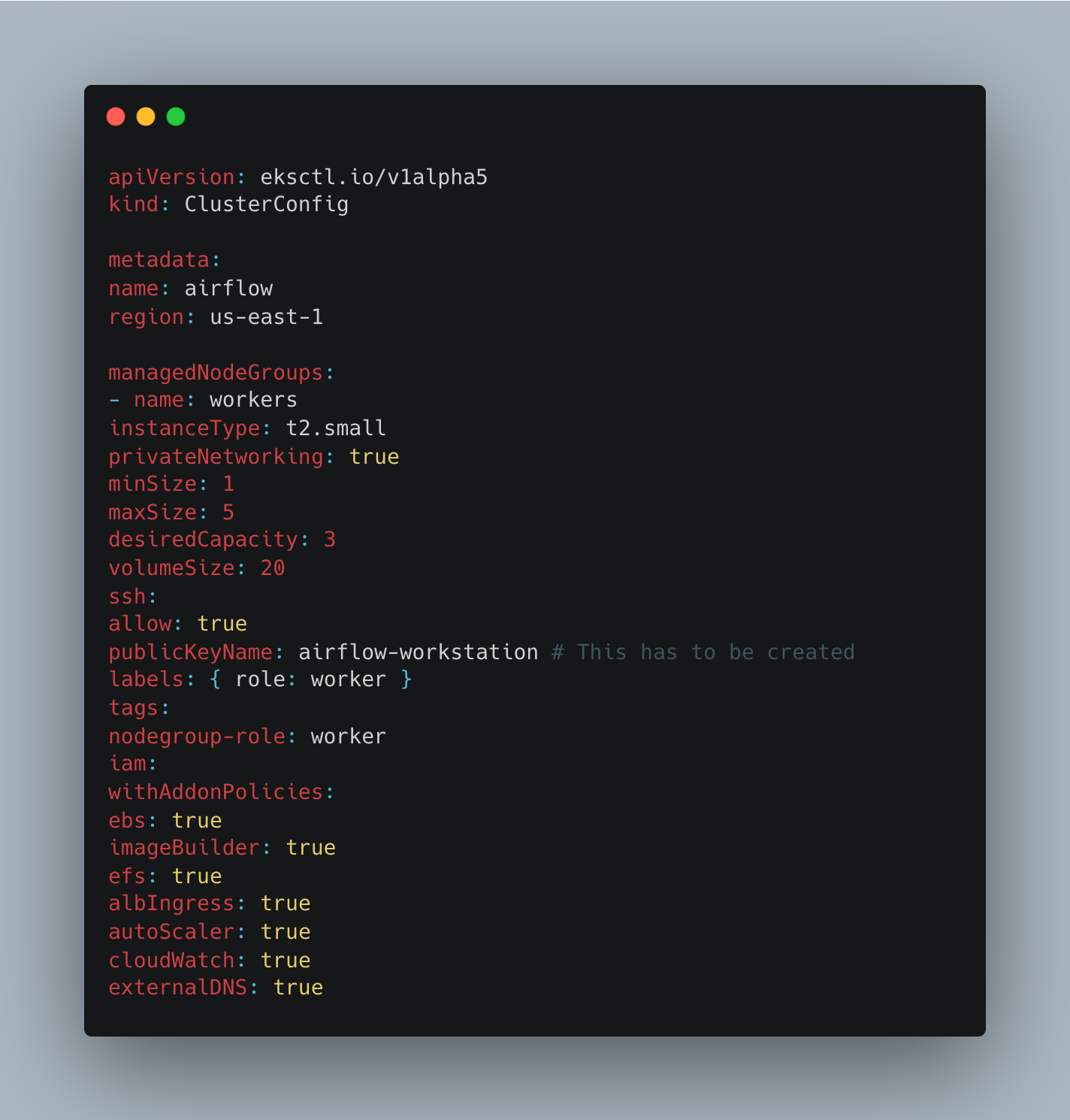
Before running the command, make sure you do the following replacements listed below.
- Replace
us-east-1with the AWS Region that you want to create your cluster in. - Replace the Metadata name: “
airflow” with a name for your cluster.
Here we have 3 nodes and a maximum of 5. You can add your public and private subnets by adding the following to the cluster file.
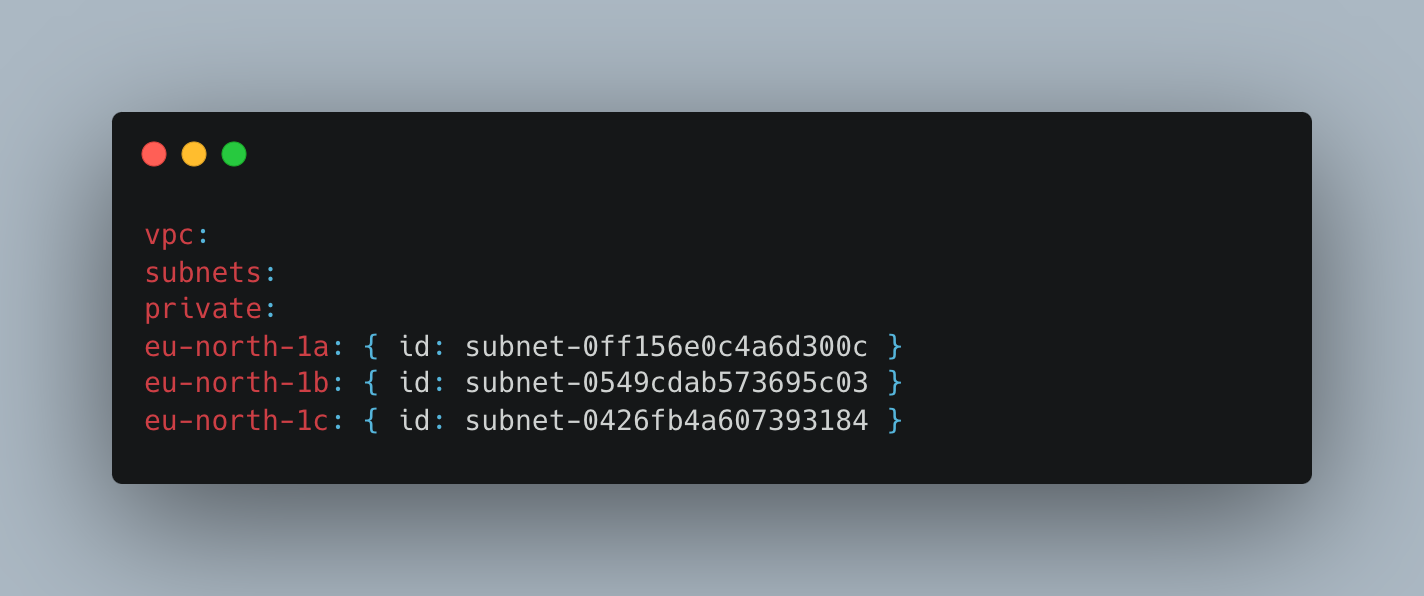
This is followed by your private-subnet-IDs. We will include no version of document clusters here. It will be done through the command automatically which will not include old file versions. If you are configuring virtual networks, then the CIDR subnets that you choose must conform with the generic Amazon EKS subnet guidelines.
This piece of content advises to know about any Amazon EKS VPC and subnet requirements and reminders. You do have to think about the network anticipation when creating an architecture on AWS. Therefore, the reason we run those commands with particular ones aimed at clustering is that we wanted to create an efficient infrastructure. AWS has data centers that are dispersed and located around the world in different separated physical locations a part of which Amazon has.
The virtual private cloud, or VPC, is a network container that does not have any communication with other networks. Resources inside the VPC can reach others, but not resources in other VPCs unless you authorize such interaction respectively. VPC can be extended over multiple availability zones within a single region, which allows you to create VPC for all sources of availability zones.
Next, one has to learn about how SSH Key works to augment the existing knowledge.
To make an SSH key pair, type the command sssh-keygen into the terminal.

Press enter by following the instructions. Then call out the key pair with the following command and save it to your GitHub SSH pair settings.
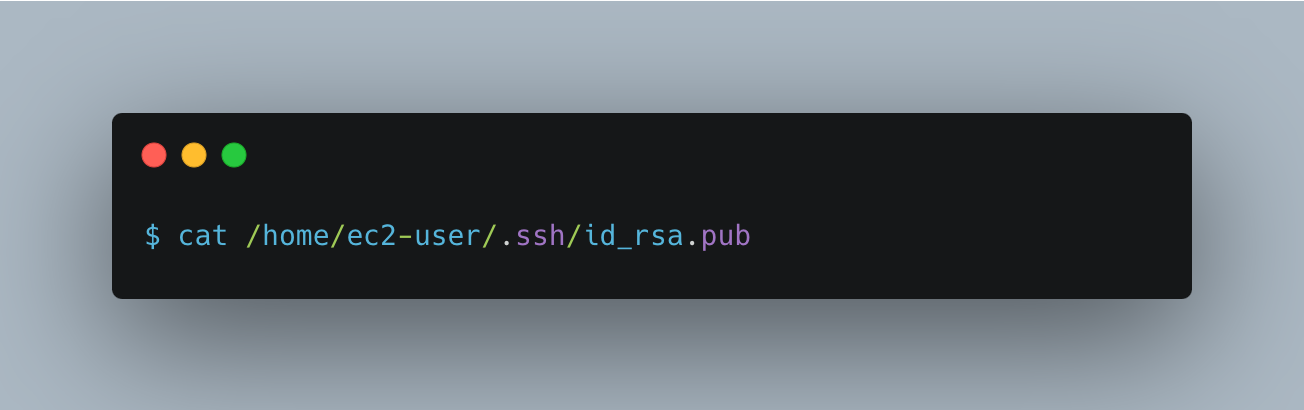
Import this key in your EC2 cloud environment with this command:
Add the key name to the following section of the “cluster.yaml” file.
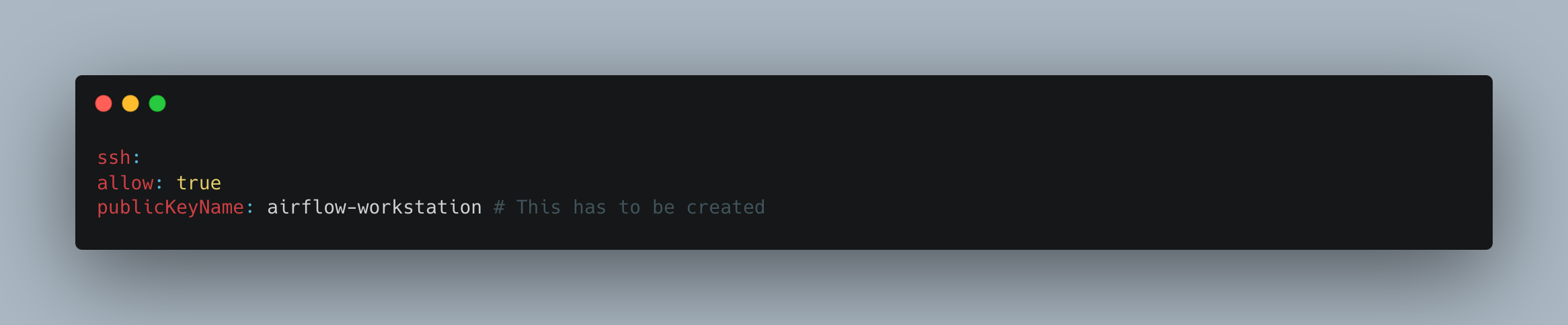
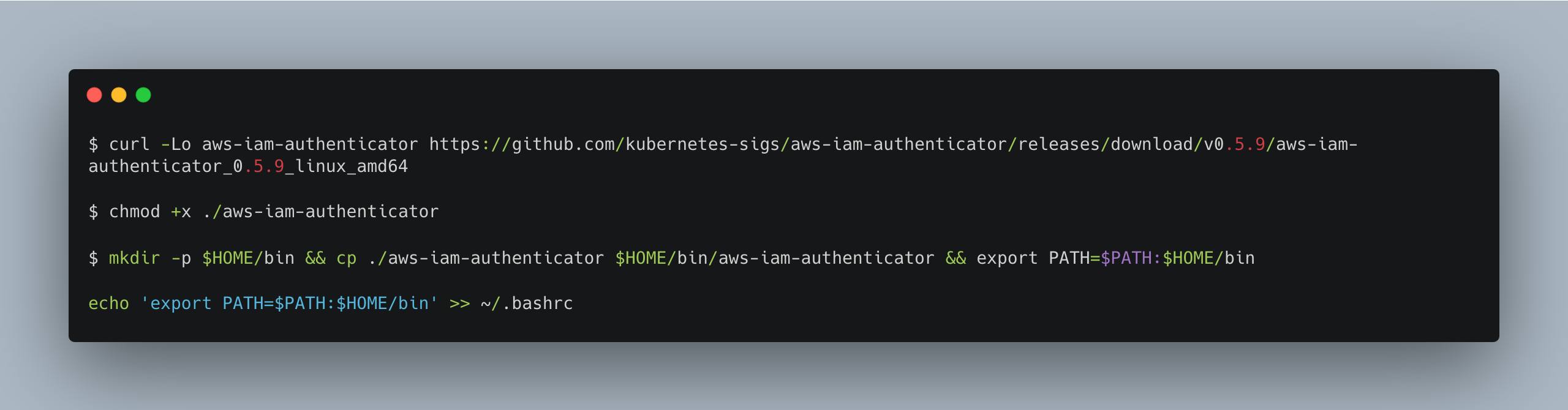
One more thing to consider is the IAM Authenticator. It is designed to authenticate users against a Kubernetes cluster using IAM credentials. This means that IAM users or roles are used to grant access to the Kubernetes cluster. It also generates temporary authentication tokens based on IAM credentials. These tokens are then used by kubectl to authenticate requests to the Kubernetes API server.
You can set up IAM Authentication one step at a time as follows:
 Time to spin the EKS Cluster. Make sure you are in the directory where you have the “
cluster.yaml” file and run the following command.
Time to spin the EKS Cluster. Make sure you are in the directory where you have the “
cluster.yaml” file and run the following command.
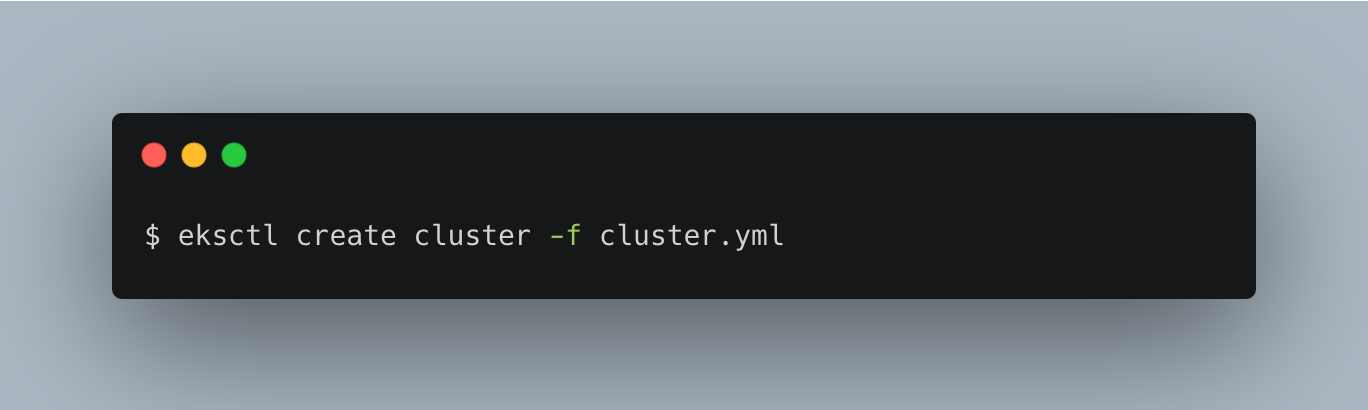
Figure 6 below shows the screenshot of the terminal while running the ekctl command to create the cluster.
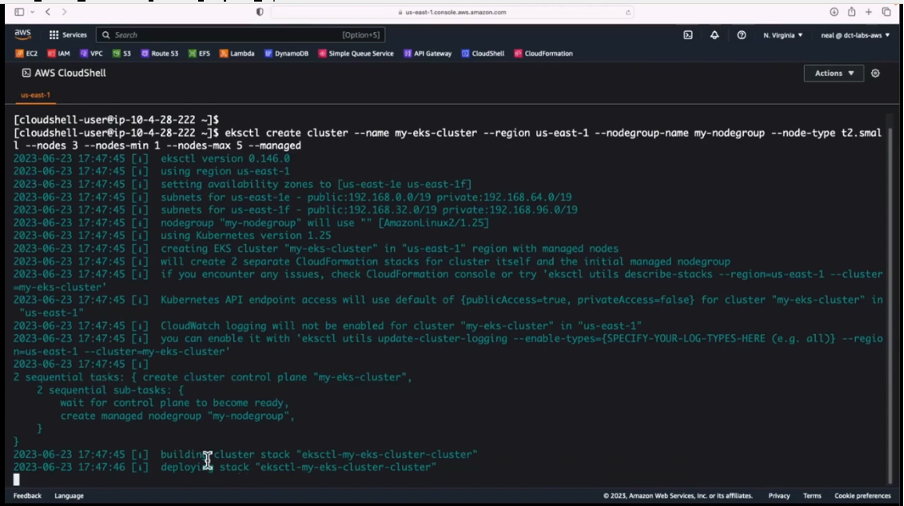
Figure 6: Executing the EKS Cluster command
Executing the eksctl cluster command successfully should have the EKS Cluster created. Log on to the “cloud formation” interface of the AWS you should have the cluster created as shown below.
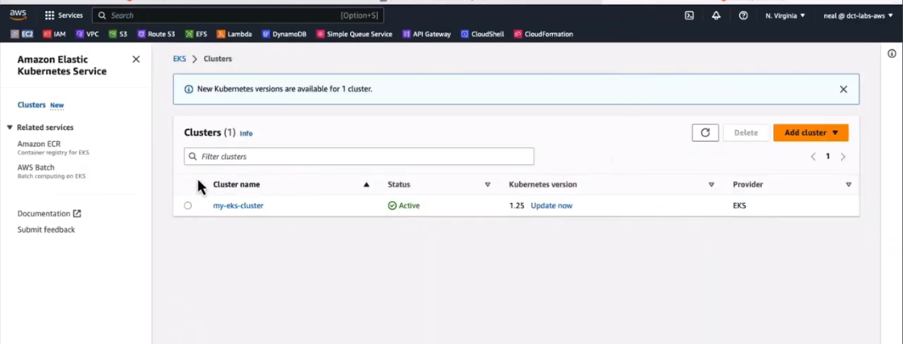 Figure 7: Ready state of EKS Cluster
Figure 7: Ready state of EKS Cluster
Conclusion
In conclusion, the combination of Apache Airflow along AWS EKS (Elastic Kubernetes Service) enables a high-end answer for automating complicated data workflow in the cloud in general. The combination of Apache Airflow with AWS EKS allows organizations to facilitate the introduction of containerized apps into production, managing them at scale, while the workflows of data are being monitored. Through AWS EKS, a fully-managed Kubernetes environment is provided, which gives features such as management of control plane, scalability, integration with AWS services, security measures, compatibility with open standards, highly-available clusters, managed worker nodes, container network, monitoring, logging and managed updates.
Organizations can address their business objectives by building and deploying the necessary applications because the infrastructure management problem is taken care of. Conversely, Apache Airflow can help in creating and scheduling complex data workflows as well as ensure that those data workflows are running smoothly, and efficiently. It is designed in a modular and expandable way, which uses DAGs to direct and keep the data pipeline efficient. It helps to perform tasks such as data ingesting, transforming, and (re)loading easily.
Apache Airflow in conjunction with AWS EKS solves issues in the cloud-based data orchestration such as scalability problems, variety of data integration scenarios, security aspects, orchestration of multi-stack systems, resource management, cost optimization, workflow monitoring and debugging, as well as governance and compliance. All it takes to do this is setting up the AWS EKS cluster and ensuring that the needed tools like Helm and Kubectl are installed. This is in addition to creating a robust and scalable Kubernetes environment to be used for the Apache Airflow deployment for efficient data orchestration.
Such integration offers an avenue for companies to access the potential of cloud computing for data management, consequently driving production and leading to increased operational efficiency and business decision-making.
References
[1] A. Cepuc, R. Botez, O. Craciun, I. -A. Ivanciu and V. Dobrota, "Implementation of a Continuous Integration and Deployment Pipeline for Containerized Applications in Amazon Web Services Using Jenkins, Ansible, and Kubernetes," 2020 19th RoEduNet Conference: Networking in Education and Research (RoEduNet), Bucharest, Romania, 2020, pp. 1-6, doi: 10.1109/RoEduNet51892.2020.9324857.
[2] Finnigan, L., & Toner, E. “Building and Maintaining Metadata Aggregation Workflows Using Apache Airflow” Temple University Libraries Code4Lib, 52. (2021).
[3] K. Allam, M. Ankam, and M. Nalmala, “Cloud Data Warehousing: How Snowflake Is Transforming Big Data Management”, International Journal of Computer Engineering and Technology (IJCET), Vol.14, Issue 3, 2023.
[4] DBT Lab In, “Best practices for workflows | dbt Developer Hub” Accessed: 2024-02-15 12:25:55
[5] Amazon Web Services, “What Is Amazon Managed Workflows for Apache Airflow? - Amazon Managed Workflows for Apache Airflow” Accessed: 2024-02-15 01:08:48 [online]
[6] The Apache Software Foundation, “What is Airflow™? — Airflow Documentation” Accessed: 2024-02-15 01:10:52 [online]
[7] Baskaran Sriram, “Concepts behind pipeline automation with Airflow and go through the code.” Accessed: 2024-02-15 [online].
[8] Medium, “Airflow 101: Start automating your batch workflows with ease” Accessed: 2024-02-15 [online].
[9] Astronomer, “Install the Astro CLI | Astronomer Documentation” Accessed: 2024-02-15 12:12:28 [online]
[10] Amazon Web Services, “Creating an Amazon EKS cluster - Amazon EKS” Accessed: 2024-02-15 12:25:17 [online]
[11] “Create a Snowflake Connection in Airflow | Astronomer Documentation” Accessed:2024-02-15 01:07:15 [online]
[12] “Airflow Snowflake Integration Guide — Restack” Accessed:2024-02-15 [online]
[13] Dhiraj Patra “Data Pipeline with Apache Airflow and AWS | LinkedIn” Accessed: 2024-02-15 01:09:37 [online]
