Mastering System Design: A Comprehensive Guide to System Scaling for Millions (Part 1)

Take a transformative journey into the realm of system design with our tutorial, tailored for software engineers aspiring to architect solutions that seamlessly scale to serve millions of users. In this exploration, we use the fictitious MarsExpress, a local delivery startup in Albuquerque, as a model to illustrate the evolution from a community service to a global force.
MarsExpress, our focal point, currently operates on an aging monolithic system — a legacy structure that once served its purpose locally but now yearns for a comprehensive overhaul. Join us as we unravel the intricacies of system design, not merely for theoretical understanding but as a hands-on approach to rejuvenating a legacy system into a globally scalable software solution.
This tutorial transcends conventional coding tutorials, shifting the focus towards the strategic decisions and methodologies that propel a software solution from a local operation to a worldwide phenomenon. Forget geographical limitations and delve into the world of strategic architectural choices that dictate scalability.
MarsExpress, with its legacy monolith, serves as our canvas, unraveling the intricacies of system design without delving into code specifics. Instead, we provide software engineers with the tools to engineer solutions that scale effortlessly and globally.
Join us on this odyssey, where MarsExpress becomes a model for the transformation from localized operations to a globally impactful service. This tutorial is an open invitation for software engineers keen on mastering system design — an essential skill set for crafting software solutions that cater to millions.
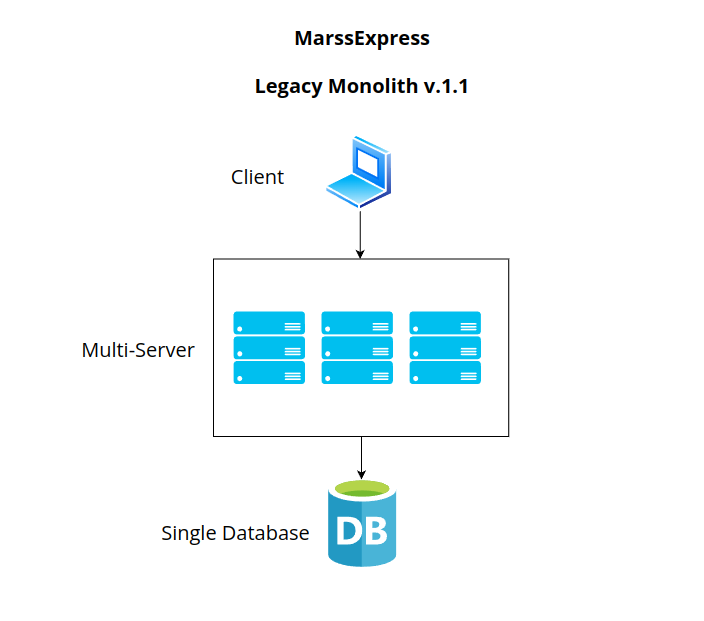
Legacy Monolithic
MarsExpress currently operates on a traditional monolithic architecture, often referred to as the “legacy system.” In this setup, the server is openly accessible via the Internet, offering a RESTful API to manage essential business logic. This API serves as the bridge for communication between mobile and web client applications and the server, enabling the exchange of data and commands.
One notable aspect of the current system is its responsibility for delivering static content, such as images and application bundles. These elements are stored directly on the local disk of the server, contributing to the overall functionality and user experience.
Additionally, the application server is closely linked to the database, which is housed on the same server. This connection facilitates the seamless interaction between the application’s logic and the data it relies on, creating a centralized environment for information storage and retrieval.

Scaling Vertically
In our quest to transform MarsExpress into a global powerhouse, the first step involves scaling vertically to bolster its capacity and handle a substantial increase in user demand. Scaling vertically, often referred to as “scaling up,” focuses on enhancing the capabilities of the existing server and infrastructure to manage a higher load of users.
As the server grapples with an increasing user load, a short-term remedy involves upgrading to a larger server equipped with enhanced CPU, memory, and disk space. However, it’s important to note that this serves as a temporary solution, and over time, even the most robust server will encounter its capacity constraints.
Also, the lack of redundancy in a single-server architecture makes the system vulnerable to failures. In the event of hardware issues or routine maintenance, downtime becomes an unavoidable consequence, rendering the entire system temporarily inaccessible.
Performance bottlenecks also emerge as a noteworthy issue. With a burgeoning user base and expanding data volume, a single server can become a significant performance bottleneck. This bottleneck manifests as slower response times, adversely affecting the overall user experience.
Geographic limitations pose another challenge. A single server, typically located in a specific geographic region, can result in latency for users situated in distant locations. This constraint becomes increasingly pronounced when aspiring to cater to a global user base.
The concentration of data on a single server also raises concerns about data loss. In the unfortunate event of a catastrophic failure or unexpected circumstances, the risk of losing significant data becomes a stark reality.
Additionally, the maintenance and upgrade processes on a single server can be cumbersome. Implementing updates or performing maintenance tasks often requires system downtime, impacting users’ access to services and making the overall system management less flexible.
In light of these drawbacks, it becomes imperative to explore more robust and scalable system design approaches, especially when aiming to create a production environment capable of handling millions of users while ensuring reliability and optimal performance.
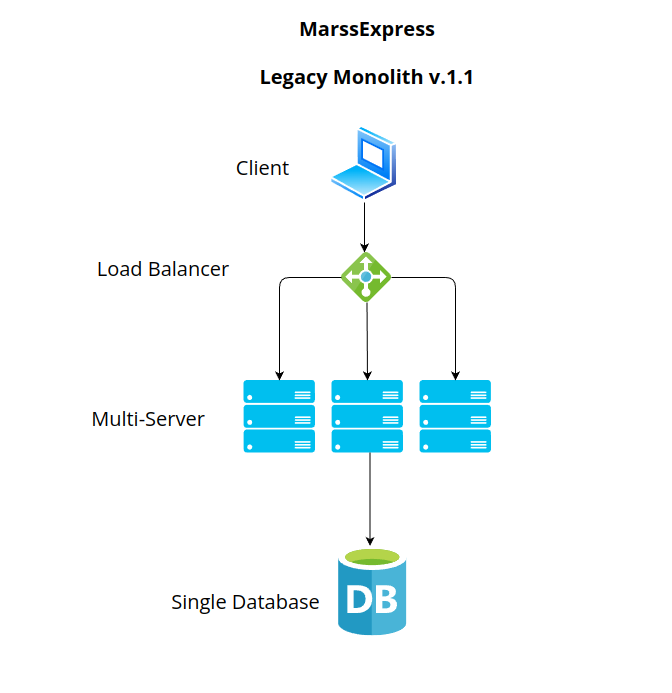
Scaling Horizontally
In a single-server architecture, horizontal scaling emerges as a strategic solution to accommodate increasing demands and ensure the system’s ability to handle a burgeoning user base.
Horizontal scaling involves adding more servers to the system and distributing the workload across multiple machines. Unlike vertical scaling, which involves enhancing the capabilities of a single server, horizontal scaling focuses on expanding the server infrastructure horizontally.
One of the key advantages of horizontal scaling is its potential to improve system performance and responsiveness. By distributing the workload across multiple servers, the overall processing capacity increases, alleviating performance bottlenecks and enhancing the user experience.
Moreover, horizontal scaling offers improved fault tolerance and reliability. The redundancy introduced by multiple servers reduces the risk of a single point of failure. In the event of hardware issues or maintenance requirements, traffic can be seamlessly redirected to other available servers, minimizing downtime and ensuring continuous service availability.
Scalability becomes more flexible with horizontal scaling. As user traffic fluctuates, additional servers can be provisioned or scaled down dynamically to match the demand. This elasticity ensures efficient resource utilization and cost-effectiveness, as resources are allocated based on real-time requirements.
Load Balancer
In the realm of horizontal scaling, a load balancer becomes our strategic ally. It acts as a guardian at the gateway, diligently directing incoming requests to the array of servers in our cluster. Here’s how it seamlessly integrates into our horizontally scaled architecture. A load balancer ensures that incoming requests are evenly distributed across all available servers. This prevents any single server from bearing the brunt of heavy traffic, promoting optimal resource utilization. the effectiveness of a load balancer often depends on the strategy and algorithm it uses to distribute incoming requests among servers.
In load-balancing strategies, algorithms are categorized into two primary types: static and dynamic. These classifications represent distinct approaches to distributing incoming network traffic across multiple servers. Each type serves specific purposes and is tailored to meet particular requirements in system design.
Static load balancing algorithms, in contrast, follow predetermined patterns for distributing incoming requests among available servers. While they offer simplicity and ease of implementation, like:
- Round Robin: Round Robin is a static load balancing algorithm that distributes incoming requests in a circular order among available servers. This method is straightforward, ensuring an even distribution of traffic without considering the current load or capacity of each server. It is well-suited for environments with relatively uniform servers and stable workloads.
- Weighted Round Robin: Weighted Round Robin is a static load balancing approach similar to Round Robin but introduces the concept of assigning weights to each server based on its capacity or performance. This static method allows administrators to predetermine the load distribution, considering variations in server capacities.
- IP Hash: IP Hash is a static load-balancing algorithm that utilizes a hash function based on the client’s IP address to determine the server for each request. This ensures session persistence, directing requests from the same client to the same server. While effective for maintaining stateful connections, it may lead to uneven distribution if the IP hashing isn’t well-distributed.
- Randomized: The Randomized load balancing algorithm introduces an element of unpredictability by randomly selecting a server for each request. This static method can be advantageous in scenarios where a uniform distribution of requests is not critical, adding an element of randomness to the load distribution.
Dynamic load balancing algorithms adapt in real time to the changing conditions of a system. These algorithms continuously assess server health, current loads, and response times, adjusting the distribution of incoming requests accordingly. Like:
- Least Connections: Dynamic in nature, the Least Connections algorithm routes incoming traffic to the server with the fewest active connections. This dynamic approach adapts to real-time connection loads on servers, efficiently distributing requests and optimizing resource usage based on the current server states.
- Least Response Time: The Least Response Time algorithm dynamically directs traffic to the server with the fastest response time. It optimizes server performance and responsiveness, ensuring that users are consistently directed to the server with the lowest latency.
- Least Resource Utilization: Dynamic in its behavior, the Least Resource Utilization algorithm routes traffic to the server with the lowest resource utilization, considering factors such as CPU and memory usage. This dynamic approach responds to changes in server resource usage, optimizing for efficiency.
- Adaptive Load Balancing: Adaptive Load Balancing dynamically adjusts the distribution algorithm based on real-time server health and load conditions. This dynamic approach continuously adapts to changing circumstances, offering optimal performance by responding to fluctuations in server states.
The dynamic load balancing algorithm I would recommend for “MarsExpress,” as it scales globally, is the Least Connections algorithm. This algorithm is particularly advantageous because it considers the current state of the network when making routing decisions and assigning new requests to the server with the fewest active connections.
One of the primary benefits of the Least Connections method is its ability to adapt to traffic variations. As the system expands, it is likely to experience unpredictable spikes in usage. The algorithm can manage these fluctuations by distributing incoming requests to servers with lighter loads, thus preventing any single server from being overwhelmed.
This algorithm also supports session persistence, which is critical for a delivery system that requires transaction consistency. Modified to consider session affinity, the Least Connections method ensures that requests from a specific user during a session are consistently directed to the same server, maintaining a continuous user experience.
Data Replication
Data replication is a fundamental aspect of large-scale distributed systems, playing a critical role in enhancing their efficiency, reliability, and availability. In such systems, data replication involves creating multiple copies of data and distributing them across different servers or locations. This strategy is vital for ensuring high availability; if one node fails or becomes inaccessible, users can still access data from another node, minimizing downtime and service disruptions.
Additionally, replication aids in load balancing by allowing requests to be distributed across multiple nodes, thereby reducing the load on any single server and improving overall system performance. It also enhances data access speed, as users can access data from the nearest or least busy replica, significantly reducing latency. While data replication is prominently recognized for its role in distributed databases, it is important to note that its utility extends beyond traditional data storage systems. Replication can be equally vital in caching layers, such as those implemented using cache servers like Redis.
Selecting the appropriate replication strategy for a system can be a complex decision, as various strategies offer distinct advantages and challenges. The suitability of a replication strategy largely depends on the specific needs and contexts of the use case at hand. Some strategies may excel in certain scenarios, while others might be more effective under different circumstances. three main replication strategies are:
- Leader-Follower (also known as Master-Slave) Replication: In the Leader-Follower replication strategy, one node (the leader or master) handles all write operations, and several other nodes (followers or slaves) replicate these changes. The leader node receives all update requests, processes them, and then propagates the changes to its followers. This method ensures consistency and simplifies conflict resolution, as there is a single authoritative source for data updates.
- Multi-Leader Replication: Multi-Leader replication allows multiple nodes to act as leaders, each capable of handling write operations. These leaders then synchronize their data with each other. This approach is beneficial in distributed systems where nodes are geographically dispersed, as it allows writes to occur closer to where the data is being used, reducing latency.
- Leaderless Replication: In the Leaderless replication model, all nodes are treated equally and can handle both read and write operations. When a write occurs, it is usually written to multiple nodes to ensure redundancy. Reads may require responses from multiple nodes to ensure the data is up-to-date, based on a quorum-like system. This model offers high availability and fault tolerance, as there is no single point of failure, and operations can continue even if some nodes are down.
Also, conflict resolution is a critical aspect of database replication to ensure data consistency and integrity. Various conflict resolution strategies can be employed, including:
- Last Write Wins (LWW): This strategy resolves conflicts by accepting the last write operation as the correct version, potentially discarding earlier conflicting changes.
- Timestamp-Based Resolution: Conflicts are resolved based on timestamps associated with write operations, with the latest timestamp taking precedence.
- Manual Resolution: In some cases, conflicts require manual intervention by administrators or users to determine the correct version of the data.
- Conflict Avoidance: Designing data models and application logic to minimize the likelihood of conflicts through techniques like logical clocks and unique identifiers.
Consistency Matters
Consistency in distributed systems is crucial as it ensures that all users and processes have a uniform view of data at any given time. This is vital for maintaining data integrity and preventing conflicts or errors that can arise from disparate data states. In scenarios like financial transactions, inventory management, or any system where data accuracy is paramount, consistency ensures reliable and predictable interactions. Without consistency, systems can produce incorrect results, leading to potential data loss, erroneous decisions, or system failures. In summary, consistency is key to the reliable and accurate operation of distributed systems.
Eventual consistency is a model used in distributed systems, where it’s accepted that all copies of data across nodes may not be immediately consistent following a change but will become consistent after a period. This approach allows for high system availability and performance, especially in environments with network latency and partitioning issues. Eventual consistency is well-suited for applications where immediate data consistency is not critical, and slight delays in data synchronization can be tolerated. This model is often used in large-scale, distributed databases and applications like social networks, where scalability and availability are prioritized over strict consistency.
The linearizability consistency model in distributed systems ensures that operations appear to occur instantaneously and sequentially, even if they are executed concurrently. This model provides a high level of data integrity and consistency, making it ideal for systems where precise coordination of operations is critical. Linearizability is akin to having a single, global clock dictating the order of all operations, thus simplifying the understanding and predictability of system behavior. It’s most beneficial in scenarios requiring strict consistency, like financial transactions or critical data updates, where the exact ordering of operations is vital.
The sequential consistency model in distributed systems is a consistency level where the result of execution of operations (like read and write) is as if the operations were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program. It ensures system-wide ordering of operations, making it simpler to understand than more relaxed consistency models. This model is useful for applications where the order of operations needs to reflect the program order, but it does not require operations to be instantaneous like Linearizability. For example, consider an online marketplace with a shared inventory system. When multiple sellers update their inventory concurrently, the sequential consistency model ensures that these updates are reflected across the system in the order they were made.
The causal consistency model in distributed systems ensures that operations that are causally related maintain a specific order across all nodes, while operations that are unrelated can be seen in any order. This model is crucial in scenarios like social media platforms, where user actions such as posting a message and commenting on that message are causally linked. The causal consistency ensures that if a user sees comments only after the original message is visible.
In such a system, if one user comments on another user’s post, the comment will not appear to others until the original post is also visible, maintaining a logical and understandable sequence of events. This consistency model is ideal for applications where the context and sequence of interactions are important for user experience and data integrity.
Stronger consistency models impose order constraints that limit the utility of asynchronous replication, while weaker models offer more flexibility at the risk of stale data. This understanding is crucial for selecting the right replication approach. The trade-off with asynchronous replication’s flexibility is the potential lag between leader and follower nodes, which can introduce several consistency challenges that need careful consideration.
Consistency in distributed systems can be fraught with challenges. One of them is read-your-own-write inconsistency. It is a phenomenon encountered in distributed systems where data written or updated by a user is not instantly visible to that same user upon subsequent reads. In other words, when a user makes a change to their data, such as updating their profile information or posting a message, they expect to immediately see the updated data when they access it again. However, in distributed systems, there can be delays in propagating these changes across all nodes or replicas, leading to a situation where the user’s own updates are not immediately reflected in their own subsequent read requests.
This inconsistency can result from factors like replication lag, network delays, or the inherent complexities of maintaining real-time data synchronization across distributed nodes. It’s a challenge in systems where maintaining immediate consistency can be difficult due to the need to balance performance, availability, and data accuracy. To address this issue, distributed systems often employ various synchronization mechanisms and strategies to minimize the delay and provide users with a more coherent and real-time experience. it becomes evident that discussing inconsistency and consistency requires dedicated articles that explore their nuances, challenges, and solutions.
Conclusion
In this initial segment of our series, we’ve embarked on MarsExpress’s journey, transforming its legacy monolithic architecture into a scalable structure ready for global challenges. We’ve explored the fundamentals of vertical and horizontal scaling, along with load balancing and data replication, setting the stage for more complex scalability solutions.
As we look ahead, the next part of our series will delve into the realms of caching and sharding, which are crucial for enhancing performance and managing data efficiently on a global scale. These advanced techniques will be pivotal in propelling MarsExpress to new heights, ensuring it can handle the demands of millions seamlessly. Join us as we continue to unravel the intricacies of system design, which is essential for any software engineer aiming to build robust, scalable systems in today’s dynamic technological landscape.
