Right-Sizing GPU and CPU Resources for Training and Inferencing Using Kubernetes

The rapid rise of AI services has created a massive demand for computing resources, making efficient management of those resources a critical challenge. While running AI workloads with Kubernetes has come a long way, optimizing scheduling based on dynamic demand continues to be an area for improvement. Many organizations face constraints related to the cost and availability of GPU clusters worldwide and often rely on the same compute clusters for inference workloads and continuous model training and fine-tuning.
AI Model Training and Model Inferencing in Kubernetes
Training typically requires far more computational power than inferencing. On the other hand, inferencing is far more frequent than training as it is used to make predictions repeatedly across many applications. Let’s explore how we can harness the best of what the cloud has to offer with advances in Kubernetes to optimize resource allocation by prioritizing workloads dynamically and efficiently based on need.
The diagram below shows the process of training versus inferencing. For training, workloads may run less frequently but with more resources needed as we essentially “teach” it how to respond to new data. Once trained, a model is deployed and will often run on GPU compute instances to provide the best results with low latency. Inferencing will thus run more frequently, but not as intensely. All the while, we may go back and retrain a model to accommodate new data or even try other models that need to be trained before deployment.
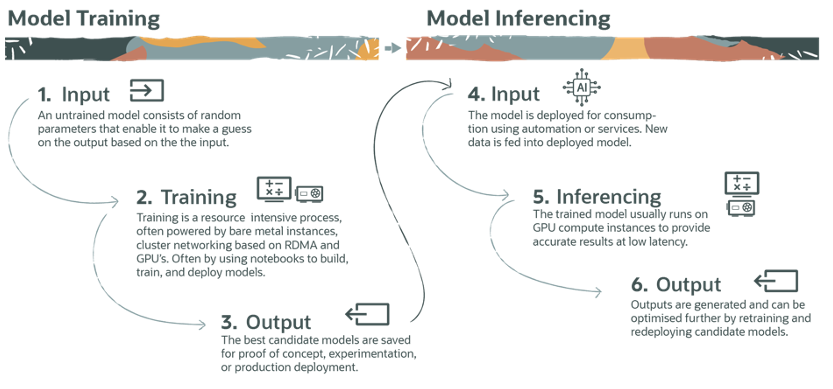
AI workloads, especially training, are like High Performance Computing (HPC) workloads. Kubernetes wasn’t designed for HPC, but because Kubernetes is open source and largely led by the community, there have been rapid innovations in this space. The need for optimization has led to the development of tools like KubeFlow and Kueue.
AI Workloads for Kubernetes
KubeFlow uses pipelines to simplify the steps in data science into logical blocks of operation and offers numerous libraries that plug into these steps so you can get up and running quickly.
Kueue provides resource “flavors” that allow it to tailor workloads to the hardware provisioning available at the time and schedule the correct workloads accordingly (there’s much more to it, of course). The community has done an outstanding job of addressing issues of scaling, efficiency, distribution, and scheduling with these tools and more.
Below is an example of how we can use Kubernetes to schedule and prioritize training and inference jobs on GPU clusters backed with Remote Direct Memory Access-- RDMA (RoCEv2). Let's create some sample code to demonstrate this concept. Note: In the code we use a fictional website, gpuconfig.com for the GPU manufacturer. Also, <gpu name> is a placeholder for the specific GPU you wish to target.
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority-<gpu name>
value: 1000000
globalDefault: false
description: "This priority class should be used for high priority <GPU NAME> GPU jobs only."
---
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: medium-priority-<gpu name>
value: 100000
globalDefault: false
description: "This priority class should be used for medium priority <GPU NAME> GPU jobs."
---
apiVersion: v1
kind: Pod
metadata:
name: high-priority-gpu-job
spec:
priorityClassName: high-priority-<gpu name>
containers:
- name: gpu-container
image: gpu/<gpu image>
command: [" <gpu vendor>-smi"]
resources:
limits:
gpuconfig.com/gpu: 1
nodeSelector:
gpu-type: <gpu name>
rdma: "true"
---
apiVersion: v1
kind: Pod
metadata:
name: medium-priority-gpu-job
spec:
priorityClassName: medium-priority-<gpu name>
containers:
- name: gpu-container
image: gpu/<gpu image>
command: [" <gpu vendor>-smi"]
resources:
limits:
gpuconfig.com/gpu: 1
nodeSelector:
gpu-type: <gpu name>
rdma: "true"
This Kubernetes configuration demonstrates how to prioritize jobs on our GPU nodes using an RDMA backbone. Let's break down the key components:
1. PriorityClasses: We've defined two priority classes for our GPU’s jobs:
high-priority-<gpu name>: For critical jobs that need immediate execution.medium-priority-<gpu name>: For jobs that are important but can wait if necessary.
2. Pod Specifications: We've created two sample pods to show how to use these priority classes:
high-priority-gpu-job: Uses thehigh-priority-<gpu name>class.medium-priority-gpu-job: Uses themedium-priority-<gpu name>class.
3. Node Selection: Both pods use nodeSelector to ensure they're scheduled on specific GPUs with RDMA:
nodeSelector:
gpu-type: <gpu name>
rdma: "true"
4. Resource Requests: Each pod requests one GPU:
resources:
limits:
gpuconfig.com/gpu: 1Kubernetes uses priority classes to determine the order in which pods are scheduled and which pods are evicted if resources are constrained. Here's an example of how you might create a CronJob that uses a high-priority class:
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: high-priority-ml-training
spec:
schedule: "0 2 * * *"
jobTemplate:
spec:
template:
metadata:
name: ml-training-job
spec:
priorityClassName: high-priority-<gpu name>
containers:
- name: ml-training
image: your-ml-image:latest
resources:
limits:
gpuconfig.com/gpu: 2
restartPolicy: OnFailure
nodeSelector:
gpu-type: <gpu name>
rdma: "true"
GPU Resource Management in Kubernetes
Below are some examples of GPU resource management in Kubernetes.
apiVersion: v1
kind: ResourceQuota
metadata:
name: gpu-quota
namespace: ml-workloads
spec:
hard:
requests.gpuconfig.com/gpu: 8
limits.gpuconfig.com/gpu: 8
---
apiVersion: v1
kind: LimitRange
metadata:
name: gpu-limits
namespace: ml-workloads
spec:
limits:
- default:
gpuconfig.com/gpu: 1
defaultRequest:
gpuconfig.com/gpu: 1
max:
gpuconfig.com/gpu: 4
min:
gpuconfig.com/gpu: 1
type: Container
---
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: gpu-burst
value: 1000000
globalDefault: false
description: "This priority class allows for burst GPU usage, but may be preempted."
---
apiVersion: v1
kind: Pod
metadata:
name: gpu-burst-job
namespace: ml-workloads
spec:
priorityClassName: gpu-burst
containers:
- name: gpu-job
image: gpu/<gpu image>
command: [" <gpu vendor>-smi"]
resources:
limits:
gpuconfig.com/gpu: 2
nodeSelector:
gpu-type: <gpu name>
In the past, it could be a challenge to know the current state of hardware to prioritize workloads, but thanks to open-source tools we now have solutions. For monitoring GPU utilization, we’re using tools like Prometheus and Grafana. Here's a sample Prometheus configuration to scrape GPU metrics:
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'gpu_gpu_exporter'
static_configs:
- targets: ['localhost:9835']And here's a simple Python script that we are using to optimize GPU allocation based on utilization metrics:
import kubernetes
from prometheus_api_client import PrometheusConnect
def get_gpu_utilization(prometheus_url, pod_name):
prom = PrometheusConnect(url=prometheus_url, disable_ssl=True)
query = f'gpu_gpu_utilization{{pod="{pod_name}"}}'
result = prom.custom_query(query)
return float(result[0]['value'][1]) if result else 0
def optimize_gpu_allocation():
kubernetes.config.load_kube_config()
v1 = kubernetes.client.CoreV1Api()
pods = v1.list_pod_for_all_namespaces(label_selector='gpu=true').items
for pod in pods:
utilization = get_gpu_utilization('http://prometheus:9090', pod.metadata.name)
if utilization < 30: # If GPU utilization is less than 30%
# Reduce GPU allocation
patch = {
"spec": {
"containers": [{
"name": pod.spec.containers[0].name,
"resources": {
"limits": {
"gpuconfig.com/gpu": "1"
}
}
}]
}
}
v1.patch_namespaced_pod(name=pod.metadata.name, namespace=pod.metadata.namespace, body=patch)
print(f"Reduced GPU allocation for pod {pod.metadata.name}")
if __name__ == "__main__":
optimize_gpu_allocation()
This script checks GPU utilization for pods and reduces allocation if utilization is low. This script is run as a function to optimize resource usage.
Leveraging Kubernetes to Manage GPU and CPU Resources
Thus, we leveraged Kubernetes with OCI Kubernetes Engine (OKE) to dynamically manage GPU and CPU resources across training and inference workloads for AI models. Specifically, we focused on right-sizing the GPU allocations with RDMA (RoCEv2) capabilities. We developed Kubernetes configurations, helm charts, including custom priority classes, node selectors, and resource quotas, to ensure optimal scheduling and resource prioritization for both high-priority and medium-priority AI tasks.RDMA (RoCEv2) capabilities. We developed Kubernetes configurations, helm charts, including custom priority classes, node selectors, and resource quotas, to ensure optimal scheduling and resource prioritization for both high-priority and medium-priority AI tasks.
By utilizing Kubernetes' flexibility, and OKE’s management capabilities on Oracle Cloud Infrastructure (OCI), we balanced the heavy compute demands of training with the lighter demands of inferencing. This ensured that resources were dynamically allocated, reducing waste while maintaining high performance for critical tasks. Additionally, we integrated monitoring tools like Prometheus to track GPU utilization and adjust allocations automatically using a Python script. This automation helped optimize performance while managing costs and availability.
In Conclusion
The solutions we outlined here apply universally across cloud and on-premises platforms using Kubernetes for AI/ML workloads. No matter the hardware, or any other compute platform, the key principles of using Kubernetes for dynamic scheduling and resource management remain the same. Kubernetes allows organizations to prioritize their workloads efficiently, optimizing their use of any available hardware resources. By using the same approach, enterprises can fine-tune their infrastructure, reduce bottlenecks, and cut down on underutilized resources, leading to more efficient and cost-effective operations.
This article was shared as part of DZone's media partnership with KubeCon + CloudNativeCon.
View the Event
