Mirror Maker v2.0

Before we start let's make some abbreviations.
- Mirror maker v1.0 -> mmv1
- Mirror maker v2.0 -> mmv2
Find the Project
Find all the stuff on this document over here. Here is what the repository contains.
- docker_kafka has instructions on how to build Kafka for Docker. Check this. Otherwise, download the Docker image from my Dockerhub.
-
Shell
xxxxxxxxxx1
1docker pull lozuwa/kafka:v2.5.0
- The mmv2 folder has yamls to deploy Kafka nodes. Use this script to deploy the Kafka nodes.
- After deploying the Kafka nodes, run another Docker container to start the mirror maker v2. Use this script.
Have questions or wanna know more? Follow me on twitter Rodrigo_Loza_L
Introduction
The new release of mirror maker introduces a lot of new features usable in disaster recovery, backup, streaming and aggregation scenarios. Before Kafka mirror maker, the Kafka replicator product form confluence allowed some of the same features. For me, I built a lot of custom code to provide mmv1 the features of mmv2. Not as dynamic or scalable but still usable.
This document presents a tutorial as detailed as possible of mmv2. Specifically, details the latest release on May 29th which is Kafka 2.5.0.
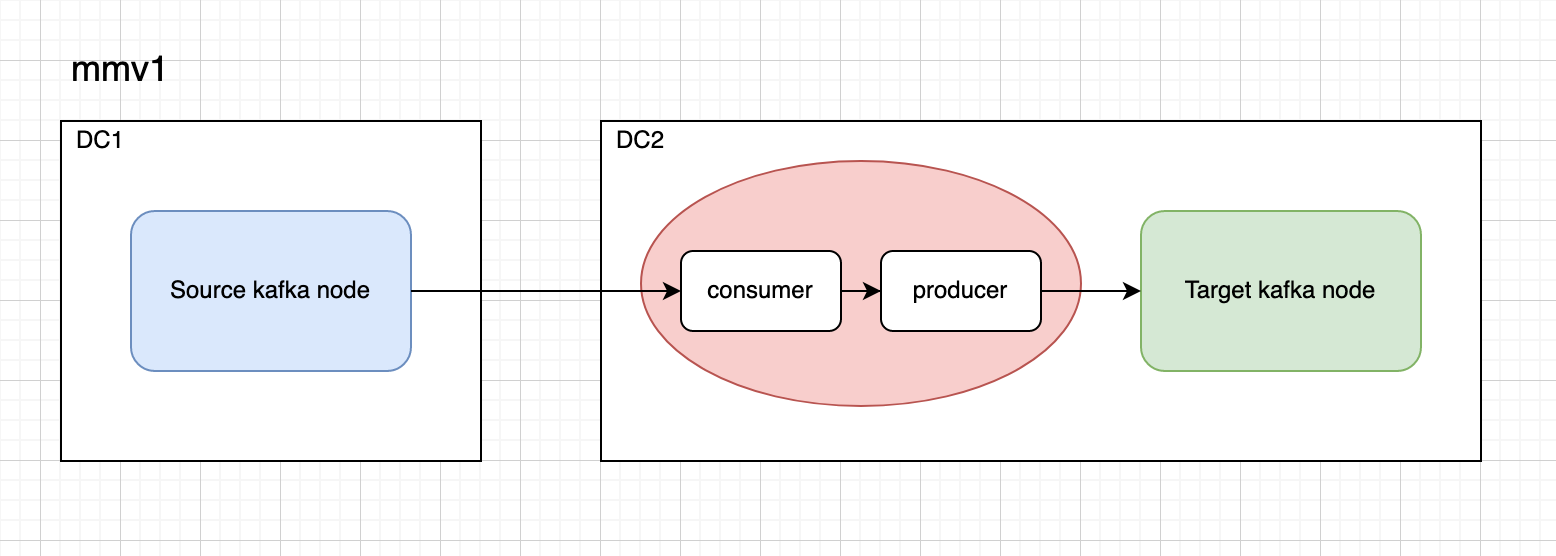
Comparison Between mmv1 and mmv2
There are a lot of differences architecture, replication policies, monitoring, etc. Here is a summary.
Mirror Maker v1.0
- Consumer/Producer architecture.
- Topic replication but configurations are not copied.
- Monitoring via consumer group id lag.
- SSL/SASL support.
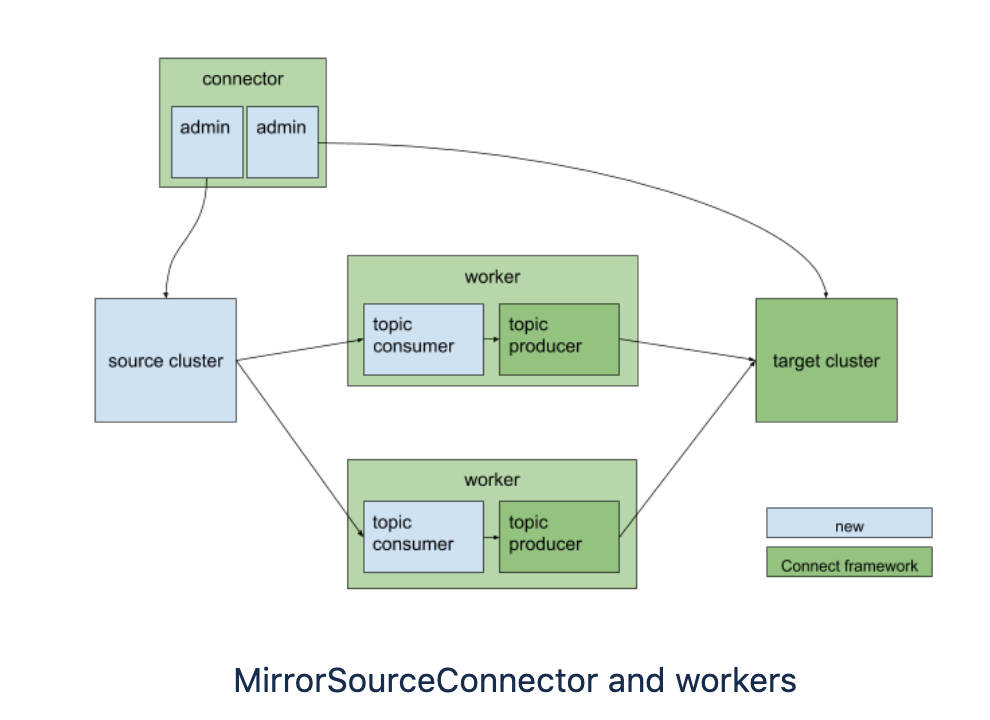
Mirror Maker v2.0
- Kafka connectors architecture.
- Checkpoints, offsets and topics replicated.
- Topics have their configurations copied.
- Monitoring via Kafka connect integration (This is still a dark place).
- SSL/SASL support.
- Multiple deployment modes.
- MM Kafka dedicated cluster
- Connect standalone
- Connectors deployed in a distributed connect cluster
Examples
Let's move onto the examples. I suggest you read the catch-ups before we start, most of these are neither documented nor explicitly detailed. Thus, these might be useful to debug problems.
Catch-ups
- Topic configurations are not immediately copied, instead the config copy job is periodic with a default of 10 minutes. Therefore, the configs are eventually copied.
- If you need a faster copy of configurations, restart the mirror maker. At start configurations are copied.
- Default replication factor for topics is 2 (hardcoded in the code). Make sure to replace it depending on your node/cluster.
- The following configurations are related to replication factor. The default value is 3. In this sense, if you are using a single node, then Exceptions will pop up. Make sure to configure them according to your cluster.
- config.storage.replication.factor
- offset.storage.replication.factor
- status.storage.replication.factor
- The following configuration are related to replication factor as well. Nonetheless, these belong to mmv2 itself and also have a default value set to 3.
- offset-syncs.topic.replication.factor
- heartbeats.topic.replication.factor
- checkpoints.topic.replication.factor
- There is an interface in mmv2 code that blacklists internal topics which follow the pattern (.internal|-internal|__.*). This is not configurable, you will have to override the method.
- Topic blacklists default to topics.blacklist = [.*[\-\.]internal, .*\.replica, __.*] Consider this value if you see your topics are not being replicated.
- Groups blacklists default to groups.blacklist = [console-consumer-.*, connect-.*, __.*] Consider this value if you see your groups, offsets are not being replicated.
- Remote topics might be tricky. The DefaultReplicationPolicy class will hardcode the value remote topic to source-cluster-alias.topic-name
- Producers must be as close as possible while consumers can be remote. This means we oftenly would like to run the mmv2 dedicated cluster as close as possible to the target DC.
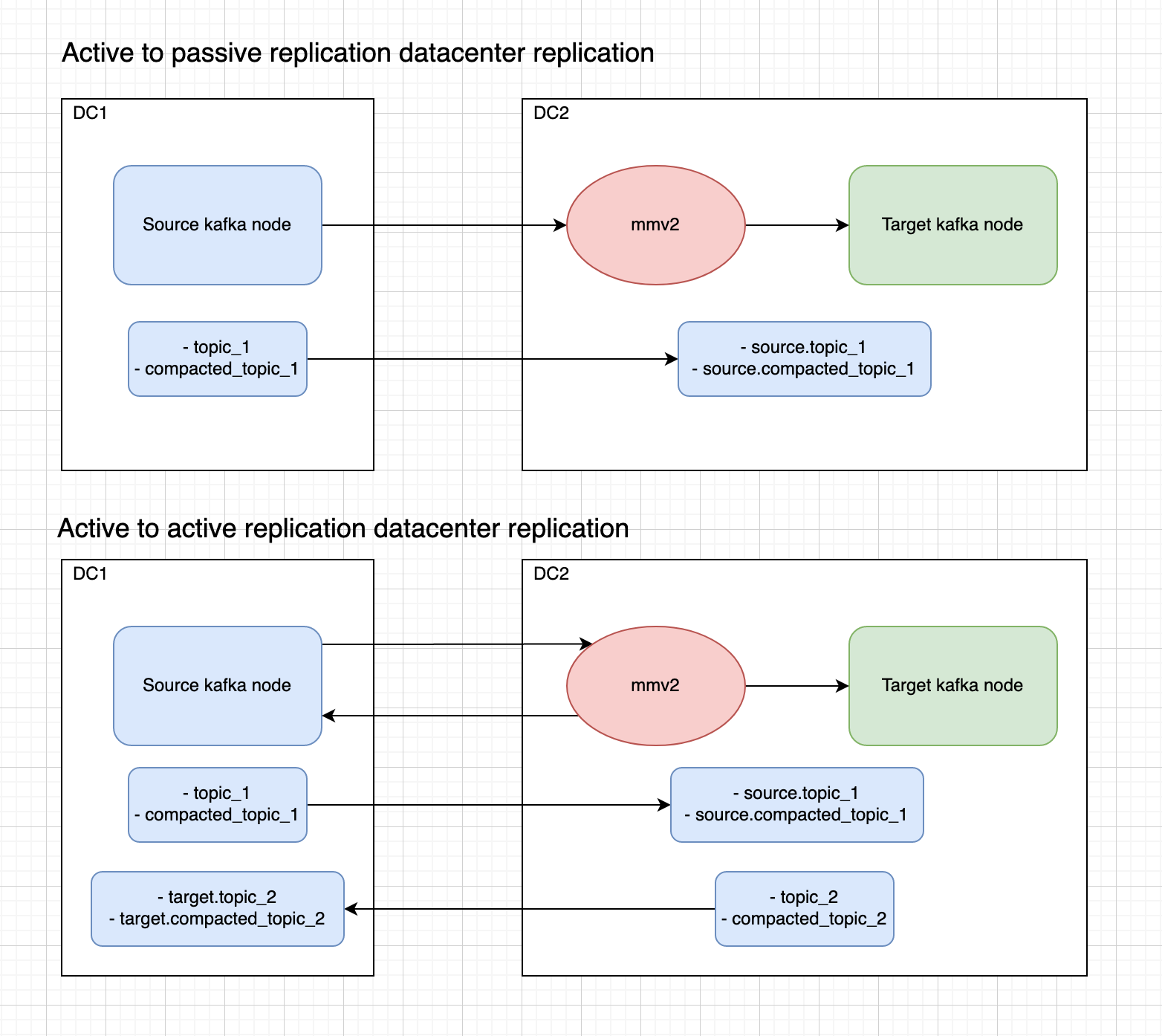
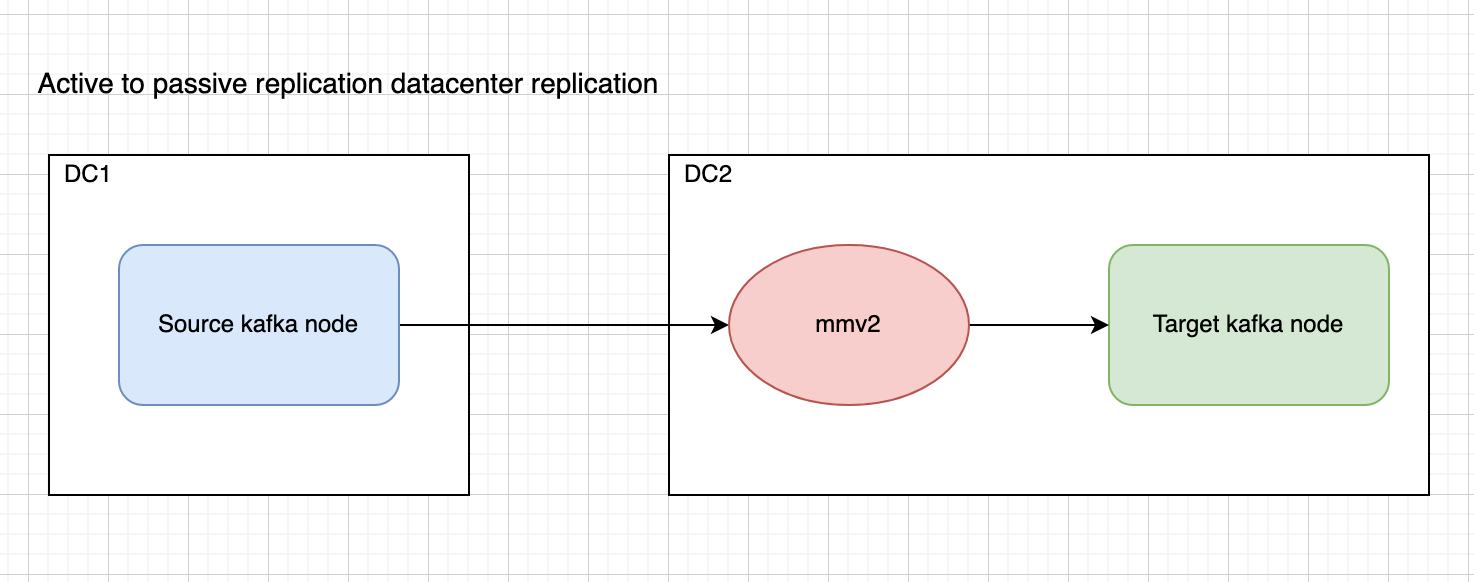
Active/Passive Datacenter Replication
Architecture
Configuration File
Create a file named mm2.properties and fill it with the following content.
x
# Kafka datacenters.
clusters = source, target
source.bootstrap.servers = kafka-source:9092
target.bootstrap.servers = kafka-target:9092
# Source and target cluster configurations.
source.config.storage.replication.factor = 1
target.config.storage.replication.factor = 1
source.offset.storage.replication.factor = 1
target.offset.storage.replication.factor = 1
source.status.storage.replication.factor = 1
target.status.storage.replication.factor = 1
source->target.enabled = true
target->source.enabled = false
# Mirror maker configurations.
offset-syncs.topic.replication.factor = 1
heartbeats.topic.replication.factor = 1
checkpoints.topic.replication.factor = 1
topics = .*
groups = .*
tasks.max = 1
replication.factor = 1
refresh.topics.enabled = true
sync.topic.configs.enabled = true
refresh.topics.interval.seconds = 30
topics.blacklist = .*[\-\.]internal, .*\.replica, __consumer_offsets
groups.blacklist = console-consumer-.*, connect-.*, __.*
# Enable heartbeats and checkpoints.
source->target.emit.heartbeats.enabled = true
source->target.emit.checkpoints.enabled = true
What's important to highlight:
- Clusters have been given explicit names. source and target respectively.
- The bootstrap string is different for each dc.
- Replication factor variables have been set to 1 since we have 1 node on each side.
- All topics and groups have been whitelisted with the exception of internal topics, replica topics and consumer offsets. Check the topics and groups blacklist variables.
- The configuration variable sync.topic.configs.enabled allows mmv2 to replicate not only the records but also the topic configurations.
- refresh.topics.interval.seconds makes the cluster check for new topics every 30 seconds. Note this does not align with the configuration copy job mentioned in the catch ups.
- Heartbeats and checkpoints are enabled from source to target. Which means a heartbeat topic will be created on each side and will be populated by mmv2. Also checkpoints will be published to a topic named mm2-offsets.source.internal; this will be useful to check for lag.
Once you have your infrastructure and configuration file setup, run the following commands on the Docker container used for mmv2:
xxxxxxxxxx
./run-kakfa-mirror-maker.sh
cd kafka/bin/
./connect-mirror-maker.sh mm2.properties
The logs are very verbose, it is hard to catch everything at first. Make sure you familiarize with Kafka connect and the initialization steps. If the following issue pops up, then verify you are not moving the jars manually at some point in your installation. Otherwise, upgrade your Kafka installation to release 2.5.0 which fixed this problem for me.
Once that mmv2 starts, a periodic log will be triggered that depicts the connectors are copying the topics, offsets and heartbeats. Check for warnings or errors as they may reflect a misconfiguration.
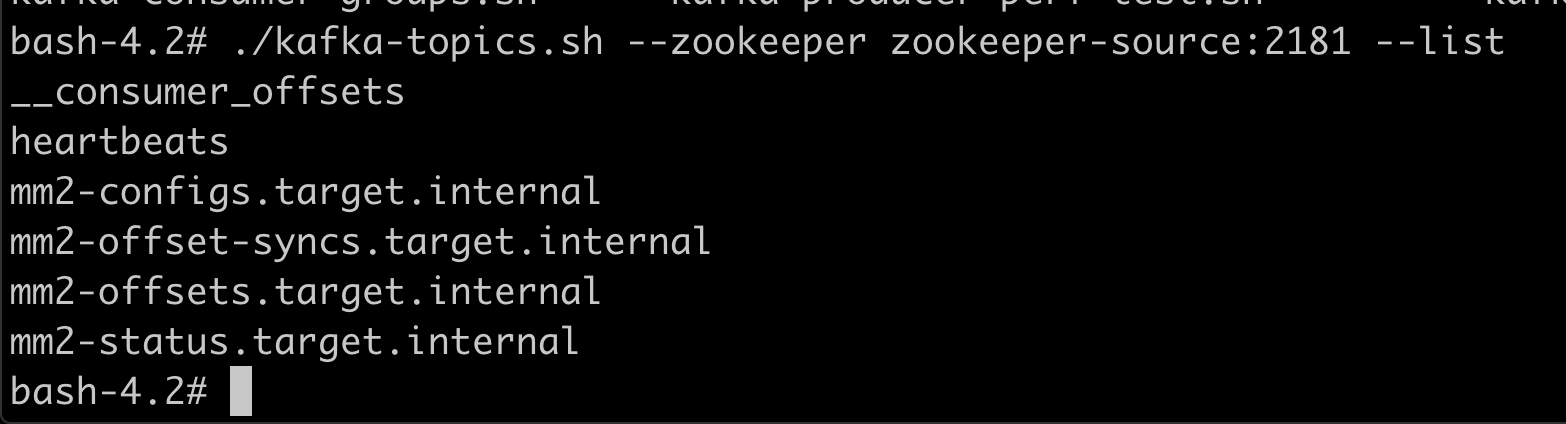
Let's make sure mmv2 has successfully connected the two Kafka nodes. For this let's list the topics on both Kafkas.
On the source cluster.
xxxxxxxxxx
./kafka-topics.sh --zookeeper zookeeper-source:2181 --list
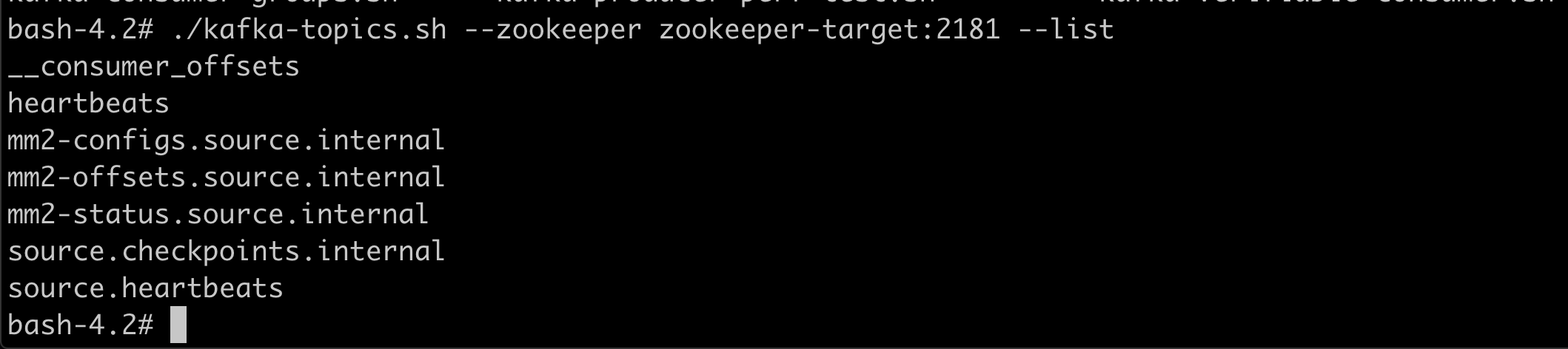
On the target cluster.
xxxxxxxxxx
./kafka-topics.sh --zookeeper zookeeper-target:2181 --list
Let's check the topic replication. Create a bunch of topics normal, compacted, etc.
x
./kafka-topics.sh --zookeeper zookeeper-source:2181 --create --partitions 1 --replication-factor 1 --topic topic_1 --config cleanup.policy=delete
./kafka-topics.sh --zookeeper zookeeper-source:2181 --create --partitions 2 --replication-factor 1 --topic topic_2 --config cleanup.policy=delete
./kafka-topics.sh --zookeeper zookeeper-source:2181 --create --partitions 5 --replication-factor 1 --topic compact_3 --config cleanup.policy=delete
./kafka-topics.sh --zookeeper zookeeper-source:2181 --create --partitions 1 --replication-factor 1 --topic compacted_topic_1 --config cleanup.policy=compact
./kafka-topics.sh --zookeeper zookeeper-source:2181 --create --partitions 1 --replication-factor 1 --topic compacted_topic_2 --config cleanup.policy=compact
The topics on the source node look as follows.
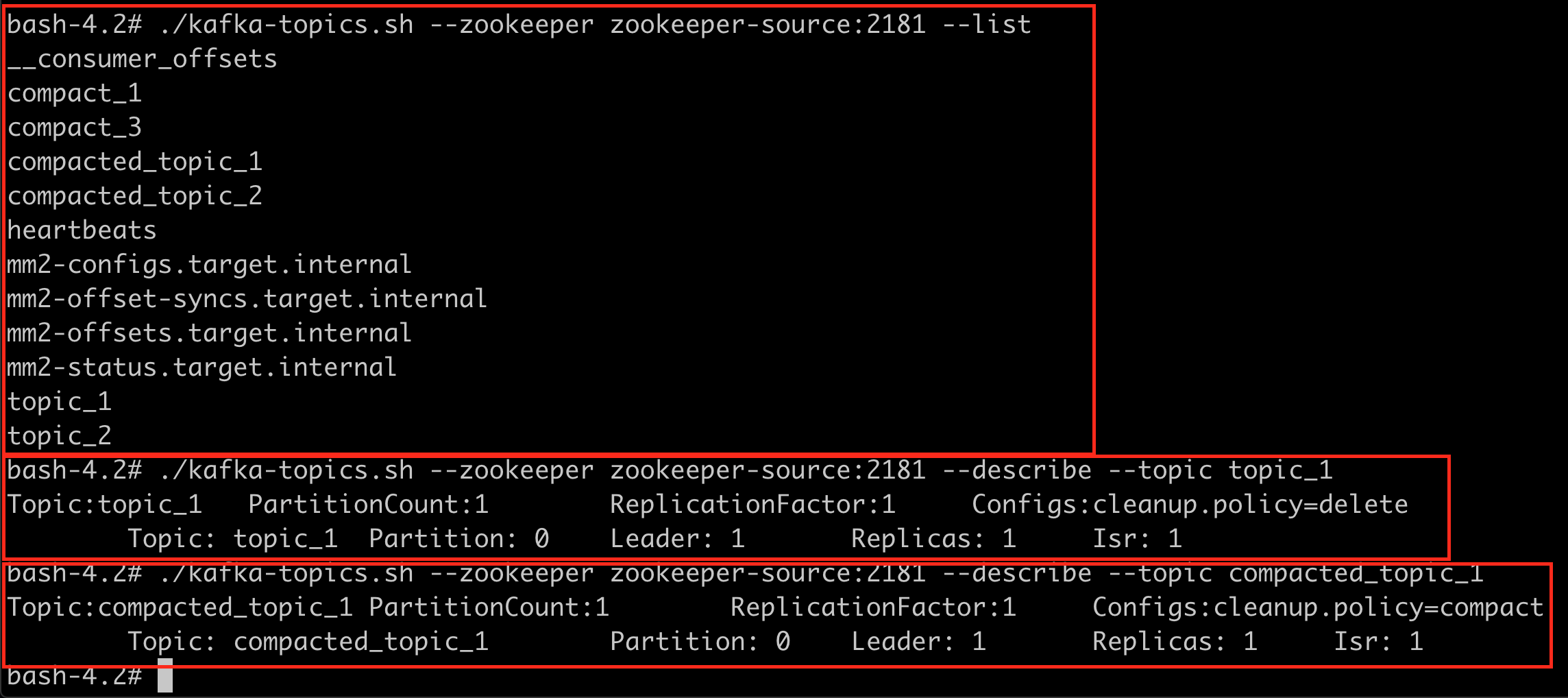
The topics on the target node look as follows.
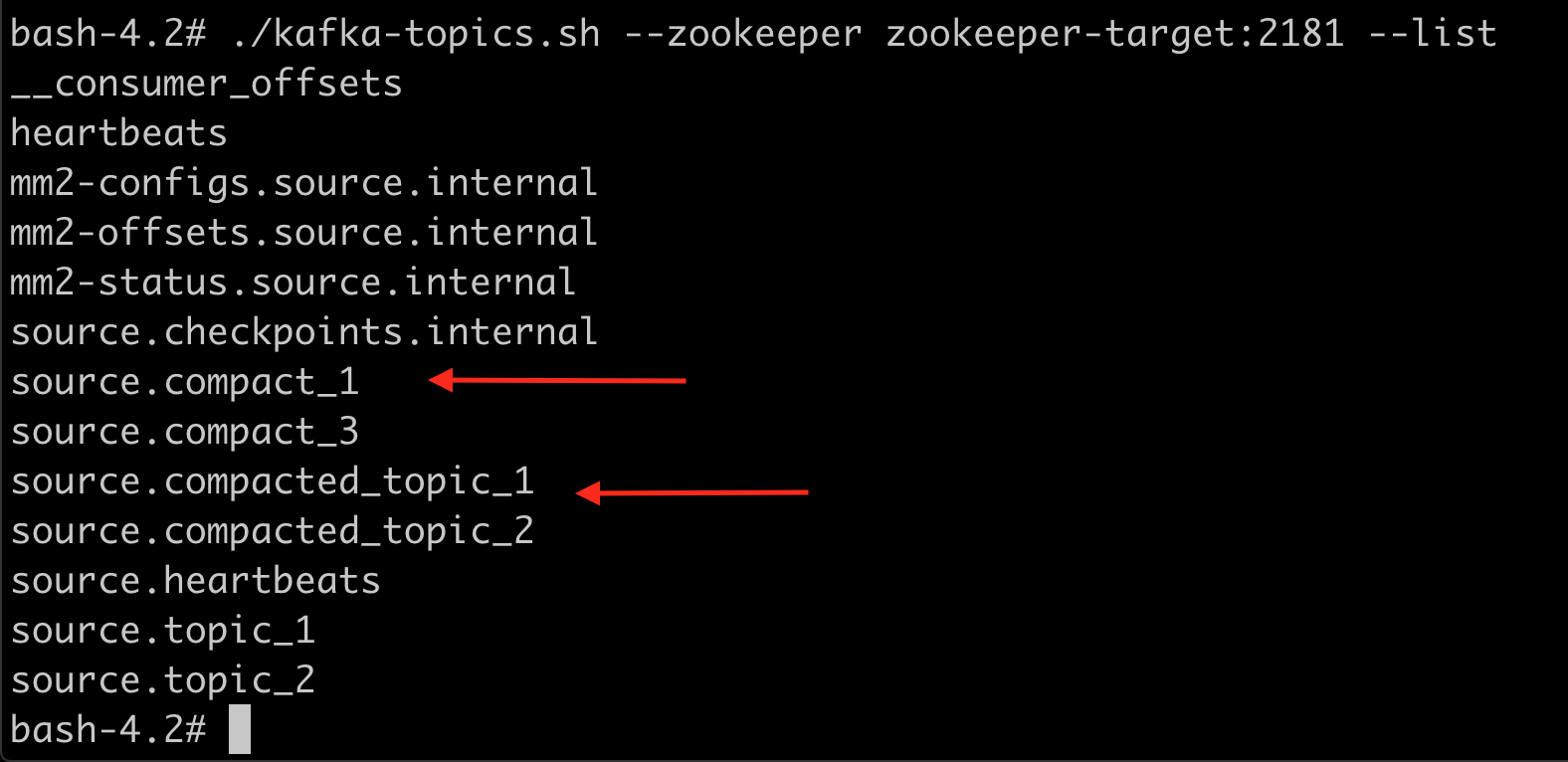
Note the topics have the alias of the cluster as a suffix. This is how mmv2 assures topics will not step into each other in an active/active replication architecture.
Let's describe the topics one by one in order to verify if the configurations have been replicated. Check the config on the compacted_topic_1 it does not have the cleanup.policy=compact Remember this is eventually replicated. If you are in a hurry, restart mmv2.

After 10 minutes the config is copied.

Active/Active Datacenter Replication
Architecture
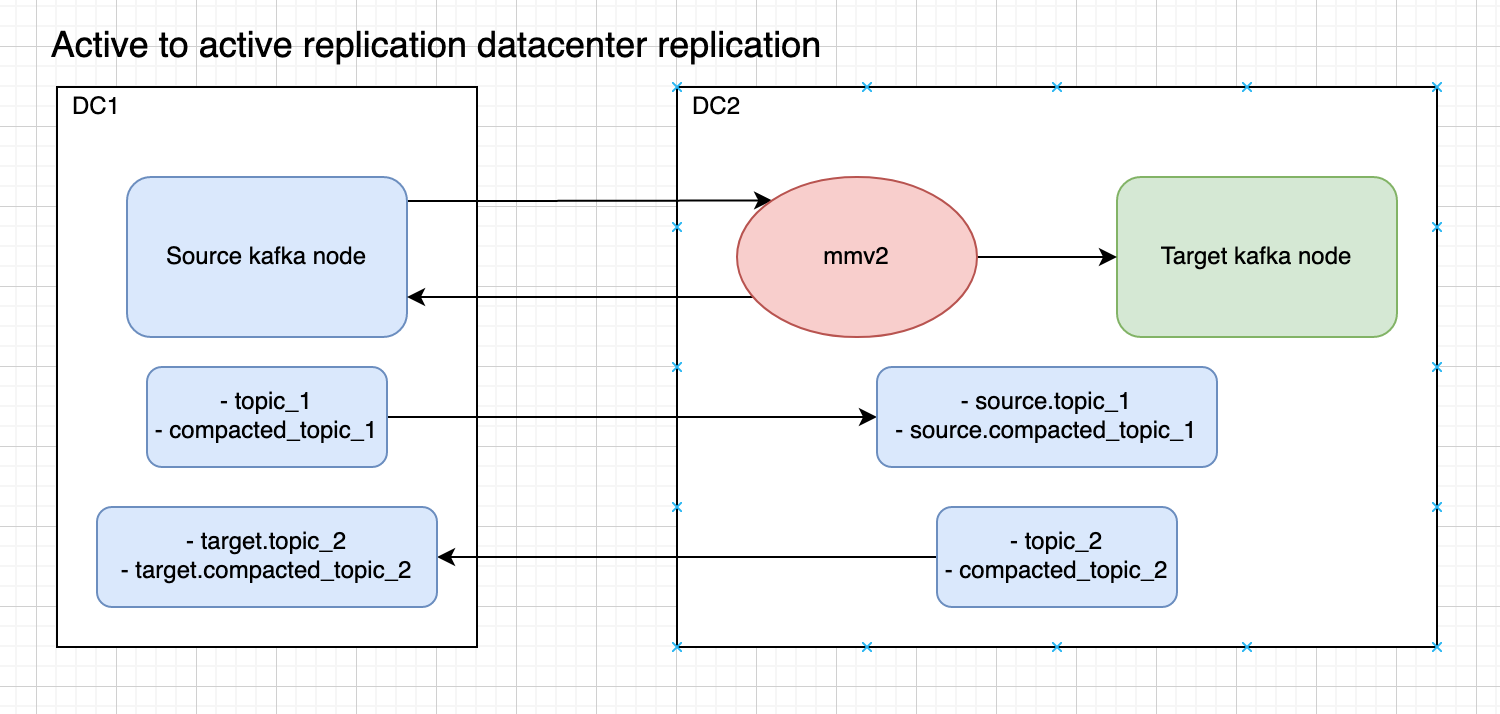
Configuration File
Create a file named mm2.properties and fill it with the following content.
x
# Kafka datacenters.
clusters = source, target
source.bootstrap.servers = kafka-source:9092
target.bootstrap.servers = kafka-target:9092
# Source and target clusters configurations.
source.config.storage.replication.factor = 1
target.config.storage.replication.factor = 1
source.offset.storage.replication.factor = 1
target.offset.storage.replication.factor = 1
source.status.storage.replication.factor = 1
target.status.storage.replication.factor = 1
source->target.enabled = true
target->source.enabled = true
# Mirror maker configurations.
offset-syncs.topic.replication.factor = 1
heartbeats.topic.replication.factor = 1
checkpoints.topic.replication.factor = 1
topics = .*
groups = .*
tasks.max = 1
replication.factor = 1
refresh.topics.enabled = true
sync.topic.configs.enabled = true
refresh.topics.interval.seconds = 10
topics.blacklist = .*[\-\.]internal, .*\.replica, __consumer_offsets
groups.blacklist = console-consumer-.*, connect-.*, __.*
# Enable heartbeats and checkpoints.
source->target.emit.heartbeats.enabled = true
source->target.emit.checkpoints.enabled = true
What's important to highlight:
- Same as the previous property file. But active to active replication is enabled.
Once you have your infrastructure and configuration file setup, run the following commands on the Docker container used for mmv2:
./run-kakfa-mirror-maker.sh
cd kafka/bin/
./connect-mirror-maker.sh /data/active-to-active-mm2.properties
Check the topics on the source cluster.
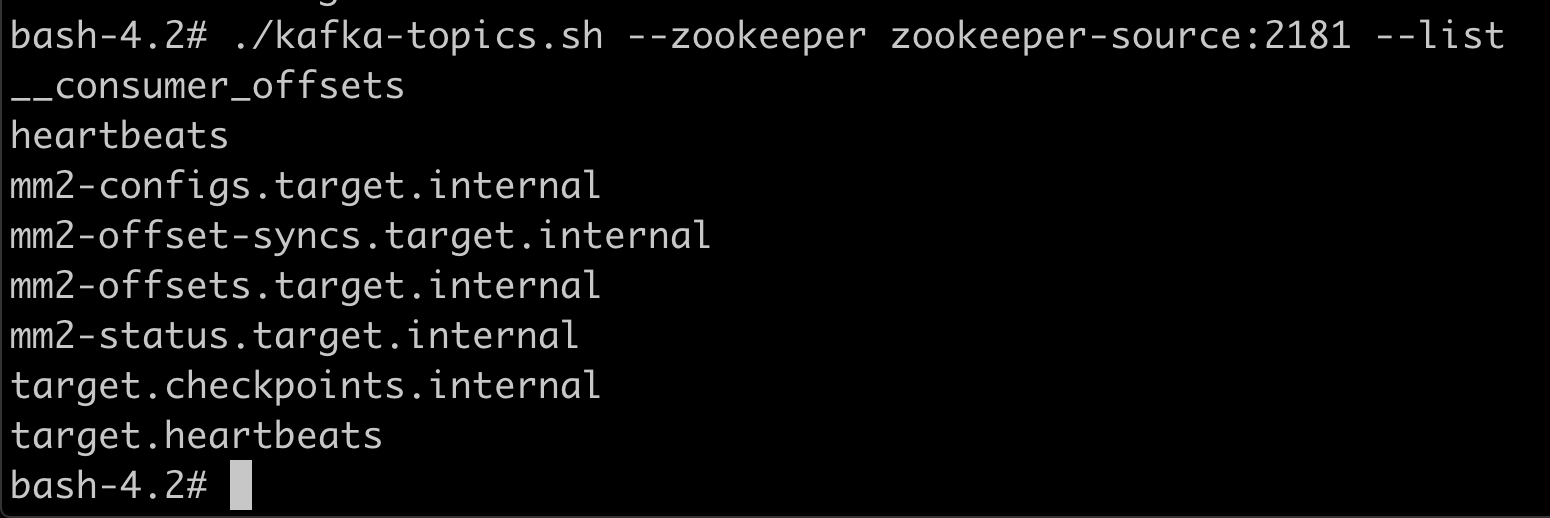
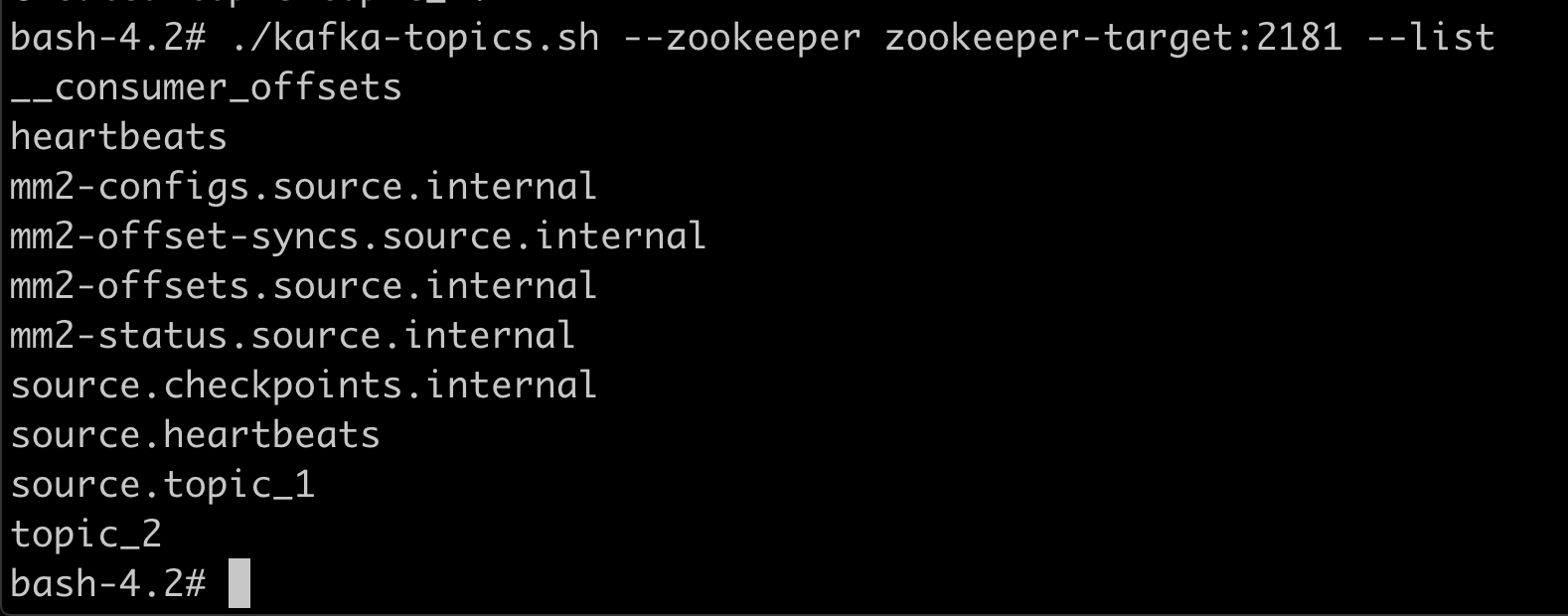
Check the topics on the target cluster.

Let's create some topics. Each on a different Kafka node. Note the zookeeper is different on each command.
xxxxxxxxxx
./kafka-topics.sh --zookeeper zookeeper-source:2181 --create --partitions 1 --replication-factor 1 --topic topic_1
./kafka-topics.sh --zookeeper zookeeper-target:2181 --create --partitions 1 --replication-factor 1 --topic topic_2
Let's list the topics.
On the source cluster. Check the local topics and one replicated from the target cluster.
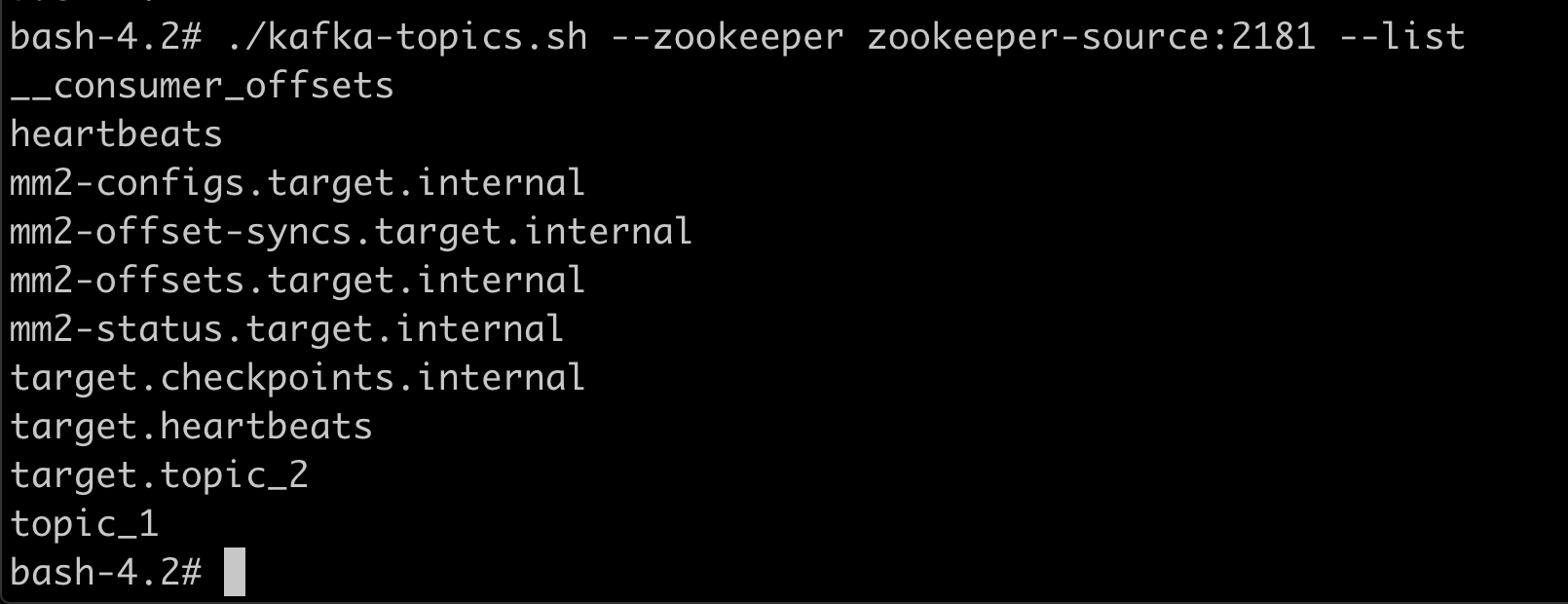
On the target cluster. Check the local topics and one replicated from the source cluster.
That is it for this post. Check the next one for more examples such as aggregation. Also I'll show you how to create your own replication policy using Java.
